Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
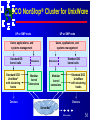
(c) Raj Architecture Alternatives for Scalable Single System Image Clusters Rajkumar Buyya, Monash University, Melbourne, Australia. [email protected] http://www.dgs.monash.edu.au/~rajkumar 1 (c) Raj Agenda Cluster ? Enabling Tech. & Motivations Cluster Architecture What Single System Image (SSI) ? Levels of SSI ? Cluster Middleware Vs. Underware Representative SSI implementations Pros and Cons of SSI at difference levels Ann.--IEEE Task Force on Cluster Computing Resources and Conclusions 2 Need of more Computing Power: Grand Challenge Applications (c) Raj Solving technology problems using computer modeling, simulation and analysis Geographic Information Systems Life Sciences Aerospace Mechanical Design & Analysis (CAD/CAM) 3 Competing Computer Architectures (c) Raj Vector Computers (VC) ---proprietary system – provided the breakthrough needed for the emergence of computational science, buy they were only a partial answer. Massively Parallel Processors (MPP)-proprietary system – high cost and a low performance/price ratio. Symmetric Multiprocessors (SMP) – suffers from scalability Distributed Systems – difficult to use and hard to extract parallel performance. Clusters -- gaining popularity – High Performance Computing---Commodity Supercomputing – High Availability Computing ---Mission Critical Applications 4 Technology Trend... (c) Raj Performance of PC/Workstations components has almost reached performance of those used in supercomputers… – Microprocessors (50% to 100% per year) – Networks (Gigabit ..) – Operating Systems – Programming environment – Applications Rate of performance improvements of commodity components is too high. 5 (c) Raj Technology Trend 6 The Need for Alternative Supercomputing Resources (c) Raj Cannot afford to buy “Big Iron” machines – due to their high cost and short life span. – cut-down of funding – don’t “fit” better into today's funding model. – …. Paradox: time required to develop a parallel application for solving GCA is equal to: – half Life of Parallel Supercomputers. 7 (c) Raj Clusters are bestalternative! Supercomputing-class commodity components are available They “fit” very well with today’s/future funding model. Can leverage upon future technological advances – VLSI, CPUs, Networks, Disk, Memory, Cache, OS, programming tools, applications,... 8 Best of both Worlds! (c) Raj High on this) Performance Computing (talk focused – parallel computers/supercomputer-class workstation cluster – dependable parallel computers High Availability Computing – mission-critical systems – fault-tolerant computing 9 (c) Raj What is a cluster? A cluster is a type of parallel or distributed processing system, which consists of a collection of interconnected stand-alone computers cooperatively working together as a single, integrated computing resource. A typical cluster: – Network: Faster, closer connection than a typical network (LAN) – Low latency communication protocols – Looser connection than SMP 10 So What’s So Different about Clusters? (c) Raj Commodity Parts? Communications Packaging? Incremental Scalability? Independent Failure? Intelligent Network Interfaces? Complete System on every node – virtual memory – scheduler – files –… Nodes can be used individually or combined... 11 Clustering of Computers for Collective Computating 1960 1990 1995+ (c) Raj Computer Food Chain (Now and Future) Demise of Mainframes, Supercomputers, & MPPs 13 (c) Raj Cluster Configuration..1 Dedicated Cluster 14 (c) Raj Cluster Configuration..2 Enterprise Clusters (use JMS like Codine) Shared Pool of Computing Resources: Processors, Memory, Disks Interconnect Guarantee at least one workstation to many individuals (when active) Deliver large % of collective resources to few individuals at any one time 15 Windows of Opportunities (c) Raj MPP/DSM: – Compute across multiple systems: parallel. Network RAM: – Idle memory in other nodes. Page across other nodes idle memory Software RAID: – file system supporting parallel I/O and reliability, mass-storage. Multi-path Communication: – Communicate across multiple networks: Ethernet, ATM, Myrinet 16 (c) Raj Cluster Computer Architecture 17 Major issues in cluster design (c) Raj Size Scalability (physical & application) Enhanced Availability (failure management) Single System Image (look-and-feel of one system) Fast Communication (networks & protocols) Load Balancing (CPU, Net, Memory, Disk) Security and Encryption (clusters of clusters) Distributed Environment (Social issues) Manageability (admin. And control) Programmability (simple API if required) Applicability (cluster-aware and non-aware app.) 18 (c) Raj Cluster Middleware and Single System Image 19 (c) Raj A typical Cluster Computing Environment Application PVM / MPI/ RSH ??? Hardware/OS 20 CC should support (c) Raj Multi-user, time-sharing environments Nodes with different CPU speeds and memory sizes (heterogeneous configuration) Many processes, with unpredictable requirements Unlike SMP: insufficient “bonds” between nodes – Each computer operates independently 21 (c) Raj The missing link is provide by cluster middleware/underware Application PVM / MPI/ RSH Middleware or Underware Hardware/OS 22 SSI Clusters--SMP services on a CC (c) Raj “Pool Together” the “Cluster-Wide” resources Adaptive resource usage for better performance Ease of use - almost like SMP Scalable configurations - by decentralized control Result: HPC/HAC at PC/Workstation prices 23 What is Cluster Middleware ? (c) Raj An interface between between use applications and cluster hardware and OS platform. Middleware packages support each other at the management, programming, and implementation levels. Middleware Layers: – SSI Layer – Availability Layer: It enables the cluster services of • Checkpointing, Automatic Failover, recovery from failure, • fault-tolerant operating among all cluster nodes. 24 (c) Raj Middleware Design Goals Complete Transparency (Manageability) – Lets the see a single cluster system.. • Single entry point, ftp, telnet, software loading... Scalable Performance – Easy growth of cluster • no change of API & automatic load distribution. Enhanced Availability – Automatic Recovery from failures • Employ checkpointing & fault tolerant technologies – Handle consistency of data when replicated.. 25 What is Single System Image (SSI) ? (c) Raj A single system image is the illusion, created by software or hardware, that presents a collection of resources as one, more powerful resource. SSI makes the cluster appear like a single machine to the user, to applications, and to the network. A cluster without a SSI is not a cluster 26 Benefits of Single System Image (c) Raj Usage of system resources transparently Transparent process migration and load balancing across nodes. Improved reliability and higher availability Improved system response time and performance Simplified system management Reduction in the risk of operator errors User need not be aware of the underlying system architecture to use these machines effectively 27 Desired SSI Services (c) Raj Single Entry Point – telnet cluster.my_institute.edu – telnet node1.cluster. institute.edu Single File Hierarchy: xFS, AFS, Solaris MC Proxy Single Control Point: Management from single GUI Single virtual networking Single memory space - Network RAM / DSM Single Job Management: Glunix, Codine, LSF Single User Interface: Like workstation/PC windowing environment (CDE in Solaris/NT), may it can use Web technology 28 (c) Raj Availability Support Functions Single I/O Space (SIO): – any node can access any peripheral or disk devices without the knowledge of physical location. Single Process Space (SPS) – Any process on any node create process with cluster wide process wide and they communicate through signal, pipes, etc, as if they are one a single node. Checkpointing and Process Migration. – Saves the process state and intermediate results in memory to disk to support rollback recovery when node fails. PM for Load balancing... 29 (c) Raj Scalability Vs. Single System Image UP 30 SSI Levels/How do we implement SSI ? (c) Raj It is a computer science notion of levels of abstractions (house is at a higher level of abstraction than walls, ceilings, and floors). Application and Subsystem Level Operating System Kernel Level Hardware Level 31 SSI Characteristics (c) Raj 1. Every SSI has a boundary 2. Single system support can exist at different levels within a system, one able to be build on another 32 SSI Boundaries -- an applications SSI boundary (c) Raj Batch System SSI Boundary Source: In search of clusters 33 SSI via OS path! (c) Raj 1. Build as a layer on top of the existing OS – Benefits: makes the system quickly portable, tracks vendor software upgrades, and reduces development time. – i.e. new systems can be built quickly by mapping new services onto the functionality provided by the layer beneath. Eg: Glunix 2. Build SSI at kernel level, True Cluster OS – Good, but Can’t leverage of OS improvements by vendor – E.g. Unixware, Solaris-MC, and MOSIX 34 SSI Representative Systems (c) Raj OS level SSI – SCO NSC UnixWare – Solaris-MC – MOSIX, …. Middleware level SSI – PVM, TreadMark (DSM), Glunix, Condor, Codine, Nimrod, …. Application level SSI – PARMON, Parallel Oracle, ... 35 (c) Raj SCO NonStop® Cluster for UnixWare UP or SMP node UP or SMP node Users, applications, and systems management Standard OS kernel calls Standard SCO UnixWare® with clustering hooks Extensions Modular kernel extensions Users, applications, and systems management Extensions Standard OS kernel calls Standard SCO UnixWare with clustering hooks Modular kernel extensions Devices Devices ServerNet™ Other nodes 36 How does NonStop Clusters Work? (c) Raj Modular Extensions and Hooks to Provide: – – – – – – – – – – – – Single Clusterwide Filesystem view Transparent Clusterwide device access Transparent swap space sharing Transparent Clusterwide IPC High Performance Internode Communications Transparent Clusterwide Processes, migration,etc. Node down cleanup and resource failover Transparent Clusterwide parallel TCP/IP networking Application Availability Clusterwide Membership and Cluster timesync Cluster System Administration Load Leveling 37 Solaris-MC: Solaris for MultiComputers (c) Raj Applications System call interface Network File system C++ Processes Solaris MC Other nodes global file system globalized process manageme nt globalized networking and I/O Object framework Object invocations Existing Solaris 2.5 kernel Kernel Solaris MC Architecture 38 Solaris MC components (c) Raj Applications System call interface Network File system C++ Processes Object and communication support High availability support PXFS global distributed file system Process mangement Networking Solaris MC Object framework Object invocations Existing Solaris 2.5 kernel Kernel Solaris MC Architecture Other nodes 39 (c) Raj Multicomputer OS for UNIX (MOSIX) An OS module (layer) that provides the applications with the illusion of working on a single system Remote operations are performed like local operations Transparent to the application - user interface unchanged Application PVM / MPI / RSH Hardware/OS 40 Main tool (c) Raj Preemptive process migration that can migrate--->any process, anywhere, anytime Supervised by distributed algorithms that respond on-line to global resource availability - transparently Load-balancing - migrate process from overloaded to under-loaded nodes Memory ushering - migrate processes from a node that has exhausted its memory, to prevent paging/swapping 41 MOSIX for Linux at HUJI (c) Raj A scalable cluster configuration: – 50 Pentium-II 300 MHz – 38 Pentium-Pro 200 MHz (some are SMPs) – 16 Pentium-II 400 MHz (some are SMPs) Over 12 GB cluster-wide RAM Connected by the Myrinet 2.56 G.b/s LAN Runs Red-Hat 6.0, based on Kernel 2.2.7 Upgrade: HW with Intel, SW with Linux Download MOSIX: – http://www.mosix.cs.huji.ac.il/ 42 (c) Raj Nimrod - A Job Management System http://www.dgs.monash.edu.au/~davida/nimrod.html 43 (c) Raj Job processing with Nimrod 44 (c) Raj Nimrod Architecture 45 PARMON: A Cluster Monitoring Tool (c) Raj PARMON Client on JVM PARMON Server on each node parmon parmond PARMON High-Speed Switch 46 (c) Raj Resource Utilization at a Glance 47 (c) Raj Relationship Among Middleware Modules 48 (c) Raj Globalised Cluster Storage Single I/O Space and Design Issues Reference: Designing SSI Clusters with Hierarchical Checkpointing and Single I/O Space”, IEEE Concurrency, March, 1999 by K. Hwang, H. Jin et.al 49 (c) Raj Clusters with & without Single I/O Space Users Users Single I/O Space Services Without Single I/O Space With Single I/O Space Services 50 Benefits of Single I/O Space (c) Raj Eliminate the gap between accessing local disk(s) and remote disks Support persistent programming paradigm Allow striping on remote disks, accelerate parallel I/O operations Facilitate the implementation of distributed checkpointing and recovery schemes 51 Single I/O Space Design Issues (c) Raj Integrated I/O Space Addressing and Mapping Mechanisms Data movement procedures 52 Integrated I/O Space (c) Raj LD1 LD2 ... ... D11 D12 D21 D22 D1t D2t ... Sequential addresses LDn ... Dn1 Dn2 B11 B12 SD1 ... ... B21 B22 SD2 ... Dnt Bm1 Bm2 SDm ... B1k B2k P1 . . . Local Disks, (RADD Space) Shared RAIDs, (NASD Space) Bmk Peripherals (NAP Space) Ph 53 Addressing and Mapping (c) Raj User Applications Name Agent I/O Agent Disk/RAID/ NAP Mapper I/O Agent RADD Block Mover I/O Agent I/O Agent NASD NAP User-level Middleware plus some Modified OS System Calls 54 Data Movement Procedures (c) Raj User Application I/O Agent Node 1 Block Mover Request Data Block A Node 2 I/O Agent LD2 or SDi LD1 User Application I/O Agent of the NASD Node 1 A Node 2 Block Mover A I/O Agent LD2 or SDi LD1 of the NASD A 55 (c) Raj Adoption of the Approach 56 Summary (c) Raj We have discussed Cluster Enabling Technologies Architecture & its Components Cluster Middleware Single System Image Representative SSI Tools 57 (c) Raj Conclusions Remarks Clusters are promising.. Solve parallel processing paradox Offer incremental growth and matches with funding pattern New trends in hardware and software technologies are likely to make clusters more promising and fill SSI gap..so that Clusters based supercomputers can be seen everywhere! 58 Breaking High Performance Computing Barriers (c) Raj G F L O P S 2100 2100 2100 2100 2100 2100 2100 2100 2100 Single Processor Shared Memory Local Parallel Cluster Global Parallel Cluster 59 (c) Raj Announcement: formation of IEEE Task Force on Cluster Computing (TFCC) http://www.dgs.monash.edu.au/~rajkumar/tfcc/ http://www.dcs.port.ac.uk/~mab/tfcc/ 60 (c) Raj Well, Read my book for…. Thank You ... ? http://www.dgs.monash.edu.au/~rajkumar/c luster/ 61 (c) Raj Thank You ... ? 62 (c) Raj Appendix Pointers to Literature on Cluster Computing 63 Reading Resources..1a Internet & WWW (c) Raj – Computer Architecture: • http://www.cs.wisc.edu/~arch/www/ – PFS & Parallel I/O • http://www.cs.dartmouth.edu/pario/ – Linux Parallel Procesing • http://yara.ecn.purdue.edu/~pplinux/Sites/ – DSMs • http://www.cs.umd.edu/~keleher/dsm.html 64 Reading Resources..1b Internet & WWW (c) Raj – Solaris-MC • http://www.sunlabs.com/research/solaris-mc – Microprocessors: Recent Advances • http://www.microprocessor.sscc.ru – Beowulf: • http://www.beowulf.org – MOSIX • http://www.mosix.cs.huji.ac.il/ 65 (c) Raj Reading Resources..2 Papers – A Case of NOW, IEEE Micro, Feb’95 • by Anderson, Culler, Paterson – Designing SSI Clusters with Hierarchical Checkpointing and Single I/O Space”, IEEE Concurrency, March, 1999 • by K. Hwang, H. Jin et.al – Cluster Computing: The Commodity Supercomputing, Journal of Software Practice and Experience, June 1999 • by Mark Baker & Rajkumar Buyya – Implementing a Full Single System Image UnixWare Cluster: Middleware vs. Underware • Bruce Walker and Douglas Steel (SCO NSC Unixware) • http://www.dgs.monash.edu.au/~rajkumar/pdpta99/ 66 (c) Raj Reading Resources..3 Books – In Search of Cluster • by G.Pfister, Prentice Hall (2ed), 98 – High Performance Cluster Computing • Volume1: Architectures and Systems • Volume2: Programming and Applications – Edited by Rajkumar Buyya, Prentice Hall, 1999. – Scalable Parallel Computing • by K Hwang & Z Xu, McGraw Hill,98 67