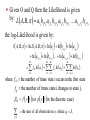Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Introduction to Hidden Markov
Models
Wang Rui
CAD&CG state key lab
2004-5-26
Outline
Example ---- Video Texture
Markov Chains
Hidden Markov Models
Example ---- Motion Texture
Example ---- Video Texture
Problem statement
video clip
video texture
The approach
How do we find good transitions?
Finding good transitions
Compute L2 distance Di, j between all frames
vs.
frame i
frame j
Similar frames make good transitions
Fish Tank
Mathematic model of Video Texture
A sequence of random variables
{ADEABEDADBCAD}
A sequence of random variables
{BDACBDCACDBCADCBADCA}
Mathematic
Markov Model
Model
The future is independent of the
past and given by the present.
Markov Property
Formal definition
– Let X={Xn}n=0…N be a sequence of random
variables taking values sk N Iff
P(Xm=sm|X0=s0,…,Xm-1=sm-1) = P(Xm=sm| Xm-1=sm-1)
then the X fulfills Markov property
Informal definition
– The future is independent of the past given the
present.
History
Markov chain theory developed around 1900.
Hidden Markov Models developed in late 1960’s.
Used extensively in speech recognition in 1960-70.
Introduced to computer science in 1989.
Applications
Bioinformatics.
Signal Processing
Data analysis and Pattern recognition
Markov Chain
A Markov chain is specified by
– A state space S = { s1, s2..., sn }
– An initial distribution a0
– A transition matrix A
Where A(n)ij= aij = P(qt=sj|qt-1=si)
Graphical Representation
as a directed graph where
– Vertices represent states
– Edges represent transitions with positive
probability
Probability Axioms
Marginal Probability – sum the joint probability
Conditional Probability
Calculating with Markov chains
Probability of an observation sequence:
– Let X={xt}Lt=0 be an observation sequence from
the Markov chain {S, a0, A}
Motivation of Hidden Markov Models
Hidden states
The state of the entity we want to model is often not
observable:
– The state is then said to be hidden.
Observables
– Sometimes we can instead observe the state of
entities influenced by the hidden state.
A system can be modeled by an HMM if:
– The sequence of hidden states is Markov
– The sequence of observations are independent (or
Markov) given the hidden
Hidden Markov Model
Definition
– Set of states S = { s1, s2..., sN }
– Observation symbols
V = { v1, v2, …, vM }
– Transition probabilities A between any two states
aij = P(qt=sj|qt-1=si)
– Emission probabilities B within each state
bj(Ot) = P( Ot=vj| qt = sj)
– Start probabilities = {a0}
Use = (A, B, ) to indicate the parameter set of the
model.
Generating a sequence by the
model
Given a HMM, we can generate a sequence of length n as
follows:
1.
2.
3.
4.
Start at state q1 according to prob a0t1
Emit letter o1 according to prob et1(o1)
Go to state q2 according to prob at1t2
… until emitting yn
1
1
a02
0
1
…
1
…
2
2
2
2
…
…
…
N
N
N
K
o1
o2
o3
…
…
N
b2(o1)
on
Example
Calculating with Hidden Markov
Model
Consider one such fixed state sequence
Q = q1 q2… qT
The observation sequence O for the Q is
T
P(O | Q, ) P(Ot | qt , )
t 1
bq1 (O1 ) bq2 (O2 ) bqT (OT )
The probability of such a state sequence Q can be written
as
P(Q | ) a0 q1 aq1q2 aq2q3 aqT 1qT
The probability that O and Q occur simultaneously,
is simply the product of the above two terms, i.e.,
P(O, Q | ) P(O | Q, ) P(Q | )
P(O, Q | ) a0 q1 bq1 (O1 )aq1q2 bq2 (O2 )aq2q3 aqT 1qT bqT (OT )
Example
The three main questions on
HMMs
1. Evaluation
GIVEN
FIND
a HMM (S, V, A, B, ), and a sequence O,
Prob[ y | M ]
2. Decoding
GIVEN
FIND
a HMM (S, V, A, B, ), and a sequence O,
the sequence Q of states that maximizes P(O, Q | )
3. Learning
GIVEN a HMM (S, V, A, B, ), with unspecified
transition/emission probs and a sequence Q,
FIND
parameters = (ei(.), aij) that maximize P[x|]
Evaluation
Find the likelihood a sequence is generated by
the model
A straight way
The probability of O is obtained by summing all
possible state sequences q giving
P(O | ) P(O | Q, ) P(Q | )
all Q
q1 , q2 ,qT
Complexity is O(NT)
Calculations is unfeasible
b (O1 )aq1q2 bq2 (O2 )aq2 q3 aqT 1qT bqT (OT )
q1 q1
The Forward Algorithm
A more elaborate algorithm
– The Forward Algorithm
0
a02
a0n
2 (1) [ 1 (i )ai1 ]b1 (O2 )
i 1
1
1
…
1
2
2
…
2
… an1
…
…
N
N
N
K
o1
o2
o3
1
a01
a11
N
2
a21
N
P(O1O2 | ) 2 (i )
i 1
…
…
N
on
N
P(O | ) T (i )
i 1
The Forward Algorithm
The Forward variable
t (i) P(O1O2 Ot , qt Si | )
We can compute α(i) for all N, i,
Initialization:
α1(i) = aibi(O1)
Iteration:
N
i = 1…N
t 1 (i ) [ t (i )aij ]b j (Ot 1 )
t 1T 1
i 1
1
1
…
1
2
2
…
2
… an1
…
…
N
N
N
K
o1
o2
o3
1
Termination:
a01
N
P(O | ) T (i )
i 1
0
a02
a0n
a11
2
a21
…
…
N
on
The Backward Algorithm
The backward variable
t (i) P(Ot 1Ot 2 OT | qt Si , )
Similar, we can compute backward variable for all N, i,
Initialization:
βT(i) = 1,
i = 1…N
Iteration: N
t (i) aijb j (Ot 1 ) t 1 ( j )
t T 1, T 2,,1,1 i N
j 1
Termination:
N
0
a02
a0n
P(O | ) a0 j b1 (O1 ) 1 ( j )
j 1
1
1
…
1
2
2
…
2
… an1
…
…
N
N
N
K
o1
o2
o3
1
a01
a11
2
a21
…
…
N
on
Consider
Thus P (qT
T i P(O1O2 OT , qT S i| )
P(O, qT Si )
T iT
S i O)
P(O)
T iT
i
P (O, qt Si )
Also P(qt Si O)
P (O)
P (O1O2 Ot , qt Sit , Ot 1Ot 2 OT )
P (O)
P (O1O2 Ot , qt Si )P(Ot 1Ot 2 OT | O1O2 Ot , qt Si )
P (O)
Forward, fk(i)
Backward, bk(i)
P (O1O2 Ot , qt Si )P(Ot 1Ot 2 OT | qt Si )
P (O)
t i t i
i
T i
i
Decoding
Decoding
GIVEN a HMM, and a sequence O.
Suppose that we know the parameters of the Hidden
Markov Model and the observed sequence of
observations O1, O2, ... , OT.
FIND the sequence Q of states that maximizes
P(Q|O,)
Determining the sequence of States q1, q2, ... , qT,
which is optimal in some meaningful sense. (i.e. best
“explain” the observations)
P (O, Q | )
Consider P(Q O, ) P (O | )
So that maximizes the above probability
This is equivalent to maximizing
P (O, Q | )
ai1 bi1o1 ai1i2 bi2o2 ai2i3 bi3o3 aiT 1iT biT oT
P (O, Q | )
A best path finding
problem
a02
0
max P (O, Q | )
max ln( P (O, Q | ))
P(Q O, )
1
1
1
…
1
2
2
2
…
2
…
…
…
N
N
N
K
o1
o2
o3
…
…
N
on
max( ln ai1 bi1o1 ln ai1i2 bi2o2 ln aiT 1iT biT oT )
Viterbi Algorithm
A dynamic programming
Initialization:
δ1(i) = a0ibi(O1) , i = 1…N
ψ1(i) = 0.
Recursion:
δt(j) = maxi [δt-1(i) aij]bj(Ot)
t=2…T
j=1…N
ψ1(j) = argmaxi [δt-1(i) aij] t=2…T
j=1…N
Termination:
P* = maxi δT(i)
qT* = argmaxi [δT(i) ]
Traceback:
qt* = ψ1(q*t+1 )
t=T-1,T-2,…,1.
Learning
Estimation of Parameters of a Hidden Markov Model
1. Both the sequence of observations O and the
sequence of States Q is observed
learning = (A, B, )
2. Only the sequence of observations O are observed
learning Q and = (A, B, )
Given O and Q then the Likelihood is given
by: L A, B, a b a b a b a b
i1 i1o1 i1i2 i2o2 i2i3 i3o3
iT 1iT iT oT
the log-Likelihood is given by:
ln a ln b ln a ln b
l A, B, ln L A, B, ln ai1 ln bi1o1 ln ai1i2
i2i3
i3o3
iT 1iT
M
M
iT oT
f i 0 ln ai f ij ln aij ln bio
M
M
i 1
i 1 j 1
i 1 o i
where f i 0 the number of times state i occurs in the first state
fij the number of times state i changes to state j.
iy f y i (or p y i in the discrete case)
oi
the sum of all observatio ns ot where qt Si
In such case these parameters computed by
Maximum Likelihood estimation are:
fi0
aˆi
1
f ij
aˆij M
, and
fij
j 1
b̂i = the MLE of bi computed from the
observations ot where qt = Si.
Only the sequence of observations O are
observed
L A, B,
a b
a b ai2i3 bi3o3 aiT 1iT biT oT
i1 i1o1 i1i2 i2o2
i1 ,i2 ... iT
– It is difficult to find the Maximum Likelihood
Estimates directly from the Likelihood function.
– The Techniques that are used are
1. The Segmental K-means Algorithm
2. The Baum-Welch (E-M) Algorithm
The Baum-Welch (E-M)
Algorithm
The E-M algorithm was designed originally to
handle “Missing observations”.
In this case the missing observations are the
states {q1, q2, ... , qT}.
Assuming a model, the states are estimated by
finding their expected values under this model.
(The E part of the E-M algorithm).
With these values the model is estimated by
Maximum Likelihood Estimation (The M
part of the E-M algorithm).
The process is repeated until the estimated
model converges.
The E-M Algorithm
Let f O, Q LO, Q, denote the joint
distribution of Q,O.
Consider the function:
Q, EX ln LO, Q, Q,
(1)
.
Starting with an initial estimate of
A sequence of estimates (m) are formed by
( m 1)
( m)
Q
,
finding
to maximize
with respect to .
The sequence of estimates(m)
converge to a local maximum of the
likelihood
.
LQ, f Q