Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
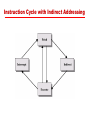
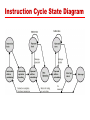
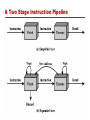
Chapter 12 CPU Structure and Function Example Register Organizations PowerPC Register organization Registers • CPU must have some working space (temporary or scratch pad storage) • Top level of memory hierarchy • Number and function vary between processor designs • How many? how large? how used? User/Supervisor Visible Registers • General Purpose or fixed use, byte, word, double word accessable • Data – accumulator?, integer, FP, alphanumeric • Address – data pointers, segment mapping • Control – IR, PSW, SP, interrupt enb & vector(s), state/context information Note: CPU Architecture & Op Sys are closely tied Simplified CPU Instruction Sequence • Fetch instructions • Interpret instructions • Fetch Operands (Calc Addr & get data) • Execute (Process data) • Write results (Calculate Addr & store data) Instruction Cycle with Indirect Addressing Instruction Cycle State Diagram Speed up Can be achieved through: • Faster cycle time • Implementing parallelism Prefetch Consider the instruction sequence as: • Fetch instruction • Execution instruction (often does not access main memory) Can computer fetch next instruction during execution of current instruction ? • Called instruction Prefetch What are the implications of Prefetch? Improved Performance with Prefetch • Improved speed, but not doubled, why? —Fetch usually shorter than execution —Any jump or branch means that prefetched instructions are not the required instructions • Could we Prefetch more than one instruction ? • Could we add “more stages” to further improve performance? Pipelining For our purpose here consider the instruction sequence as: • instruction fetch, • decode instruction, • fetch data, • execute instruction, • store result, • check for interrupt Consider it as an “assembly line” of operations. Then we can begin the next instruction assembly line sequence before the last has finished. Actually we can fetch the next instruction while the present one is being decoded. This is pipelining. A Two Stage Instruction Pipeline Pipeline “stations” Let’s define a possible set of Pipeline stations: • • • • • • Fetch Instruction (FI) Decode Instruction (DI) Calculate Operand Addresses (CO) Fetch Operands (FO) Execute Instruction (EI) Write Operand (WO) Possible Timing Diagram for Instruction Pipeline Operation Limitation: maximum time for any stage and overhead of transfers The Impact of a Conditional Branch on Instruction Pipeline Operation Instruction 3 is a conditional branch to instruction 15: Alternative Pipeline View Instruction 3 is conditional branch to instruction 15: Speedup Factors with Instruction Pipelining Branching – Possible approaches • • • • • Multiple Streams Prefetch Branch Target Loop Buffer Branch Prediction Delayed Branching Multiple Streams • Have two pipelines • Prefetch each branch into a separate pipeline • Use appropriate pipeline Challenges: • Leads to bus & register contention • Multiple branches lead to further pipelines being needed Prefetch Branch Target • Target of branch is prefetched in addition to instructions following branch • Keep target until branch is executed Loop Buffer • Use Very fast memory (“Loop Buffer Cache”) • Maintained by fetch stage of pipeline • Check buffer before fetching from memory Very good for small loops or jumps in small code sections Branch Prediction • Predict branch never taken or Predict branch always taken • Predict by opcode • Use Predict branch taken/not taken switch • Maintain branch history table Which is best? Predict Branch Taken / Not taken • Predict never taken —Assume that jump will not happen —Always fetch next instruction • Predict always taken —Assume that jump will happen —Always fetch target instruction Which is better – consider possible page faults? Branch Prediction by Opcode / Switch • Predict by Opcode —Some instructions are more likely to result in a jump than others —Can get up to 75% success with this stategy • Taken/Not taken switch —Based on previous history —Good for loops —Perhaps good to match programmer style Maintain Branch Table • Perhaps maintain a cache table of three entries: - Address of branch - History of branching - Targets of branch Intel 80486 Pipelining • Fetch (Fetch) — — — — — From cache or external memory Put in one of two 16-byte prefetch buffers Fill buffer with new data as soon as old data consumed Average 5 instructions fetched per load Independent of other stages to keep buffers full • Decode stage 1 (D1) — Opcode & address-mode info — At most first 3 bytes of instruction — Can direct D2 stage to get rest of instruction • Decode stage 2 (D2) — Expand opcode into control signals — Computation of complex address modes • Execute (EX) — ALU operations, cache access, register update • Writeback (WB) — Update registers & flags — Results sent to cache & bus interface write buffers 80486 Instruction Pipeline Examples