Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
II. Descriptive
Statistics
(Zar, Chapters 1 - 4)
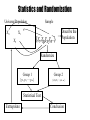
Statistics and Randomization
Universe/Population
X4
X1
Sample
{c1, c2,c3,c4,K}
X2
Describe the
Population
Randomize
Group 1
{ y1 , y2 ,L, y m}
Group 2
{ z1 ,z2 ,L, zn - m }
Statistical Test
Extrapolate
Conclusion
Statistical Test
Hypothesis
H0:Group 1 = Group 2
HA:Group 1 ≠ Group 2
Or
HA1:Group 1 < Group 2
HA2:Group 1 > Group 2
Null Hypothesis
Alternative
Two-sided
One-sided
Types of Data
. Discrete
. Binary
(Examples: alive or dead
heads or tails
Drug "A" or Drug "B"
Male or Female
Normal/Disease)
Representation as data:
0 = alive
1 = dead
or
"A" for "alive "
"D" FOR "dead"
Sample then is
{x ,x , , x }
1
2
n
with each x having only two choices
Summarize by
(1)
Table
Factor number
Status
Alive
25
Dead
10
(2) Histogram
(a) Numbers
%
71%
29%
(b) Percent
.Coded
(ex. diagnosis, genus/species,
race, TNM, stage, color)
Representation as data:
By name or coded name
1 = Caucasian, Non Hispanic
2 = Black (African American)
3 = Hispanic
or just “C”, “B” or “A”, and “H”
if 4 = Oriental, then C,B(A), H, O.
Race
Summarize by
(1)
Table
Number
W
B
H
O
(2) Histogram
Numbers
10
5
12
7
%
29%
15%
34%
21%
Percent
Ordered Scale
Examples:
Date,
Severity Scales (Benign, Possible Ca,Probable Ca, Cancer),
Agreement/Preference (Likert:Strongly Disagree, Disagree,
Neutral, Agree, Strongly Agree)
Stage
Strength Scales (0, +, ++, +++)
Represented by an Integer Scale
1: Benign;
2: Possible;
3: Not Sure or Neutral;
4: Probable;
5: Cancer
Summarized by:
(1) Table
Stage
0
+
++
+++
(2) Histogram
Percent
Number
10
8
14
10
Percent
23.8
19.0
33.3
23.8
Cummulative Percent
Continuous
Ratio Scales
Scale differences are the same
(Ex: most data that have a zero)
0
1
2
3
4
5
6
7
8
9
10
True ratio data
(Ex: normalized data:
raw data
treated effector
background control target
.1
.2
.4
.6
.8
1
2
Continuous Log Scale
4
6
8
10
Representation of data:
real number
scientific notation
real number w/significant digits
{x1, x2, … ,xn}
Summarized by
(1) Table
Ex: 10 data points
x1 = 1.5 x 2 = 8, x3 = 4 x4 = 1 x5 = 4.5
x6 = 5 x7 = 3.5 x8 = 4.5 x9 = 7 x10 = 5.5
(a) Point Plot
X4 X1
X8
X7X3X5X6X10 X9 X2
0 1 2 3 4 5 6 7 8
(b) histogram
(1) form “bins”
Ex: 0-2, 2-4, 4-6, 6-8
(2) count number of data points in
each bin and plot # or %
(a) Count
(b) Percent
( c ) Cummulative Histogram
1) form bins as before
0-2, 2-4, 4-6, 6-8
2) Count number ≤ or ≥
0
2
4
6
8 10
0 0-2 0-4 0-6 0-8 0-10
≥0-10 2-10 4-10 6-10 8-10 0
What else can we do to summarize, or describe, the data?
(1) define where the center of the data lies
(measures of central tendency)
(2) how the data varies from that center
(measures of dispersion)
Center
Dispersion
Two numbers instead of all n
Chapter 3
Measures of Central Tendency
Where is the middle of the data?
Random Sample: x1, x2, ---, xn
(1) The arithmetic mean (average)
x =
x1 x2
xn
n
X4 X1
X8
X7X3X5X6X10 X9 X2
n
=
i =1
x =
xi
n
1.5 8 4 ... 5.5
10
Center of Gravity
= 4.45
(2) The order statistics
x(1) = min (xi) ≤ x(2) ≤ x(3) ≤ … ≤ x(n) = max(xi)
x4 ≤ x1 ≤ x7 ≤ x3 ≤ x5 = x8 ≤ x6 ≤ x10 ≤ x9 ≤ x2
x(1) ≤ x(2) ≤ x(3) ≤ x(4) ≤ x(5.5) = x(5.5) ≤ x(7) ≤ x(8) ≤ x(9) ≤ x(10)
For Ties, sum up the indices and divide by the
number of ties!!
Ex., x5 and x8 are tied (4.5)
the order statistic index is (5+6)/2,
The order statistic is x5.5.
Median - middle order statistic:
If n is odd, it’s the middle statistic
xmedian = x n1
2
If n is even, it’s the average of the two middles
xmedian
= x n x n / 2
1
2 2
If we want a formula that has even and odd together,
we can use the greatest integer function:
xmed =
x([ n / 2]) x([( n1) / 2])
2
Where [-] is the “greatest integer in … “
In the example above, n = 10, [n/2] = 5
xmed =
x(5) x(6)
2
x5 x8 4.5 4.5
=
=
2
2
Plot the order statistic index (plot i on the y-axis)
against the corresponding order statistic (x(i) on the x-axis),
The plot is called a frequency polygon:
(3) The Mode
The x where the histogram is maximal.
Usually use the midpoint of the box
where the histogram is maximal.
Ex: In our continuous example:
The mode is in the box 4-6 = 5.0 = (4+6)/2
(4) The mid-range
mid-range =
x(1) x( n )
2
1.0 8.0
=
= 4.5
2
(5) The geometric mean
n
xgeo = n x1 x2 xn = n xi
i =1
Derivation of the geometric mean.
Let yi = log10(x i)
Then
-
n
y = yi / n
i =1
n
= log10 ( xi ) / n
i =1
n
1
= log10 xi
n
i =1
10 = 10
y
n
= xi
n
i =1
= xgeo
1
log10
n
xi
(6) The harmonic mean
harmonic mean =
1
1
1
n
x
i
=
n
1
x
i
SUMMARY: Measures of Central Tendency
(1) MEAN
Data evenly weighted
n
x = xi / n
i =1
Average of salaries in lab:
4 hard working G.R.A. = 20,000
20,000
20,000
20,000
1 Faculty member
100,000
180,000
Mean=36,000.
(2) Median
Center of Data
50% above, 50% below
Median=20,000
(3) Mode bin sizes to be about the same
Mode=20,000
(4) Midrange - only the endpoints.
100,000 + 20,000
= 60,000
Chapter 4
Measures of Dispersion and Variability
(1)
Range
Range = x(n) - x(1)
(2)
Mean Deviation
n
xi - x
i =1
n
mean deviation =
(3) Variance
n
n
s2 =
i =1
( xi - x )
n -1
2
x
i
=
2
- nx 2
i =1
n -1
Sometimes called the sample variance.
Sometimes called the moment of inertia.
Variance (cont.)
Each data point selected randomly and independently
of all other points. It represents a degree of freedom.
A sample of n points is a vector in n-dimensional space.
The new statistics used by s2 are xi - x
n
n
n
(x - x ) = x - x
i
i =1
i =1
i
n
= xi - nx
i =1
n
n
i =1
i =1
= xi - n xi / x)
=0
i =1
so that the xi - x are not independent
The estimate of for the true mean costs one
degree of freedom to make (n-1) degrees of freedom.
(4) The standard deviation
s= s =
2
(x - x )
2
i
(n - 1)
= sd
The units of s are the same as xi
(5) The standard error of the mean
se = s / n
(6) The coefficient of variation
s
CV = 100%
x
(7) Quartiles (Divide the data in Quarters)
1st: q1 = x([ n / 4]1)
Ex: q1 = x([10 / 4]1) = x7 = 3.
(25% percentile)
2nd : median
(50%)
3rd: q3 = x([3n / 4]1)
Ex: q3 = x([103/ 4]1) = x(8) = x10 = 5.5
(75% percentile)
Interquartile range:
IQR = q3 - q1
Percentiles (Divide into %)
jth Percentile = x(nj /100)
(8) Indicies of diversity
“Shannon Index”
k
H = pi log pi
'
Information Theory
i -1
where
pi =
hi
n
and hi = data pts in the ith bin.
The pi’s represent & estimate
the “true” probabilities in the bins (∑pi = 100%).
H =
n log n - hi log hi
n
So, How do we use a measure of the Center
and a measure of Dispersion to represent the data?
(1) Mean SD or SE
In a Table
In a Graph
More common: Histogram Bars with whiskers
Problem: perception of lower limits -- who is similar?
Choices:
Standard Deviation
Show Population
Variability
Standard Error
Show Mean
Comparisons
Confidence Interval
Shows the result
of the t-test
Box Plot
Median with quartiles
Whiskers for Min&Max
Circles/Asterisk for outliers
Extrapolation to the Universe
Sample Space
Universe
Probability Density Function Is
esti
f ( x)
mat
ed
by
Histogram
As the sample size n gets large and bin width gets small
n
, bin width
0
Parameter in the Universe
Statistic in the Sample Space
= xf ( x)dx
xn
n
= ( x - ) f ( x)dx
sn2
n
2
.5 =
F ( x) =
2
Median
-
f ( x)dx, Median
n xmed
x
Cummulative Histogram ( x )
n
- f (u)du
F(x) is called the distribution function and is also
approximated by the frequency polygon.
n