Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
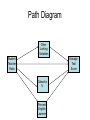
Stat 112 Notes 9 • Today: – Multicollinearity (Chapter 4.6) – Multiple regression and causal inference Assessing Quality of Prediction (Chapter 3.5.3) • R squared is a measure of a fit of the regression to the sample data. It is not generally considered an adequate measure of the regression’s ability to predict the responses for new observations. • One method of assessing the ability of the regression to predict the responses for new observations is data splitting. • We split the data into a two groups – a training sample and a holdout sample (also called a validation sample). We fit the regression model to the training sample and then assess the quality of predictions of the regression model to the holdout sample. Measuring Quality of Predictions Let n2 be the number of points in the holdout sample. Let X1 , , X n2 be the points in the holdout sample. Let Yˆ , , Yˆ be the predictions of Y for the points in the holdout 1 n2 sample based on the model fit on the training sample. Mean Squared Deviation (MSD)= ˆ )2 ( Y Y i i i 1 n2 n2 Root Mean Squared Deviation (RMSD) = ˆ )2 ( Y Y i i i 1 n2 n2 Root Mean Squared Deviation is comparable to Root Mean Square Error but Root Mean Squared Deviation will generally be larger because it takes into account both the fact that Y often deviates from E (Y | X ) (i.e., fact that there are disturbances in regression equation) and the fact that the least squares estimates have errors and do not equal the true slope coefficients. Root Mean Squared Deviation for state.JMP data set on state average SAT scores Our training sample was the states Kansas-Wyoming and our validation sample was the states Alabama-Iowa. 2 ˆ ( y y ) i1 i i n2 Root Mean Squared Deviation = n2 Root Mean Squared Deviation Multiple Regression 34.04 Elena/Leah 35.15 Joanna/Mark/Shannon 36.08 Kathryn/Kendall/Carly 59.00 Renee/Amy/Tatiana 89.59 Multicollinearity • DATA: A real estate agents wants to develop a model to predict the selling price of a home. The agent takes a random sample of 100 homes that were recently sold and records the selling price (y), the number of bedrooms (x1), the size in square feet (x2) and the lot size in square feet (x3). Data is in houseprice.JMP. Scatterplot Matrix 200000 Price 100000 5.0 4.0 3.0 2.0 3000 2500 2000 1500 Bedrooms House Size 8000 6000 Lot Size 4000 100000 2.0 3.5 5.0 1500 25004000 7000 Response Price Summary of Fit RSquare RSquare Adj Root Mean Square Error Mean of Response Observations (or Sum Wgts) 0.559998 0.546248 25022.71 154066 100 Analysis of Variance Source DF Sum of Squares Mean Square F Ratio Model 3 7.65017e10 2.5501e10 40.7269 Prob > F Error 96 6.0109e+10 626135896 C. Total 99 1.36611e11 <.0001 Parameter Estimates Term Intercept Bedrooms House Size Lot Size Estimate Std Error t Ratio Prob>|t| 37717.595 14176.74 2.66 0.0091 2306.0808 6994.192 0.33 0.7423 74.296806 52.97858 1.40 0.1640 -4.363783 17.024 -0.26 0.7982 There is strong evidence that predictors are useful, p-value for F-test <.0001 and R 2 .560 , but the t-tests for each coefficient are not significant. Indicative of multicollinearity. Note: These results illustrate how the F test is more powerful for testing whether a group of slopes in multiple regression are all zero than individual t tests. Multicollinearity • Multicollinearity: Explanatory variables are highly correlated with each other. It is often hard to determine their individual regression coefficients. Multivariate Correlations Bedrooms House Size Lot Size Bedrooms House Size Lot Size 1.0000 0.8465 0.8374 0.8465 1.0000 0.9936 0.8374 0.9936 1.0000 • There is very little information in the data set to find out what would happen if we fix house size and change lot size. • Since house size and lot size are highly correlated, for fixed house size, lot sizes do not change much. • The standard error for estimating the coefficient of lot sizes is large. Consequently the coefficient may not be significant. • Similarly for the coefficient of house size. • So, while it seems that at least one of the coefficients is significant (See ANOVA) you cannot tell which one is the useful one. Consequences of Multicollinearity • Standard errors of regression coefficients are large. As a result t statistics for testing the population regression coefficients are small. • Regression coefficient estimates are unstable. Signs of coefficients may be opposite of what is intuitively reasonable (e.g., negative sign on lot size). Dropping or adding one variable in the regression causes large change in estimates of coefficients of other variables. Detecting Multicollinearity 1. Pairwise correlations between explanatory variables are high. 2. Large overall F-statistic for testing usefulness of predictors but small t statistics. 3. Variance inflation factors Variance Inflation Factors • Variance inflation factor (VIF): Let R2j denote the R2 for the multiple regression of xj on the other x-variables. Then VIFj 1 . 1 R2j • Fact: MSE SD ˆ j VIF n 1 S x2 j j 2 • VIFj for variable xj: Measure of the increase in the variance of the coefficient on xj due to the correlation among the explanatory variables compared to what the variance of the coefficient on xj would be if xj were independent of the other explanatory variables. Using VIFs • To obtain VIFs, after Fit Model, go to Parameter Estimates, right click, click Columns and click VIFs. • Detecting multicollinearity with VIFs: – Any individual VIF greater than 10 indicates multicollinearity. Summary of Fit RSquare 0.559998 Parameter Estimates Term Intercept Bedrooms House Size Lot Size Estimate Std Error t Ratio Prob>|t| VIF 37717.595 14176.74 2.66 0.0091 . 2306.0808 6994.192 0.33 0.7423 3.5399784 74.296806 52.97858 1.40 0.1640 83.066839 -4.363783 17.024 -0.26 0.7982 78.841292 Multicollinearity and Prediction • If interest is in predicting y, as long as pattern of multicollinearity continues for those observations where forecasts are desired (e.g., house size and lot size are either both high, both medium or both small), multicollinearity is not particularly problematic. • If interest is in predicting y for observations where pattern of multicollinearity is different than that in sample (e.g., large house size, small lot size), no good solution (this would be extrapolation). Problems caused by multicollinearity • If interest is in predicting y, as long as pattern of multicollinearity continues for those observations where forecasts are desired (e.g., house size and lot size are either both high, both medium or both small), multicollinearity is not particularly problematic. • If interest is in obtaining individual regression coefficients, there is no good solution in face of multicollinearity. • If interest is in predicting y for observations where pattern of multicollinearity is different than that in sample (e.g., large house size, small lot size), no good solution (this would be extrapolation). Dealing with Multicollinearity • Suffer: If prediction within the range of the data is the only goal, not the interpretation of the coefficients, then leave the multicollinearity alone. • Omit a variable. Multicollinearity can be reduced by removing one of the highly correlated variables. However, if one wants to estimate the partial slope of one variable holding fixed the other variables, omitting a variable is not an option, as it changes the interpretation of the slope. California Test Score Data • The California Standardized Testing and Reporting (STAR) data set californiastar.JMP contains data on test performance, school characteristics and student demographic backgrounds from 1998-1999. • Average Test Score is the average of the reading and math scores for a standardized test administered to 5th grade students. • One interesting question: What would be the causal effect of decreasing the student-teacher ratio by one student per teacher? Multiple Regression and Causal Inference • Goal: Figure out what the causal effect on average test score would be of decreasing student-teacher ratio and keeping everything else in the world fixed. • Lurking variable: A variable that is associated with both average test score and student-teacher ratio. • In order to figure out whether a drop in studentteacher ratio causes higher test scores, we want to compare mean test scores among schools with different student-teacher ratios but the same values of the lurking variables, i.e. we want to hold the value of the lurking variable fixed. • If we include all of the lurking variables in the multiple regression model, the coefficient on student-teacher ratio represents the change in the mean of test scores that is caused by a one unit increase in student-teacher ratio. Omitted Variables Bias Response Average Test Score Parameter Estimates Term Intercept Student Teacher Ratio Estimate 698.93295 -2.279808 Std Error 9.467491 0.479826 t Ratio 73.82 -4.75 Prob>|t| <.0001 <.0001 Response Average Test Score Parameter Estimates Term Intercept Student Teacher Ratio Percent of English Learners Estimate 686.03225 -1.101296 -0.649777 Std Error 7.411312 0.380278 0.039343 t Ratio 92.57 -2.90 -16.52 Prob>|t| <.0001 0.0040 <.0001 • Schools with many English learners tend to have worst resources. The multiple regression that shows how mean test score changes when student teacher ratio changes but percent of English learners is held fixed gives a better idea of the causal effect of the studentteacher ratio than the simple linear regression that does not hold percent of English learners fixed. • Omitted variables bias: bias in estimating the causal effect of a variable from omitting a lurking variable from the multiple regression. • Omitted variables bias of omitting percentage of English learners = -2.28-(-1.10)=-1.28. Key Warning About Using Multiple Regression for Causal Inference • Even if we have included many lurking variables in the multiple regression, we may have failed to include one or not have enough data to include one. There will then be omitted variables bias. • The best way to study causal effects is to do a randomized experiment. Path Diagram Other Lurking Variables StudentTeacher Ratio Average Test Score Calworks % Percent English Learners