Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
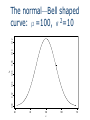
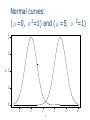
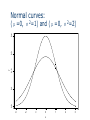
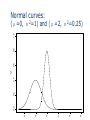
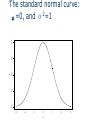
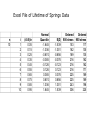
Chapter 9 Normal Distribution 9.1 Continuous distribution 9.2 The normal distribution 9.3 A check for normality 9.4 Application of the normal distribution 9.5 Normal approximation to Binomial 9.1 Continuous Distribution For a discrete distribution, for example Binomial distribution with n=5, and p=0.4, the probability distribution is x f(x) 0 0.07776 1 0.2592 2 3 0.3456 0.2304 4 0.0768 5 0.01024 A probability histogram 0.3 0.2 P(x) 0.1 0.0 0 1 2 3 x 4 5 How to describe the distribution of a continuous random variable? For continuous random variable, we also represent probabilities by areas—not by areas of rectangles, but by areas under continuous curves. For continuous random variables, the place of histograms will be taken by continuous curves. Imagine a histogram with narrower and narrower classes. Then we can get a curve by joining the top of the rectangles. This continuous curve is called a probability density (or probability distribution). Continuous distributions For any x, P(X=x)=0. (For a continuous distribution, the area under a point is 0.) Can’t use P(X=x) to describe the probability distribution of X Instead, consider P(a≤X≤b) P(a≤X≤b) is the area between a and b 0.20 The area under the curve is 1 0.15 0.00 0.05 0.10 A curve f(x): f(x) ≥ 0 y 0.25 Density function 0 2 4 6 x 8 10 0.00 0.05 0.10 y 0.15 0.20 0.25 P(2≤X≤4)= P(2≤X<4)= P(2<X<4) 0 2 4 6 x 8 10 9.2 The normal distribution A normal curve: Bell shaped Density is given by 2 1 (x ) f ( x) exp 2 2 2 μand σ2 are two parameters: mean and standard variance of a normal population (σ is the standard deviation) 0.06 0.04 0.02 0.00 fx 0.08 0.10 0.12 The normal—Bell shaped curve: μ=100, σ2=10 90 95 100 x 105 110 0.2 0.1 0.0 fx1 0.3 0.4 Normal curves: (μ=0, σ2=1) and (μ=5, σ 2=1) -2 0 2 4 x 6 8 Normal curves: 0.2 0.1 0.0 y 0.3 0.4 (μ=0, σ2=1) and (μ=0, σ2=2) -3 -2 -1 0 x 1 2 3 Normal curves: 0.0 0.2 0.4 fx1 0.6 0.8 1.0 (μ=0, σ2=1) and (μ=2, σ2=0.25) -2 0 2 4 6 8 0.2 0.1 0.0 y 0.3 0.4 The standard normal curve: μ=0, and σ2=1 -3 -2 -1 0 x 1 2 3 How to calculate the probability of a normal random variable? Each normal random variable, X, has a density function, say f(x) (it is a normal curve). Probability P(a<X<b) is the area between a and b, under the normal curve f(x) Table I in the back of the book gives areas for a standard normal curve with =0 and =1. Probabilities for any normal curve (any and ) can be rewritten in terms of a standard normal curve. Table I: Normal-curve Areas Table I on page 494-495 We need it for tests Areas under standard normal curve Areas between 0 and z (z>0) How to get an area between a and b? when a<b, and a, b positive area[0,b]–area[0,a] Get the probability from standard normal table z denotes a standard normal random variable Standard normal curve is symmetric about the origin 0 Draw a graph Table I: P(0<Z<z) z 0.0 0.1 0.2 0.3 0.4 0.5 … 1.0 1.1 .00 .0000 .0398 .0793 .1179 .1554 .1915 … .3413 .3643 .01 .0040 .0438 .0832 .1217 .1591 .1950 … .3438 .3665 .02 .0080 .0478 .0871 .1255 .1628 .1985 … .3461 .3686 .03 .0120 .0517 .0910 .1293 .1664 .2019 … .3485 .3708 .04 .0160 .0557 .0948 .1331 .1700 .2054 … .3508 .3729 .05 .0199 .0596 .0987 .1368 .1736 .2088 … .3531 .3749 .06 .0239 .0636 .1026 .1404 .1772 .2123 … .3554 .3770 Examples Adobe Acrobat 7.0 Document Example 9.1 P(0<Z<1) = 0.3413 Example 9.2 P(1<Z<2) =P(0<Z<2)–P(0<Z<1) =0.4772–0.3413 =0.1359 Examples Adobe Acrobat 7.0 Document Example 9.3 P(Z≥1) =0.5–P(0<Z<1) =0.5–0.3413 =0.1587 Examples Adobe Acrobat 7.0 Document Example 9.4 P(Z ≥ -1) =0.3413+0.50 =0.8413 Examples Adobe Acrobat 7.0 Document Example 9.5 P(-2<Z<1) =0.4772+0.3413 =0.8185 Examples Adobe Acrobat 7.0 Document Example 9.6 P(Z ≤ 1.87) =0.5+P(0<Z ≤ 1.87) =0.5+0.4693 =0.9693 Examples Adobe Acrobat 7.0 Document Example 9.7 P(Z<-1.87) = P(Z>1.87) = 0.5–0.4693 = 0.0307 From non-standard normal to standard normal X is a normal random variable with mean μ, and standard deviation σ Set Z=(X–μ)/σ Z=standard unit or z-score of X Then Z has a standard normal distribution and Example 9.8 X is a normal random variable with μ=120, and σ=15 Find the probability P(X≤135) Solution: x x 120 Let z 15 120 120 z is normal z 0 15 15 z 1 15 x 135 120 P( x 135) P( ) P( z 1) 0.5 0.3413 0.8413 15 XZ x z-score of x Example 9.8 (continued) P(X≤150) x=150 z-score z=(150-120)/15=2 P(X≤150)=P(Z≤2) = 0.5+0.4772= 0.9772 9.3 Checking Normality Most of the statistical tools we will use in this class assume normal distributions. In order to know if these are the right tools for a particular job, we need to be able to assess if the data appear to have come from a normal population. A normal plot gives a good visual check for normality. Simulation: 100 observations, normal with mean=5, st dev=1 5 4 3 2 x 6 7 8 x<-rnorm(100, mean=5, sd=1) qqnorm(x) -2 -1 0 Quantiles of Standard Normal 1 2 Estimating a woman’s risk of having a preganancy associated with Down’s syndrome using her age and serum alpha-fetoprotein level H.S.Cuckle, N.J.Wald, S.O.Thompson The plot below shows results on alpha-fetoprotein (AFP) levels in maternal blood for normal and Down’s syndrome fetuses. Normal Plot The way these normal plots work is Straight means that the data appear normal Parallel means that the groups have similar variances. Normal plot In order to plot the data and check for normality, we compare •our observed data to •what we would expect from a sample of normal data. To begin with, imagine taking n=5 random values from a standard normal population (=0, =1) Let Z(1) Z(2) Z(3) Z(4) Z(5) be the ordered values. Suppose we do this over and over. Sample 1 2 3 … Forever Mean Z(1) -1.7 -0.9 -2.3 … ___ -1.163 E(Z(1)) Z(2) -0.2 0.2 -1.5 … ___ -0.495 E(Z(2)) Z(3) 0.8 0.5 -0.6 … ___ 0 E(Z(3)) Z(4) 1.3 0.9 0.4 … ___ 0.495 E(Z(4)) Z(5) 1.9 2.0 1.3 … ___ 1.163 E(Z(5)) On average the smallest of n=5 standard normal values is 1.163 standard deviations below average the second smallest of n=5 standard normal values is 0.495 standard deviations below average the middle of n=5 standard normal values is at the average, 0 standard deviations from average The table of “rankits” from the Statistics in Biology table gives these expected values. For larger n, space is saved by just giving the positive values. The negative values are a mirror image of the positive values, since a standard normal distribution is symmetric about its mean of zero. Check for normality If X is normal, how do ordered values of X, X(i) , relate to expected ordered Z values, E( Z(i) ) ? Z X X Z For normal with mean and standard deviation , the expected values of the data, X(i), will be a linear rescaling of standard normal expected values E(X(i)) ≈ + E( Z(i) ) The observed data X(i) will be approximately a linearly related to E( Z(i) ). X(i) ≈ + E( Z(i) ) If we plot the ordered X values versus E( Z(i) ), we should see roughly a straight line with •intercept •slope Example Example: Lifetimes of springs under 900 N/mm2 stress i 1 2 3 4 5 6 7 8 9 10 E( Z(i) ) -1.539 -1.001 -0.656 -0.376 -0.123 0.123 0.376 0.656 1.001 1.539 X(i) 153 162 189 216 216 216 225 225 243 306 Lifetime of Springs at Stress 900 350 Lifetime 300 250 900 stress 200 150 100 -2.000 -1.000 0.000 1.000 2.000 E(Z) The plot is fairly linear indicating that the data are pretty similar to what we would expect from normal data. To compare results from different treatments, we can put more than one normal plot on the same graph. 350 Lifetime 300 250 950 stress 900 stress 200 150 100 -2.000 -1.000 0.000 1.000 2.000 E(Z) The intercept for the 900 stress level is above the intercept for the 950 stress group, indicating that the mean lifetime of the 900 stress group is greater than the mean of the 950 stress group. The slopes are similar, indicating that the variances or standard deviations are similar. These plots were done in Excel. In Excel you can either enter values from the table of E(Z) values or generate approximations to these tables values. One way to generate approximate E(Z) values is to generate evenly spaced percentiles of a standard normal, Z, distribution. The ordered X values correspond roughly to particular percentiles of a normal distribution. For example if we had n=5 values, the 3rd ordered values would be roughly the median or 50th percentile. A common method is to use percentiles corresponding to 100 i 0.5 . n For n=5 this would give us i i 0.5 n 1 2 3 4 5 0.1 0.3 0.5 0.7 0.9 the 50th percentile For E(Z) we would use corresponding percentiles of a standard normal Z distribution. Percentiles expressed as fractions are called quantiles. The 0.5 quantile is the 50th percentile. Normal plots from this perspective are sometimes called Q-Q plots, since we are plotting standard normal quantiles versus the associated quantiles of the observed data. For n = 10 values for the spring data, the corresponding normal percentiles would be i 0.5 i Z quantile n 1 2 3 4 5 6 7 8 9 10 0.05 0.15 0.25 0.35 0.45 0.55 0.65 0.75 0.85 0.95 -1.64 -1.04 -0.67 -0.39 -0.13 0.13 0.39 0.67 1.04 1.64 For assessing whether a plotted line is fairly parallel, either the E(Z) values or the normal quantiles work fine. If you are doing the plot by hand it’s easiest to use the E(Z) table. If you are doing these in Excel it’s easiest to use the normal quantiles. The function NORMINV(p,0,1) finds the Z values corresponding to a given quantile. This is the inverse of the function that finds the cumulative probability for a given Z value. Z NORMDIST probability = NORMDIST(1.645, 0, 1, TRUE) 0.95 Probability NORMINV probability = NORMINV(0.95, 0, 1) 1.645 (The TRUE in NORMDIST says to return the cumulative probability rather than density curve height.) Excel File of Lifetime of Springs Data n 10 i 1 2 3 4 5 6 7 8 9 10 (i-0.5)/n 0.05 0.15 0.25 0.35 0.45 0.55 0.65 0.75 0.85 0.95 Normal Quantile -1.645 -1.036 -0.674 -0.385 -0.126 0.126 0.385 0.674 1.036 1.645 Ordered E(Z) 900 stress -1.539 153 -1.001 162 -0.656 189 -0.376 216 -0.123 216 0.123 216 0.376 225 0.656 225 1.001 243 1.539 306 Ordered 950 stress 117 135 135 162 162 171 189 189 198 225 For data that are not normal Many types of data tend to follow a normal distribution, but many data sets aren’t particularly normal. If the data aren’t fairly normal we have several options Transform the data, meaning change the scale. A log or ln scale is most common. • Weights of fish • Concentrations • Bilirubin levels in blood • pH is a log scale • RNA expression levels in a microarray experiment A reciprocal (1/Y) change of times to rates Other powers • Square root for Poisson variables Non-normal data continued Use a different distribution other than a normal distribution Weibull distribution for lifetimes • Motors at General Electric • Patients in a clinical trial Weibull Distributions (Time to Failure – Non-binomial & Nonnormal) Infant Mortality: Fail immediately or last a long time Early Failure: These do not fail immediately, but many do fail early Old-age Wearout: Very few of these fail until they were out Non-normal data continued Use a nonparametric methods which doesn’t assume any distribution Finding a distribution that models the data well rather than nonparametric • Allows us to develop a more complete model • Allows us to generalize to other situations • Gives us more precise information for the same amount of effort The methods in this class largely apply to normal data or data that we can transform to normal. The EPA fish example is a good example of transforming data with a log transformation. Geometric means and harmonic means arise when we are working with transformed data. For example fish weights are usually analyzed in the log scale. Having a mean in the log scale we want to put this value back into the original scale, for example grams. The back-transformed mean from the log scale is the geometric mean. The back-transformed mean from a reciprocal scale (rates), is the harmonic mean. Back-transformed differences between geometric means correspond to ratios in the original scale. Suppose ln(X) = Y ~ N(, 2). This means Y (or ln(x)) distributed as normal with mean and variance 2. The geometric mean is e, the backtransformed population mean in the ln scale. If we have the difference between two means in the ln scale then backtransforming give us e 1 2 e e 1 2 = ratio of geometric means. About geometric means A fact is that if the variances of both populations are the same, then the ratio of the population geometric means is the same as the ratio of the population means. Question: Why not just use the means in the original scale? Answer: Means are best when populations are normal. Using the ratio of the geometric means will give us a more precise estimate of the true ratio than using the ratio of the means in the original scale. A similar fact explains why we use means rather than medians. For a normal population the mean is the same as the median. We could use either the sample mean or the sample median to estimate . BUT, the mean will be a more precise guess (estimate of) the true value, . It would take us roughly 50% more values (larger n) using the median as our guess at to accomplish the same degree of precision as we get using the mean as our guess at . 9.4 Application of the normal distribution 1960-62 Public Health Service Health Examination Survey 6,672 Americans 18-79 years old The woman’s heights were approximately normal with 63 and standard deviation 2.5 . What percentage of women were over 68 tall? Solution: X=height P(X>68)=P(Z>(68-63)/2.5)) =P(Z>2) =0.5-0.4772 =0.0228 Continuity Correction for a Better Approximation Sometimes only integer values are possible for x. x=score of LSAT x=# of heads in 10 tosses of a fair coin A normal approximation is more accurate with a “continuity correction” 1976 LSAT Approximately normal mean 650, st. dev 60 P(X≥680)P(Z>(679.5-650)/60) =P(Z>0.49) =0.5-0.1879 =0.3121 9.5 Normal Approximation to Binomial A binomial distribution: n=10, p=0.5 μ=np=5 σ2=np(1-p)=2.5 σ=1.58 1. P(X≥7)=0.172 from Binomial 2. P(X≥7)= P(Z>(6.5-5)/1.58) 3. =P(Z>0.95) =0.5-0.3289=0.1711 from normal approximation Dots: Binomial Probabilities 0.00 0.05 0.10 fx 0.15 0.20 0.25 Smoot Line: Normal Curve With Same Mean and Variance 0 2 4 6 x 8 10 Normal Approximation Is Good If The normal curve has the same mean and standard deviation as binomial np>5 and n(1-p)>5 Continuity correction is made Example 1. 2. 3. 4. Records show that 60% of the customers of a service station pay with a credit card. Use normal approximation to find the probabilities that among 100 customers At most 65 will pay with a credit At least 55 will pay with a credit Between 55 and 65 will pay with a credit card Exactly 65 will pay with a credit card Solution: X=# of customers who pay with a credit card μ=np=60, σ2=np(1-p)=24 σ=4.8990 65.5 60 P ( X 65) P ( Z ) P ( Z 1.12) 4.899 0.5 0.3686 0.8686 54.5 60 P ( X 55) P ( Z ) P ( Z 1.12) 4.899 P ( Z 1.12) 0.5 0.3686 0.8686 Normal Approximation 3. 54.5 60 65.5 60 P(55 X 65) P( Z ) 4.899 4.899 P(1.12 Z 1.12) 2(0.3686) 0.7372 4. P( X 65) P(65 X 65) 64.5 60 65.5 60 P( Z ) 4.899 4.899 P(0.92 Z 1.12) 0.3686 0.3212 0.0474