Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
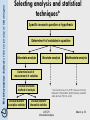
The Information School of the University of Washington LIS 570 Session 6.1 Univariate Data Analysis The Information School of the University of Washington Objectives: Have answers to the following questions • Why is the normal distribution important for statistical analysis (the ones presented) to make sense? • What is the logic behind inferential statistics? (On what theories is it based?) • What is a Confidence Interval? • In what ways can we summarize quantitative data? • What are some visualization techniques to help us summarize and make sense of data? LIS 570 Univariate Analysis Mason; p. 2 The Information School of the University of Washington Agenda • • • • • • Exercise: understand “the problem” Vocabulary Functions of statistics When to use what type Descriptive statistics Inferential statistics LIS 570 Univariate Analysis Mason; p. 3 The Information School of the University of Washington Why and What • Why know statistics? – – – – Informed consumer… Informed user… Informed professional… … • What is a statistic? a descriptive summary (index) of a sample LIS 570 Univariate Analysis Mason; p. 4 The Information School of the University of Washington Sample and Population Sample Population (Universe) A set of observations, instances, individuals drawn from a population, usually intended to represent the population in a study The totality of things we are interested in (e.g., the population of all students at the UW) Population Sample Average = 4.5 Average = 4.55 statistic parameter A statistic is a characteristic of a sample, while the same characteristic, if descriptive of a population, is called a population parameter. LIS 570 Univariate Analysis Mason; p. 5 The Information School of the University of Washington 2 major functions of statistics • Help us describe characteristics of sample – Descriptive statistics – Procedures to summarize, organize, and simplify data • Help us describe characteristics of population – Inferential statistics – Techniques for studying samples, and then make generalizations about the population from which the samples were selected.* * Source: Gravetter, F. J. and Wallnau, L. B. (2002). Essentials of Statistics for the Behavioral Sciences. 4th edition. Pacific Grove, CA: Wadsworth, p. 5 LIS 570 Univariate Analysis Mason; p. 6 The Information School of the University of Washington Vocabulary • Variable—characteristic which has more than one value – e.g., Sex—male, female; hours of work/week— anything from 0 – 168 – Independent variable (X)—manipulated by the researcher or believed to be the cause of… – Dependent variable (Y)—variable observed to assess the effect of the manipulation, or changes depending on the independent variable • Data—observations (measurements) taken on the units of analysis LIS 570 Univariate Analysis Mason; p. 7 The Information School of the University of Washington Choosing the Statistical Technique* Specific research question or hypothesis Determine # of variables in question Univariate analysis Bivariate analysis Multivariate analysis Determine level of measurement of variables Choose univariate method of analysis Choose relevant descriptive statistics Choose relevant inferential statistics LIS 570 Univariate Analysis * Source: De Vaus, D.A. (1991) Surveys in Social Research. Third edition. North Sydney, Australia: Allen & Unwin Pty Ltd., p133 Mason; p. 8 The Information School of the University of Washington What To Do with a Bunch of Numbers • Organize the observations • Interested primarily in normality and deviations from normality • Examine – Central tendency – Dispersion – Shape of distribution • Visualization aids – – – – – – – Frequency distribution (percentile) tables and charts Histograms Bar & pie charts (nominal data) Frequency polygon Cumulative percentage curve Stem and leaf diagrams Box plots LIS 570 Univariate Analysis Mason; p. 9 The Information School of the University of Washington Frequency Distributions • Ungrouped frequency distribution • A list of each of the values of the variable • The number of times and/or the percent of times each value occurs • Grouped frequency distribution • A table or graph • Shows frequencies or percent for ranges of values LIS 570 Univariate Analysis Mason; p. 10 The Information School of the University of Washington Frequency distributions Include in frequency distribution tables: – – – – – – – Table number and title Labels for the categories of the variables Column headings Total number of cases (N) The number of missing cases Source of the data Footnotes to explain anomalies and notes * Source: De Vaus, D.A. (1991) Surveys in Social Research. Third edition. North Sydney, Australia: Allen & Unwin Pty Ltd., p133 LIS 570 Univariate Analysis Mason; p. 11 The Information School of the University of Washington Grouped frequency distribution Table 1—Example of grouped frequency distribution Real Limits* Frequencies (ƒ) Cumulative frequencies (Cf) Percent (%) Cumulative Percent 9-10 8.5 - 10.4999 3 20 15 100 7-8 6.5 - 8.4999 4 17 20 85 5-6 4.5 - 6.4999 7 13 35 65 3-4 2.5 - 4.4999 4 6 20 30 1-2 0.5 - 2.4999 2 2 10 10 Total (N) 20 Score Range (Your value label) Valid cases: 20 100 Missing cases: 0 Note 1: “Real limits” of a score extend from one-half of the smallest unit of measurement below the value of the score to one half unit above. Note 2: Percent (%) = (ƒ /N) * 100, Cumulative % = (Cf/N) * 100 LIS 570 Univariate Analysis Mason; p. 12 20 15 Frequency The Information School of the University of Washington Histogram 10 5 0 47 52 57 62 67 72 77 82 87 92 97 Statistics exam scores -The height of the bar corresponds to the frequency (ƒ) -The width of the bar extends to the real limits of the score -Used only on interval and ratio scales -No space between bars (that’s a bar chart) LIS 570 Univariate Analysis score intervals ƒ 45-49 1 50-54 2 55-59 4 60-64 4 65-69 7 70-74 9 75-79 16 80-84 10 85-89 7 90-94 6 95-99 2 Mason; p. 13 The Information School of the University of Washington What do graphs (histograms) show? • Normality (normal distributions) [Why are normal distributions important?] • Deviations from normality – – – – Positive skewness Negative skewness Bimodality And more… LIS 570 Univariate Analysis Mason; p. 14 symmetrical Normal distribution: symmetrical Bell-shaped curve asymmetrical The Information School of the University of Washington Shapes of distribution Positively skewed: tail on the right, cluster towards low end of the variable Bimodality: A double peak Negatively skewed: tail on the left, cluster towards highend of the variable LIS 570 Univariate Analysis Mason; p. 15 The Information School of the University of Washington Central Tendency • Central tendency is a single summary figure that ideally, is the most representative value of all values in the distribution. • Used to describe “typical” or representative value Mean (arithmetic mean), m – Sum all the observations; divide by N: use for interval variables when appropriate – Median: Value that divides the distribution so that an equal number of values are above the median and an equal number below – Mode: Value with the greatest frequency (uni-modal, bi-modal, etc.) LIS 570 Univariate Analysis Mason; p. 16 The Information School of the University of Washington Variability, dispersion, spread • Why do we care about anything besides central tendency? • Variability refers to spread or dispersion • The extent to which a set of scores scatter about or cluster together • Measures of variability – – – – – – Range Interquartile range Sum-of-squares Variance Standard deviation Kurtosis Equal means, unequal variability LIS 570 Univariate Analysis Mason; p. 17 The Information School of the University of Washington Kurtosis Two distributions: the same mean & variance Karl Pearson suggested names • Longer tailed: leptokurtic • Shorter tailed: platykurtic http://members.aol.com/jeff570/k.html LIS 570 Univariate Analysis Mason; p. 18 The Information School of the University of Washington Mode (Mo): most common value • Best for nominal level data • Cautions: – – – – most common may not measure typicality not sensitive to outliers (good and bad) may be more than one mode unstable from sample to sample • Dispersion – variation ratio (v) • % of people not in the modal category LIS 570 Univariate Analysis Mason; p. 19 The Information School of the University of Washington Median (Mdn): Even split of sample • For interval or ratio data, good for skewed distributions (mean would not be a good measure of central tendency) • Minimal calculation (need to know frequencies) • Reasonably insensitive to outliers (as long as there are only a few) • Reasonably stable from sample to sample • Example of ordinal variables – people are ranked from low to high (e.g., height) – median is the middle case – the median category is the one to which the middle person belongs LIS 570 Univariate Analysis Mason; p. 20 The Information School of the University of Washington Median– simple examples –1234567 • Mdn = 4 – 1 2 3 5 6 7 9 13 • Mdn = 5.5 by interpolation between 5 & 6 (5+6)/2 = 11/2 = 5.5 LIS 570 Univariate Analysis Mason; p. 21 The Information School of the University of Washington Dispersion • The nth percentile of a set of numbers is a value such that n percent of the numbers fall below it and the rest fall above. – The median is the 50th percentile – The lower quartile is the 25th percentile – The upper quartile is the 75th percentile • Summary of sample using 5 numbers: median, mean, variance, and extremes LIS 570 Univariate Analysis Mason; p. 22 The Information School of the University of Washington Dispersion Bottom 25% Lower quartile Interquartile range Median Top 25% Upper quartile LIS 570 Univariate Analysis Mason; p. 23 The Information School of the University of Washington Boxplot Interquartile range (IQR) Variable 1 Variable 2 Variable 3 4 6 8 10 LIS 570 Univariate Analysis 12 14 16 Mason; p. 24 The Information School of the University of Washington Mean • Uses the actual numerical values of the observations • Most stable from sample to sample • Most common measure of center • Makes sense only for interval or ratio data • Frequently computed for ordinal variables as well • Not a good representation of central tendency for skewed samples LIS 570 Univariate Analysis Mason; p. 25 The Information School of the University of Washington Mean--Dispersion • The standard deviation and variance measure spread about the mean as centre. • Deviation: distance and direction from the mean – Doesn’t work as a measure of variability because adds up to zero (see next slide). • Variance – mean of the squared deviation scores (of the deviations of observations from the mean). • Standard deviation – Conceptually: the typical distance of scores from the mean – Technically: the square root of the variance LIS 570 Univariate Analysis Mason; p. 26 The Information School of the University of Washington Example Data (6,7,5,3,4) x= 6+7+5+3+4 = 5 – Variance (S2) • • • • • 25 5 = 5 Calculate the mean for the variable Take each observation and subtract the mean from it Square the result from the above Add (sum) all the individual results Divide by n LIS 570 Univariate Analysis Mason; p. 27 The Information School of the University of Washington Variance (s2) Observation x 6 7 5 3 4 Deviation Sq. deviation x-x (x - x)2 6-5 = 1 1 7-5 = 2 4 5-5 = 0 0 3-5 = -2 4 4-5 = -1 1 Sum = 10 Variance = sum of the sq deviations = 10 = 2 number of observations 5 LIS 570 Univariate Analysis Mason; p. 28 The Information School of the University of Washington Standard deviation (s) • Square root of the variance 2 = 1.4 • An average deviation of the observations from their mean • Influenced by outliers • Best used with symmetrical distributions LIS 570 Univariate Analysis Mason; p. 29 The Information School of the University of Washington Summary • Descriptive statistics – univariate analysis (central tendency, frequency distribution, dispersion) • Determine if variable is nominal, ordinal or interval • Nominal: frequency tables, mode • Ordinal – – – – Frequency tables (grouped frequency tables) histogram Median and five number summary Mode LIS 570 Univariate Analysis Mason; p. 30 The Information School of the University of Washington Summary Interval Determine whether the distribution is skewed or symmetrical Compare median and mean Use the mean and the standard deviation if the distribution is not markedly skewed; otherwise use five number summary (median, extremes, mid-quartile numbers) Use the mode in addition if it adds anything LIS 570 Univariate Analysis Mason; p. 31 The Information School of the University of Washington Abstract and Elevator Speech 20-30 second synopsis; intent: to elicit interest • Who you are and what you are doing • With whom • Where/How • Why: What you hope to find, why the results may be important 100-300 words; elicit interest and summarize • What type of study • How approached • When, where • Why: what you hope to find, why the results may be important LIS 570 Univariate Analysis Mason; p. 32 The Information School of the University of Washington Selecting analysis and statistical techniques* Specific research question or hypothesis Determine # of variables in question Univariate analysis Bivariate analysis Multivariate analysis Determine level of measurement of variables Choose univariate method of analysis Choose relevant descriptive statistics * Source: De Vaus, D.A. (1991) Surveys in Social Research. Third edition. North Sydney, Australia: Allen & Unwin Pty Ltd., p133 Choose relevant inferential statistics LIS 570 Univariate Analysis Mason; p. 33 The Information School of the University of Washington Exercise—sampling distribution • • • • Coins, coins! Probability of head or tails—50% Each of you is a “sample” for this activity. Flip the coin 7 times, count the # of times you get a “head”. Live demo: http://www.ruf.rice.edu/~lane/stat_sim/sampling _dist/index.html LIS 570 Univariate Analysis Mason; p. 34 The Information School of the University of Washington 68% Why is normality important? • • • 95% 100% Use proportions of the normal distribution to determine probabilities associated with any specific sample. Sampling Error Standard Error (SE)—a way for defining and measuring sampling error (exactly, how much error, on average, should exist between a sample mean and the unknown population mean, simply due to chance. LIS 570 Univariate Analysis Mason; p. 35 The Information School of the University of Washington Standard Error of the mean Standard error of the mean (Sm) Sm = – – – – S S Standard deviation Total number in the sample N Standard error is inversely related to square root of sample size To reduce standard error, increase sample size Standard error is directly related to standard deviation When N = 1, standard error is equal to standard deviation LIS 570 Univariate Analysis Mason; p. 36 The Information School of the University of Washington Inferential statistics - univariate analysis Interval estimates and interval variables • Estimation of sample mean accuracy—based on random sampling and probability theory – Standardize the sample mean to estimate population mean: t = sample mean – population mean estimated SE – Population mean = sample mean + t * (estimated SE) LIS 570 Univariate Analysis Mason; p. 37 The Information School of the University of Washington Confidence Interval Utilizes probability theory, assumes normal distribution • 95% of the samples will fall within 1 to 2 standard deviations from the population mean • By the same token, for 95% of samples, the population mean will be within + or - 2 standard error units from the sample mean • E.g., for C.I. 80%, first find the lower and upper t-values that bind 80% area of the distribution. • Can state: with 80% confidence interval, the population mean is: sample mean + t (SE) LIS 570 Univariate Analysis Mason; p. 38 The Information School of the University of Washington Standard Error (for nominal & ordinal data) Variable must have only two categories (may have to combine categories to achieve this) P = the % in one category of the variable SB = PQ N Q = the % in the other category of the variable Total number in the sample Standard error for binominal distribution LIS 570 Univariate Analysis Mason; p. 39