Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
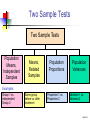
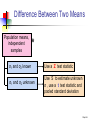
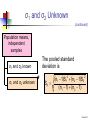
Two-Sample Tests Chap 9-1 Two Sample Tests Two Sample Tests Population Means, Independent Samples Means, Related Samples Population Proportions Population Variances Examples: Group 1 vs. independent Group 2 Same group before vs. after treatment Proportion 1 vs. Proportion 2 Variance 1 vs. Variance 2 Chap 9-2 Difference Between Two Means Population means, independent samples * σ1 and σ2 known σ1 and σ2 unknown Goal: Test hypotheses or form a confidence interval for the difference between two population means, μ1 – μ2 The point estimate for the difference is X1 – X2 Chap 9-3 Independent Samples Population means, independent samples * σ1 and σ2 known σ1 and σ2 unknown Different data sources Unrelated Independent Sample selected from one population has no effect on the sample selected from the other population Use the difference between 2 sample means Use Z test or pooled variance t test Chap 9-4 Difference Between Two Means Population means, independent samples * σ1 and σ2 known Use a Z test statistic σ1 and σ2 unknown Use S to estimate unknown σ , use a t test statistic and pooled standard deviation Chap 9-5 σ1 and σ2 Known Population means, independent samples σ1 and σ2 known σ1 and σ2 unknown Assumptions: * Samples are randomly and independently drawn population distributions are normal or both sample sizes are 30 Population standard deviations are known Chap 9-6 σ1 and σ2 Known (continued) Population means, independent samples σ1 and σ2 known When σ1 and σ2 are known and both populations are normal or both sample sizes are at least 30, the test statistic is a Z-value… * …and the standard error of X1 – X2 is σ1 and σ2 unknown σ X1 X2 2 1 2 σ σ2 n1 n2 Chap 9-7 σ1 and σ2 Known (continued) Population means, independent samples σ1 and σ2 known σ1 and σ2 unknown The test statistic for μ1 – μ2 is: * X Z 1 X 2 μ1 μ2 2 1 2 σ σ2 n1 n2 Chap 9-8 Hypothesis Tests for Two Population Means Two Population Means, Independent Samples Lower-tail test: Upper-tail test: Two-tail test: H0: μ1 μ2 H1: μ1 < μ2 H0: μ1 ≤ μ2 H1: μ1 > μ2 H0: μ1 = μ2 H1: μ1 ≠ μ2 i.e., i.e., i.e., H0: μ1 – μ2 0 H1: μ1 – μ2 < 0 H0: μ1 – μ2 ≤ 0 H1: μ1 – μ2 > 0 H0: μ1 – μ2 = 0 H1: μ1 – μ2 ≠ 0 Chap 9-9 Hypothesis tests for μ1 – μ2 Two Population Means, Independent Samples Lower-tail test: Upper-tail test: Two-tail test: H0: μ1 – μ2 0 H1: μ1 – μ2 < 0 H0: μ1 – μ2 ≤ 0 H1: μ1 – μ2 > 0 H0: μ1 – μ2 = 0 H1: μ1 – μ2 ≠ 0 a a -za Reject H0 if Z < -Za za Reject H0 if Z > Za a/2 -za/2 a/2 za/2 Reject H0 if Z < -Za/2 or Z > Za/2 Chap 9-10 Confidence Interval, σ1 and σ2 Known Population means, independent samples σ1 and σ2 known σ1 and σ2 unknown The confidence interval for μ1 – μ2 is: * 2 1 2 σ σ2 X1 X 2 Z n1 n2 Chap 9-11 σ1 and σ2 Unknown Assumptions: Population means, independent samples Samples are randomly and independently drawn σ1 and σ2 known σ1 and σ2 unknown * Populations are normally distributed or both sample sizes are at least 30 Population variances are unknown but assumed equal Chap 9-12 σ1 and σ2 Unknown (continued) Forming interval estimates: Population means, independent samples σ1 and σ2 known σ1 and σ2 unknown * The population variances are assumed equal, so use the two sample standard deviations and pool them to estimate σ the test statistic is a t value with (n1 + n2 – 2) degrees of freedom Chap 9-13 σ1 and σ2 Unknown (continued) Population means, independent samples The pooled standard deviation is σ1 and σ2 known σ1 and σ2 unknown * Sp n1 1S12 n2 1S2 2 (n1 1) (n2 1) Chap 9-14 σ1 and σ2 Unknown (continued) The test statistic for μ1 – μ2 is: Population means, independent samples X X μ μ t 1 σ1 and σ2 known σ1 and σ2 unknown 2 1 2 1 1 S n1 n2 2 p * Where t has (n1 + n2 – 2) d.f., and S 2 p 2 2 n1 1S1 n2 1S2 (n1 1) (n2 1) Chap 9-15 Confidence Interval, σ1 and σ2 Unknown Population means, independent samples The confidence interval for μ1 – μ2 is: X X t σ1 and σ2 known σ1 and σ2 unknown 1 2 * n1 n2 -2 1 1 S n1 n2 2 p Where 2 2 n 1 S n 1 S 1 2 2 S2 1 p (n1 1) (n2 1) Chap 9-16 Pooled Sp t Test: Example You are a financial analyst for a brokerage firm. Is there a difference in dividend yield between stocks listed on the NYSE & NASDAQ? You collect the following data: NYSE NASDAQ Number 21 25 Sample mean 3.27 2.53 Sample std dev 1.30 1.16 Assuming both populations are approximately normal with equal variances, is there a difference in average yield (a = 0.05)? Chap 9-17 Calculating the Test Statistic The test statistic is: X X μ μ t 1 2 1 1 1 S n1 n2 2 p 2 3.27 2.53 0 1 1 1.5021 21 25 2 2 2 2 n 1 S n 1 S 21 1 1.30 25 1 1.16 1 2 2 S2 1 p (n1 1) (n2 1) (21 - 1) (25 1) 2.040 1.5021 Chap 9-18 Solution H0: μ1 - μ2 = 0 i.e. (μ1 = μ2) H1: μ1 - μ2 ≠ 0 i.e. (μ1 ≠ μ2) a = 0.05 df = 21 + 25 - 2 = 44 Critical Values: t = ± 2.0154 Reject H0 .025 -2.0154 Reject H0 .025 0 2.0154 t 2.040 Test Statistic: Decision: 3.27 2.53 t 2.040 Reject H0 at a = 0.05 1 1 Conclusion: 1.5021 21 25 There is evidence of a difference in means. Chap 9-19 Related Samples Tests Means of 2 Related Populations Related samples Paired or matched samples Repeated measures (before/after) Use difference between paired values: D = X1 - X2 Eliminates Variation Among Subjects Assumptions: Both Populations Are Normally Distributed Or, if Not Normal, use large samples Chap 9-20 Mean Difference, σD Known The ith paired difference is Di , where Related samples Di = X1i - X2i n The point estimate for the population mean paired difference is D : D D i 1 i n Suppose the population standard deviation of the difference scores, σD, is known n is the number of pairs in the paired sample Chap 9-21 Mean Difference, σD Known (continued) Paired samples The test statistic for the mean difference is a Z value: D μD Z σD n Where μD = hypothesized mean difference σD = population standard dev. of differences n = the sample size (number of pairs) Chap 9-22 Confidence Interval, σD Known Paired samples The confidence interval for D is σD DZ n Where n = the sample size (number of pairs in the paired sample) Chap 9-23 Mean Difference, σD Unknown Related samples If σD is unknown, we can estimate the unknown population standard deviation with a sample standard deviation: The sample standard deviation is n SD 2 (D D ) i i1 n 1 Chap 9-24 Mean Difference, σD Unknown (continued) Paired samples The test statistic for D is now a t statistic, with n-1 d.f.: D μD t SD n n Where t has n - 1 d.f. and SD is: SD (D i1 i D) 2 n 1 Chap 9-25 Confidence Interval, σD Unknown Paired samples The confidence interval for D is SD D t n1 n n where SD (D D) i1 2 i n 1 Chap 9-26 Hypothesis Testing for Mean Difference, σD Unknown Paired Samples Lower-tail test: Upper-tail test: Two-tail test: H0: μD 0 H1: μD < 0 H0: μD ≤ 0 H1: μD > 0 H0: μD = 0 H1: μD ≠ 0 a a -ta Reject H0 if t < -ta ta Reject H0 if t > ta Where t has n - 1 d.f. a/2 -ta/2 a/2 ta/2 Reject H0 if t < -ta/2 or t > ta/2 Chap 9-27 Paired Samples Example Assume you send your salespeople to a “customer service” training workshop. Is the training effective? You collect the following data: Number of Complaints: (2) - (1) Salesperson Before (1) After (2) Difference, Di C.B. T.F. M.H. R.K. M.O. 6 20 3 0 4 4 6 2 0 0 - 2 -14 - 1 0 - 4 -21 D = Di n = -4.2 SD (D D) 2 i n 1 5.67 Chap 9-28 Paired Samples: Solution Has the training made a difference in the number of complaints (at the 0.01 level)? H0: μD = 0 H1: μD 0 a = .01 D = - 4.2 Critical Value = ± 4.604 d.f. = n - 1 = 4 Reject Reject a/2 a/2 - 4.604 4.604 - 1.66 Decision: Do not reject H0 (t stat is not in the reject region) Test Statistic: D μD 4.2 0 t 1.66 SD / n 5.67/ 5 Conclusion: There is not a significant change in the number of complaints. Chap 9-29 Two Population Proportions Population proportions Goal: test a hypothesis or form a confidence interval for the difference between two population proportions, p 1 – p2 Assumptions: n1p1 5 , n1(1-p1) 5 n2p2 5 , n2(1-p2) 5 The point estimate for the difference is ps1 ps2 Chap 9-30 Two Population Proportions Population proportions Since we begin by assuming the null hypothesis is true, we assume p1 = p2 and pool the two ps estimates The pooled estimate for the overall proportion is: X1 X2 p n1 n2 where X1 and X2 are the numbers from samples 1 and 2 with the characteristic of interest Chap 9-31 Two Population Proportions (continued) The test statistic for p1 – p2 is a Z statistic: Population proportions p Z where p s1 p s2 p1 p 2 1 1 p (1 p) n1 n2 X1 X2 X X , p s1 1 , p s2 2 n1 n2 n1 n2 Chap 9-32 Confidence Interval for Two Population Proportions Population proportions p s1 The confidence interval for p1 – p2 is: p s2 Z p s1 (1 p s1 ) n1 p s2 (1 p s2 ) n2 Chap 9-33 Hypothesis Tests for Two Population Proportions Population proportions Lower-tail test: Upper-tail test: Two-tail test: H0: p1 p2 H1: p1 < p2 H0: p1 ≤ p2 H1: p1 > p2 H0: p1 = p2 H1: p1 ≠ p2 i.e., i.e., i.e., H0: p1 – p2 0 H1: p1 – p2 < 0 H0: p1 – p2 ≤ 0 H1: p1 – p2 > 0 H0: p1 – p2 = 0 H1: p1 – p2 ≠ 0 Chap 9-34 Hypothesis Tests for Two Population Proportions (continued) Population proportions Lower-tail test: Upper-tail test: Two-tail test: H0: p1 – p2 0 H1: p1 – p2 < 0 H0: p1 – p2 ≤ 0 H1: p1 – p2 > 0 H0: p1 – p2 = 0 H1: p1 – p2 ≠ 0 a a -za Reject H0 if Z < -Za za Reject H0 if Z > Za a/2 -za/2 a/2 za/2 Reject H0 if Z < -Za/2 or Z > Za/2 Chap 9-35 Example: Two population Proportions Is there a significant difference between the proportion of men and the proportion of women who will vote Yes on Proposition A? In a random sample, 36 of 72 men and 31 of 50 women indicated they would vote Yes Test at the .05 level of significance Chap 9-36 Example: Two population Proportions (continued) The hypothesis test is: H0: p1 – p2 = 0 (the two proportions are equal) H1: p1 – p2 ≠ 0 (there is a significant difference between proportions) The sample proportions are: Men: ps1 = 36/72 = .50 Women: ps2 = 31/50 = .62 The pooled estimate for the overall proportion is: X1 X 2 36 31 67 p .549 n1 n2 72 50 122 Chap 9-37 Example: Two population Proportions (continued) The test statistic for p1 – p2 is: z p s1 p s2 p1 p 2 1 1 p (1 p) n1 n2 .50 .62 0 1 1 .549 (1 .549) 72 50 Reject H0 Reject H0 .025 .025 -1.96 -1.31 1.31 Critical Values = ±1.96 For a = .05 1.96 Decision: Do not reject H0 Conclusion: There is not significant evidence of a difference in proportions who will vote yes between men and women. Chap 9-38 Hypothesis Tests for Variances Tests for Two Population Variances F test statistic * H0: σ12 = σ22 H1: σ12 ≠ σ22 Two-tail test H0: σ12 σ22 H1: σ12 < σ22 Lower-tail test H0: σ12 ≤ σ22 H1: σ12 > σ22 Upper-tail test Chap 9-39 Hypothesis Tests for Variances (continued) Tests for Two Population Variances F test statistic The F test statistic is: * 2 1 2 2 S F S S12 = Variance of Sample 1 n1 - 1 = numerator degrees of freedom S22 = Variance of Sample 2 n2 - 1 = denominator degrees of freedom Chap 9-40 The F Distribution The F critical value is found from the F table The are two appropriate degrees of freedom: numerator and denominator S12 F 2 S2 where df1 = n1 – 1 ; df2 = n2 – 1 In the F table, numerator degrees of freedom determine the column denominator degrees of freedom determine the row Chap 9-41 Finding the Rejection Region H0: σ12 σ22 H1: σ12 < σ22 a H0: σ12 = σ22 H1: σ12 ≠ σ22 a/2 0 Reject H0 FL 0 Reject H0 if F < FL Reject H0 H0: σ1 ≤ σ2 H1: σ12 > σ22 2 2 Do not reject H0 FU Reject H0 FL Do not reject H0 FU rejection region for a two-tail test is: a 0 a/2 F Do not reject H0 F F Reject H0 S12 F 2 FU S2 S12 F 2 FL S2 Reject H0 if F > FU Chap 9-42 Finding the Rejection Region (continued) a/2 H0: σ12 = σ22 H1: σ12 ≠ σ22 a/2 0 Reject H0 FL Do not reject H0 FU Reject H0 F To find the critical F values: 1. Find FU from the F table for n1 – 1 numerator and n2 – 1 denominator degrees of freedom 1 2. Find FL using the formula: FL FU* Where FU* is from the F table with n2 – 1 numerator and n1 – 1 denominator degrees of freedom (i.e., switch the d.f. from FU) Chap 9-43 F Test: An Example You are a financial analyst for a brokerage firm. You want to compare dividend yields between stocks listed on the NYSE & NASDAQ. You collect the following data: NYSE NASDAQ Number 21 25 Mean 3.27 2.53 Std dev 1.30 1.16 Is there a difference in the variances between the NYSE & NASDAQ at the a = 0.05 level? Chap 9-44 F Test: Example Solution Form the hypothesis test: H0: σ21 – σ22 = 0 (there is no difference between variances) H1: σ21 – σ22 ≠ 0 (there is a difference between variances) Find the F critical values for a = .05: FU: Numerator: n1 – 1 = 21 – 1 = 20 d.f. Denominator: n2 – 1 = 25 – 1 = 24 d.f. FU = F.025, 20, 24 = 2.33 FL: Numerator: n2 – 1 = 25 – 1 = 24 d.f. Denominator: n1 – 1 = 21 – 1 = 20 d.f. FL = 1/F.025, 24, 20 = 1/2.41 = .41 Chap 9-45 F Test: Example Solution (continued) The test statistic is: H0: σ12 = σ22 H1: σ12 ≠ σ22 S12 1.302 F 2 1.256 2 S2 1.16 a/2 = .025 a/2 = .025 0 Reject H0 F = 1.256 is not in the rejection region, so we do not reject H0 Do not reject H0 FL=0.41 Reject H0 F FU=2.33 Conclusion: There is not sufficient evidence of a difference in variances at a = .05 Chap 9-46