Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
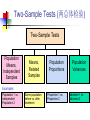
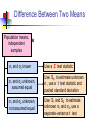
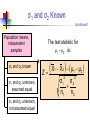
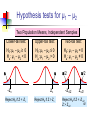
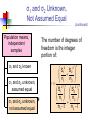
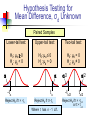
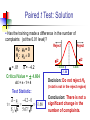
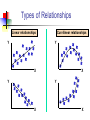
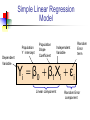
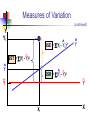
Business Statistics in Practice Chapter 9 Statistical Inferences Based on Two Samples Learning Objectives In this chapter, you learn: How to use hypothesis testing for comparing the difference between The means of two independent populations The means of two related populations The proportions of two independent populations The variances of two independent populations Two-Sample Tests (两总体检验) Two-Sample Tests Population Means, Independent Samples Means, Related Samples Population Proportions Population Variances Examples: Population 1 vs. independent Population 2 Same population before vs. after treatment Proportion 1 vs. Proportion 2 Variance 1 vs. Variance 2 Difference Between Two Means Population means, independent samples * σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal Goal: Test hypothesis or form a confidence interval for the difference between two population means, μ1 – μ2 The point estimate for the difference is X1 – X2 Independent Samples (独立样本) Population means, independent samples * σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal Different data sources Unrelated Independent Sample selected from one population has no effect on the sample selected from the other population Use the difference between 2 sample means Use Z test, a pooled-variance t test, or a separate-variance t test Difference Between Two Means Population means, independent samples * σ1 and σ2 known Use a Z test statistic σ1 and σ2 unknown, assumed equal Use Sp to estimate unknown σ , use a t test statistic and pooled standard deviation σ1 and σ2 unknown, not assumed equal Use S1 and S2 to estimate unknown σ1 and σ2, use a separate-variance t test σ1 and σ2 Known Population means, independent samples σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal Assumptions: * Samples are randomly and independently drawn Population distributions are normal or both sample sizes are 30 Population standard deviations are known σ1 and σ2 Known (continued) Population means, independent samples σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal When σ1 and σ2 are known and both populations are normal or both sample sizes are at least 30, the test statistic is a Z-value… * …and the standard error of X1 – X2 is σ X1 X2 2 1 2 σ σ2 n1 n2 σ1 and σ2 Known (continued) Population means, independent samples σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal The test statistic for μ1 – μ2 is: * X Z 1 X 2 μ1 μ2 2 1 2 σ σ2 n1 n2 Hypothesis Tests for Two Population Means Two Population Means, Independent Samples Lower-tail test: Upper-tail test: Two-tail test: H0: μ1 ≥ μ2 Ha: μ1 < μ2 H0: μ1 ≤ μ2 Ha: μ1 > μ2 H0: μ1 = μ2 Ha: μ1 ≠ μ2 i.e., i.e., i.e., H0: μ1 – μ2 ≥ 0 Ha: μ1 – μ2 < 0 H0: μ1 – μ2 ≤ 0 Ha: μ1 – μ2 > 0 H0: μ1 – μ2 = 0 Ha: μ1 – μ2 ≠ 0 Hypothesis tests for μ1 – μ2 Two Population Means, Independent Samples Lower-tail test: Upper-tail test: Two-tail test: H0: μ1 – μ2 ≥ 0 Ha: μ1 – μ2 < 0 H0: μ1 – μ2 ≤ 0 Ha: μ1 – μ2 > 0 H0: μ1 – μ2 = 0 Ha: μ1 – μ2 ≠ 0 a a -za Reject H0 if Z < -Za za Reject H0 if Z > Za a/2 -za/2 a/2 za/2 Reject H0 if Z < -Za/2 or Z > Za/2 Confidence Interval, σ1 and σ2 Known Population means, independent samples σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal The confidence interval for μ1 – μ2 is: * 2 1 2 σ σ2 X1 X 2 Z n1 n2 Example 9.1 Customer Waiting Time Case A random sample of size 100 waiting times observed under the current system of serving customers has a sample waiting time mean of 8.79 Call this population 1 Assume population 1 is normal or sample size is large The variance is 4.7 A random sample of size 100 waiting times observed under the new system of serving customers has a sample mean waiting time of 5.14 Call this population 2 Assume population 2 is normal or sample size is large The variance is 1.9 Then if the samples are independent … Customer Waiting Time Case At 95% confidence, za/2 = z0.025 = 1.96, and x1 x2 z a 2 12 22 4.7 1.9 8.79 5.14 1.96 n1 n2 100 100 3.65 0.5035 3.15 , 4.15 According to the calculated interval, the bank manager can be 95% confident that the new system reduces the mean waiting time by between 3.15 and 4.15 minutes Customer Waiting Time Case Test the claim that the new system reduces the mean waiting time Test at the a = 0.05 significance level the null H0: m1 – m2 ≤ 0 against the alternative Ha: m1 – m2 > 0 Use the rejection rule H0 if z > za At the 5% significance level, za = z0.05 = 1.645 So reject H0 if z > 1.645 Use the sample and population data in Example 9.1 to calculate the test statistic x1 x2 D0 8.79 5.14 0 z 12 22 n1 n2 4.7 1.9 100 100 3.65 14 .21 0.2569 Customer Waiting Time Case Because z = 14.21 > z0.05 = 1.645, reject H0 Conclude that m1 – m2 is greater than 0 and therefore the new system does reduce the waiting time by 3.65 minutes On average, reduces the mean time by 3.65 minutes The p-value for this test is the area under the standard normal curve to the right of z = 14.21 This z value is off the table, so the p-value has to be much less than 0.001 So, we have extremely strong evidence that H0 is false and that Ha is true Therefore, we have extremely strong evidence that the new system reduces the mean waiting time σ1 and σ2 Unknown, Assumed Equal Assumptions: Population means, independent samples Samples are randomly and independently drawn σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal * Populations are normally distributed or both sample sizes are at least 30 Population variances are unknown but assumed equal σ1 and σ2 Unknown, Assumed Equal (continued) Forming interval estimates: Population means, independent samples σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal * The population variances are assumed equal, so use the two sample variances and pool them to estimate the common σ2 the test statistic is a t value with (n1 + n2 – 2) degrees of freedom σ1 and σ2 Unknown, Assumed Equal (continued) Population means, independent samples The pooled variance (合并 方差) is σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal * S 2 p n1 1S n2 1S2 (n1 1) (n2 1) 2 1 2 σ1 and σ2 Unknown, Assumed Equal (continued) The test statistic for μ1 – μ2 is: Population means, independent samples X X μ μ t 1 σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal 2 1 1 1 S n1 n2 2 p * Where t has (n1 + n2 – 2) d.f., and S 2 p 2 2 n1 1S1 n2 1S2 (n1 1) (n2 1) 2 Confidence Interval, σ1 and σ2 Unknown Population means, independent samples The confidence interval for μ1 – μ2 is: X X t σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal 1 2 * n1 n2 -2 1 1 S n1 n2 2 p Where 2 2 n 1 S n 1 S 1 2 2 S2 1 p (n1 1) (n2 1) Catalyst Comparison Case Example 9.2 The difference in mean hourly yields of a chemical process 2 Given: n 5, x 811.0, s 386.0 1 1 1 n2 5, x2 750.2, s22 484.2 Assume that populations of all possible hourly yields for the two catalysts are both normal with the same variance The pooled estimate of 2 is s 2 p n1 1s12 n2 1s22 n1 n2 2 5 1386 5 1484.2 435.1 5 5 2 Let m1 be the mean hourly yield of catalyst 1 and let m2 be the mean hourly yield of catalyst 2 continued Want the 95% confidence interval for m1 – m2 df = (n1 + n2 – 2) = (5 + 5 – 2) = 8 At 95% confidence, ta/2 = t0.025. For 8 degrees of freedom, t0.025 = 2.306 The 95% confidence interval is 1 1 1 2 1 x1 x2 t0.025 s p 811 750.2 2.306 435.1 5 5 n1 n2 60.8 30.4217 30.38, 91.22 So we can be confident that the mean hourly yield from catalyst 1 is between 30.38 and 91.22 pounds higher than that of catalyst 2 On average, the mean yields will differ by 60.8 lbs Example 9.3 Pooled-Variance t Test You are a financial analyst for a brokerage firm. Is there a difference in dividend yield between stocks listed on the NYSE & NASDAQ? You collect the following data: NYSE NASDAQ Number 21 25 Sample mean 3.27 2.53 Sample std dev 1.30 1.16 Assuming both populations are approximately normal with equal variances, is there a difference in average yield (a = 0.05)? Calculating the Test Statistic The test statistic is: X X μ μ t 1 2 1 1 1 S n1 n2 2 p 2 3.27 2.53 0 1 1 1.5021 21 25 2 2 2 2 n 1 S n 1 S 21 1 1.30 25 1 1.16 1 2 2 S2 1 p (n1 1) (n2 1) (21 - 1) (25 1) 2.040 1.5021 Solution H0: μ1 - μ2 = 0 i.e. (μ1 = μ2) Ha: μ1 - μ2 ≠ 0 i.e. (μ1 ≠ μ2) a = 0.05 df = 21 + 25 - 2 = 44 Critical Values: t = ± 2.0154 Reject H0 .025 -2.0154 Reject H0 .025 0 2.0154 t 2.040 Test Statistic: Decision: 3.27 2.53 t 2.040 Reject H0 at a = 0.05 1 1 Conclusion: 1.5021 21 25 There is evidence of a difference in means. σ1 and σ2 Unknown, Not Assumed Equal Assumptions: Population means, independent samples Samples are randomly and independently drawn Populations are normally distributed or both sample sizes are at least 30 σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal * Population variances are unknown but cannot be assumed to be equal σ1 and σ2 Unknown, Not Assumed Equal (continued) Population means, independent samples Forming the test statistic: The population variances are not assumed equal, so include the two sample variances in the computation of the t-test statistic σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal * the test statistic is a t value with v degrees of freedom (see next slide) σ1 and σ2 Unknown, Not Assumed Equal (continued) Population means, independent samples The number of degrees of freedom is the integer portion of: σ1 and σ2 known σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal * 2 S S2 n n 2 12 2 2 2 S1 S 2 n n 1 2 n1 1 n2 1 2 1 2 σ1 and σ2 Unknown, Not Assumed Equal (continued) Population means, independent samples The test statistic for μ1 – μ2 is: X X μ μ t σ1 and σ2 known 1 σ1 and σ2 unknown, assumed equal σ1 and σ2 unknown, not assumed equal 2 2 1 * 1 2 2 S S n1 n2 2 Exercise A recent EPA study compared the highway fuel economy of domestic and imported passenger cars. A sample of 15 domestic cars revealed a mean of 33.7 mpg with a sample standard deviation of 2.4 mpg. A sample of 12 imported cars revealed a mean of 35.7 mpg with a sample standard deviation of 3.9. Assuming both populations are approximately normal with equal variances, At the .05 significance level can the EPA conclude that the mpg for the domestic cars is lower than the imported cars? Step 1 State the null and alternate hypotheses. H0: µD > µI H1: µD < µI Step 2 The .05 significance level is stated in the problem Step 3 Find the appropriate test statistic. we use the t distribution. Step 4 The decision rule is to reject H0 if t<-1.708 or if p-value < .05. There are n-1 or 25 degrees of freedom. Step 5 We compute the pooled variance. 2 2 ( n 1 )( s ) ( n 1 )( s 2 1 1 2 2) sp n1 n 2 2 (15 1)( 2.4) 2 (12 1)(3.9) 2 9.918 15 12 2 t X1 X 2 1 1 n n 2 1 33 .7 35 .7 s2 p 1 1 8.312 12 15 1.640 Since a computed t of –1.64 > critical t of –1.71, the p-value of .0567 > a of .05, H0 is not rejected. There is insufficient sample evidence to claim a higher mpg on the imported cars. Related Populations (相关总体) Dependent samples are samples that are paired or related in some fashion. If you wished to buy a car you would look at the same car at two (or more) different dealerships and compare the prices. Town and Country Cadillac If you wished to measure the effectiveness of a new diet you would weigh the dieters at the start and at the finish of the program. Downtown Cadillac Example (Related Population): An analyst for Educational Testing Service wants to Compare the mean GMAT scores of students before & after taking a GMAT review course. Nike wants to see if there is a difference in durability of 2 sole materials. One type is placed on one shoe, the other type on the other shoe of the same pair.. Test of Related Populations Tests Means of 2 Related Populations Related samples Paired or matched samples Repeated measures (before/after) Use difference between paired values: di = X1i - X2i Eliminates Variation Among Subjects Assumptions: Both Populations Are Normally Distributed Or, if not Normal, use large samples Mean Difference The ith paired difference is di , where Related samples di = X1i - X2i n The point estimate for the population mean paired difference is d : d d i 1 i n n is the number of pairs in the paired sample Mean Difference, Estimate of σd Related samples We the unknown population standard deviation with a sample standard deviation: The sample standard deviation is n Sd 2 (d d) i i 1 n 1 Mean Difference (continued) Paired samples Use a paired t test, the test statistic for d is a t statistic, with n-1 d.f.: d μd t Sd n n Where t has n - 1 d.f. and Sd is: Sd 2 (d d) i i 1 n 1 Confidence Interval Paired samples The confidence interval for μd is d ta / 2, n 1 Sd n n where Sd (d i 1 i d) 2 n 1 Hypothesis Testing for Mean Difference, σd Unknown Paired Samples Lower-tail test: Upper-tail test: Two-tail test: H0: μd 0 Ha: μd < 0 H0: μd ≤ 0 Ha: μd > 0 H0: μd = 0 Ha: μd ≠ 0 a a -ta Reject H0 if t < -ta ta Reject H0 if t > ta Where t has n - 1 d.f. a/2 -ta/2 a/2 ta/2 Reject H0 if t < -ta/2 or t > ta/2 Example 9.4 Repair Cost Comparison Table: A sample of n=7 paired differences of the repair cost estimates at garages 1 and 2 (Cost estimate in hundreds of dollars) Damaged cars Repair cost estimates at garage 1 Repair cost Paired estimate at garage differences 2 Car 1 Car 2 $7.1 9.0 $7.9 10.1 d1=-0.8 d2=-1.1 Car 3 11.0 12.2 d3=-1.2 Car 4 Car 5 8.9 9.9 8.8 10.4 d4=0.1 d5=-0.5 Car 6 Car 7 9.1 10.3 9.8 11.7 d6=-0.7 d7=-1.4 Repair Cost Comparison Sample of n = 7 damaged cars Each damaged car is taken to Garage 1 for its estimated repair cost, and then is taken to Garage 2 for its estimated repair cost Estimated repair costs at Garage 1: 1x = 9.329 Estimated repair costs at Garage 2: 2x = 10.129 Sample of n = 7 paired differences and d x1 x2 9.329 10.129 0.8 s d2 0.2533 s d 0.5033 continued At 95% confidence, want ta/2 with n – 1 = 6 degrees of freedom ta/2 = 2.447 The 95% confidence interval is sd 0.5033 d t a/2 0.8 2.447 n 7 0.8 0.4654 1.2654 ,0.3346 Can be 95% confident that the mean of all possible paired differences of repair cost estimates at the two garages is between $126.54 and -$33.46 Can be 95% confident that the mean of all possible repair cost estimates at Garage 1 is between $126.54 and $33.46 less than the mean of all possible repair cost estimates at Garage 2 Repair Cost Comparison Now, test if repair cost at Garage 1 is less expensive than at Garage 2, that is, test if md = m1 – m2 is less than zero H0: md ≥ 0 Ha: md < 0 Test at the a = 0.01 significance level. Reject if t < –ta, that is , if t < –t0.01 With n – 1 = 6 degrees of freedom, t0.01 = 3.143 So reject H0 if t < –3.143 continued Calculate the t statistic t d0 sd n 0.8 4.2053 0.5033 7 Because t = –4.2053 is less than –t0.01 = – 3.143, reject H0 Conclude at the a = 0.01 significance level that the mean repair cost at Garage 1 is less than the mean repair cost of Garage 2 From a computer, for t = -4.2053, the p-value is 0.003 Because this p-value is very small, there is very strong evidence that H0 should be rejected and that m1 is actually less than m2 Paired t Test (成对t检验) Example 9.5 Assume you send your salespeople to a “customer service” training workshop. Has the training made a difference in the number of complaints? You collect the following data: Number of Complaints: (2) - (1) Salesperson Before (1) After (2) Difference, di C.B. T.F. M.H. R.K. M.O. 6 20 3 0 4 4 6 2 0 0 - 2 -14 - 1 0 - 4 -21 d = di n = -4.2 Sd 2 (d d) i 5.67 n 1 Paired t Test: Solution Has the training made a difference in the number of complaints (at the 0.01 level)? H0: μd = 0 Ha: μd 0 a = .01 d = - 4.2 Critical Value = ± 4.604 d.f. = n - 1 = 4 Reject Reject a/2 a/2 - 4.604 4.604 - 1.66 Decision: Do not reject H0 (t stat is not in the reject region) Test Statistic: d μ d 4.2 0 t 1.66 Sd / n 5.67/ 5 Conclusion: There is not a significant change in the number of complaints. Two Population Proportions Population proportions Goal: test a hypothesis or form a confidence interval for the difference between two population proportions, p 1 – p2 Assumptions: n1 p1 5 , n1(1- p1) 5 n2 p2 5 , n2(1- p2) 5 The point estimate for the difference is pˆ 1 pˆ 2 Two Population Proportions Then the population of all possible values of p̂1 p̂2 Has approximately a normal distribution if each of the sample sizes n1 and n2 is large Here, n1 and n2 are large enough is n1 p1 ≥ 5, n1 (1 - p1) ≥ 5, n2 p2 ≥ 5, and n1 (1 – p2) ≥ 5 Has mean m p̂1 p̂2 p1 p2 Has standard deviation p̂1 p̂2 p1 1 p1 p2 1 p2 n1 n2 Confidence Interval for Two Population Proportions If the random samples are independent of each other, then the following a 100(1 – α) percent confidence interval for p1 – p2 is: Population proportions p̂1 p̂2 za 2 p̂1 1 p̂1 p̂2 1 p̂2 n1 n2 Testing the Difference of Two Population Proportions Population proportions The test statistic for p1 – p2 is a Z statistic: pˆ1 pˆ 2 ( p1 p2 ) z= pˆ pˆ 1 2 (continued) Testing the Difference of Two Population Proportions (continued) If p1-p2= 0, estimate p̂1 p̂2 by s pˆ1 pˆ 2 pˆ 1 1 pˆ 1 pˆ , n1 n2 the total number of units in the two samples that fall into the category of interest the total number of units in the two samples If p1-p2 ≠ 0, estimate p̂1 p̂2by s p̂1 p̂2 p̂1 1 p̂1 p̂2 1 p̂2 n1 n2 Hypothesis Tests for Two Population Proportions Population proportions Lower-tail test: Upper-tail test: Two-tail test: H0: p1 p2 Ha: p1 < p2 H0: p1 ≤ p2 Ha: p1 > p2 H0: p1 = p2 Ha: p1 ≠ p2 i.e., i.e., i.e., H0: p1 – p2 0 Ha: p1 – p2 < 0 H0: p1 – p2 ≤ 0 Ha: p1 – p2 > 0 H0: p1 – p2 = 0 Ha: p1 – p2 ≠ 0 Hypothesis Tests for Two Population Proportions (continued) Population proportions Lower-tail test: Upper-tail test: Two-tail test: H0: p1 – p2 0 Ha: p1 – p2 < 0 H0: p1 – p2 ≤ 0 Ha: p1 – p2 > 0 H0: p1 – p2 = 0 Ha: p1 – p2 ≠ 0 a a -za Reject H0 if Z < -Za za Reject H0 if Z > Za a/2 -za/2 a/2 za/2 Reject H0 if Z < -Za/2 or Z > Za/2 Example 9.6 Two population Proportions Is there a significant difference between the proportion of men and the proportion of women who will vote Yes on Proposition A? In a random sample, 36 of 72 men and 31 of 50 women indicated they would vote Yes Test at the .05 level of significance Two population Proportions (continued) The hypothesis test is: H0: p1 – p2 = 0 (the two proportions are equal) Ha: p1 – p2 ≠ 0 (there is a significant difference between proportions) The sample proportions are: Men: Women: p̂1 = 36/72 = .50 p̂2 = 31/50 = .62 The pooled estimate for the overall proportion is: X1 X 2 36 31 67 pˆ .549 n1 n 2 72 50 122 Example: Two population Proportions (continued) The test statistic for p1 – p2 is: z pˆ1 pˆ 2 p1 p2 1 1 pˆ (1 pˆ ) n1 n 2 .50 .62 0 1 1 .549 (1 .549) 72 50 Critical Values = ±1.96 For a = .05 Reject H0 Reject H0 .025 .025 -1.96 -1.31 1.31 1.96 Decision: Do not reject H0 Conclusion: There is not significant evidence of a difference in proportions who will vote yes between men and women. Chapter Summary Compared two independent samples Performed Z test for the difference in two means Performed pooled variance t test for the difference in two means Performed separate-variance t test for difference in two means Formed confidence intervals for the difference between two means Compared two related samples (paired samples) Performed paired sample Z and t tests for the mean difference Formed confidence intervals for the mean difference Chapter Summary (continued) Compared two population proportions Formed confidence intervals for the difference between two population proportions Performed Z-test for two population proportions Business Statistics in Practice Chapter 11 Simple Linear Regression Analysis (线性回归分析) Table 11.1 lists the percentage of the labour force that was unemployed during the decade 1991-2000. Plot a graph with the time (years after 1991) on the x axis and percentage of unemployment on the y axis. Do the points follow a clear pattern? Based on these data, what would you expect the percentage of unemployment to be in the year 2005? Table 11.1 Percentage of Civilian Unemployment Number of Years Percentage of Year from 1991 Unemployed 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 0 1 2 3 4 5 6 7 8 9 6.8 7.5 6.9 6.1 5.6 5.4 4.9 4.5 4.2 4.0 The pattern does suggest that we may be able to get useful information by finding a line that “best fits” the data in some meaningful way. It produces the “best-fitting line”. y 0.389 x 7.338 Based on this formula, we can attempt a prediction of the unemployment rate in the year 2005: y (14) 0.389(14) 7.338 1.892 Note: Care must be taken when making predictions by extrapolating from known data, especially when the data set is as small as the one in this example. Learning Objectives In this chapter, you learn: How to use regression analysis to predict the value of a dependent variable based on an independent variable The meaning of the regression coefficients b0 and b1 To make inferences about the slope and correlation coefficient To estimate mean values and predict individual values Correlation(相关) vs. Regression(回归) A scatter diagram (散点图) can be used to show the relationship between two variables Correlation (相关) analysis is used to measure strength of the association (linear relationship) between two variables Correlation is only concerned with strength of the relationship No causal effect (因果效应) is implied with correlation Scatter Diagrams Scatter Diagrams are used to examine possible relationships between two numerical variables The Scatter Diagram: one variable is measured on the vertical axis and the other variable is measured on the horizontal axis Scatter Plots(散点图) Visualize the data to see patterns, especially “trends” Restaurant Ratings: Mean Preference vs. Mean Taste Introduction to Regression Analysis Regression analysis is used to: Predict the value of a dependent variable based on the value of at least one independent variable Explain the impact of changes in an independent variable on the dependent variable Dependent variable: the variable we wish to predict or explain Independent variable: the variable used to explain the dependent variable Simple Linear Regression Model Only one independent variable, X Relationship between X and Y is described by a linear function Changes in Y are assumed to be caused by changes in X Types of Relationships Linear relationships Y Curvilinear relationships Y X Y X Y X X Types of Relationships (continued) Strong relationships Y Weak relationships Y X Y X Y X X Types of Relationships (continued) No relationship Y X Y X Simple Linear Regression Model Population Y intercept Dependent Variable Population Slope Coefficient Independent Variable Random Error term Yi β0 β1Xi ε i Linear component Random Error component Simple Linear Regression Model (continued) Y Yi β0 β1Xi ε i Observed Value of Y for Xi εi Predicted Value of Y for Xi Slope = β1 Random Error for this Xi value Intercept = β0 Xi X Simple Linear Regression Equation (Prediction Line) The simple linear regression equation provides an estimate of the population regression line Estimated (or predicted) Y value for observation i Estimate of the regression intercept Estimate of the regression slope Ŷi b0 b1Xi Value of X for observation i The individual random error terms ei have a mean of zero Least Squares Method (最小二乘方法) b0 and b1 are obtained by finding the values of b0 and b1 that minimize the sum of the squared differences between Y and Ŷ : min (Yi Ŷi ) min (Yi (b0 b1Xi )) 2 2 Interpretation of the Slope(斜率) and the Intercept(截距) b0 is the estimated average value of Y when the value of X is zero b1 is the estimated change in the average value of Y as a result of a one-unit change in X Example 11.1 The House Price Case A real estate agent wishes to examine the relationship between the selling price of a home and its size (measured in square feet) A random sample of 10 houses is selected Dependent variable (Y) = house price in $1000s Independent variable (X) = square feet Graphical Presentation House price model: scatter plot House Price ($1000s) 450 400 350 300 250 200 150 100 50 0 0 500 1000 1500 2000 Square Feet 2500 3000 Graphical Presentation House price model: scatter plot and regression line House Price ($1000s) 450 Intercept = 98.248 400 350 Slope = 0.10977 300 250 200 150 100 50 0 0 500 1000 1500 2000 2500 3000 Square Feet house price 98.24833 0.10977 (square feet) Interpretation of the Intercept, b0 house price 98.24833 0.10977 (square feet) b0 is the estimated average value of Y when the value of X is zero (if X = 0 is in the range of observed X values) Here, no houses had 0 square feet, so b0 = 98.24833 just indicates that, for houses within the range of sizes observed, $98,248.33 is the portion of the house price not explained by square feet Interpretation of the Slope Coefficient, b1 house price 98.24833 0.10977 (square feet) b1 measures the estimated change in the average value of Y as a result of a oneunit change in X Here, b1 = .10977 tells us that the average value of a house increases by .10977($1000) = $109.77, on average, for each additional one square foot of size Predictions using Regression Analysis Predict the price for a house with 2000 square feet: house price 98.25 0.1098 (sq.ft.) 98.25 0.1098(200 0) 317.85 The predicted price for a house with 2000 square feet is 317.85($1,000s) = $317,850 Interpolation vs. Extrapolation When using a regression model for prediction, only predict within the relevant range of data Relevant range for interpolation House Price ($1000s) 450 400 350 300 250 200 150 100 50 0 0 500 1000 1500 2000 Square Feet 2500 3000 Do not try to extrapolate beyond the range of observed X’s The Least Square Point Estimates Estimation/prediction equation yˆ b0 b1 x Least squares point estimate of the slope b1 b1 SS xy SS xx SS xy SS xx ( xi x ) x y ( x x )( y y ) x y i i i i x x n 2 2 i 2 i i n y y n 2 SS yy 2 i Least squares point estimate of the y-intercept b0 b0 y b1 x y y i n i x x i n i Model Assumptions 1. 2. 3. 4. Mean of Zero At any given value of x, the population of potential error term values has a mean equal to zero Constant Variance Assumption At any given value of x, the population of potential error term values has a variance that does not depend on the value of x Normality Assumption At any given value of x, the population of potential error term values has a normal distribution Independence Assumption Any one value of the error term e is statistically independent of any other value of e Measures of Variation Total variation is made up of two parts: SST SSR SSE Total Sum of Squares Regression Sum of Squares SST ( Yi Y)2 SSR ( Ŷi Y )2 Error Sum of Squares SSE ( Yi Ŷi )2 where: Y = Average value of the dependent variable Yi = Observed values of the dependent variable Ŷi = Predicted value of Y for the given Xi value Measures of Variation (continued) SST = total sum of squares Measures the variation of the Yi values around their mean Y SSR = regression sum of squares Explained variation attributable to the relationship between X and Y SSE = error sum of squares Variation attributable to factors other than the relationship between X and Y Measures of Variation (continued) Y Yi SSE = (Yi - Yi )2 Y _ Y SST = (Yi - Y)2 _ SSR = (Yi - Y)2 _ Y Xi _ Y X Coefficient of Determination, r2 The coefficient of determination (决定系数) is the portion of the total variation in the dependent variable that is explained by variation in the independent variable The coefficient of determination is also called r-squared and is denoted as r2 SSR regression sum of squares r SST total sum of squares 2 note: 0 r 1 2 Examples of Approximate r2 Values Y r2 = 1 r2 = 1 X 100% of the variation in Y is explained by variation in X Y r2 =1 Perfect linear relationship between X and Y: X Examples of Approximate r2 Values Y 0 < r2 < 1 X Weaker linear relationships between X and Y: Some but not all of the variation in Y is explained by variation in X Y X Examples of Approximate r2 Values r2 = 0 Y No linear relationship between X and Y: r2 = 0 X The value of Y does not depend on X. (None of the variation in Y is explained by variation in X) The Simple Correlation Coefficient (简单相关系数) The simple correlation coefficient measures the strength of the linear relationship between y and x and is denoted by r r= r if b1 is positive, and 2 r= r if b1 is negative 2 Where, b1 is the slope of the least squares line r can also be calculated using the formula SS xy r SS xx SS yy Different Values of the Correlation Coefficient Inference about the Slope: t Test t test for a population slope Is there a linear relationship between X and Y? Null and alternative hypotheses H0: β1 = 0 Ha: β1 0 (no linear relationship) (linear relationship does exist) Test statistic b1 β1 t s b1 sb1 s SS xx d.f. n 2 where: b1 = regression slope coefficient β1 = hypothesized slope sb = standard 1 error of the slope Example 11.2 House Price in $1000s (y) Square Feet (x) 245 1400 312 1600 279 1700 308 1875 199 1100 219 1550 405 2350 324 2450 319 1425 255 1700 The House Price Case Simple Linear Regression Equation: house price 98.25 0.1098 (sq.ft.) The slope of this model is 0.1098 Does square footage of the house affect its sales price? The House Price Case #2 b1 β1 0.10977 0 t 3.32938 s b1 0.03297 H0: β1 = 0 Ha: β1 0 n=10 d.f. = 10-2 = 8 a/2=.025 Reject H0 a/2=.025 Do not reject H0 -tα/2 -2.3060 0 Reject H 0 tα/2 2.3060 3.329 There is sufficient evidence that square footage affects house price Confidence Interval Estimate for the Slope Confidence Interval Estimate of the Slope: b1 t n2Sb1 d.f. = n - 2 At 95% level of confidence, the confidence interval for the slope is (0.0337, 0.1858) Since the units of the house price variable is $1000s, we are 95% confident that the average impact on sales price is between $33.70 and $185.80 per square foot of house size This 95% confidence interval does not include 0. Conclusion: There is a significant relationship between house price and square feet at the .05 level of significance Chapter Summary Introduced types of regression models Reviewed assumptions of regression and correlation Discussed determining the simple linear regression equation Described measures of variation Described inference about the slope Discussed correlation -- measuring the strength of the association Addressed estimation of mean values and prediction of individual values







































































































![1 STAT 370: Probability and Statistics for y Engineers [Section 002]](http://s1.studyres.com/store/data/004155539_1-650e86b03c31606d282c23de5ae2b689-150x150.png)



