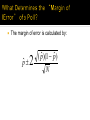Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
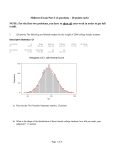
Normal Curves The family of normal curves The rule of 68-95-99.7 The Central Limit Theorem Confidence Intervals Around a Mean Around a Proportion Normal curves are a special family of density curves, which are graphs that answer the question: “what proportion of my cases take on values that fall within a certain range?” Many things in nature, such as sizes of animals and errors in astronomic calculations, happen to be normally distributed. .4 .3 .3 .3 .2 .1 .1 .1 .0 0.0 < 57.5 .0 60 - 62.5 57.5 - 60 Height in Inches 65 - 67.5 62.5 - 65 72.5 - 75 67.5 - 70 > 75 What do all normal curves have in common? How can we tell one normal curve from another? Symmetric Mean tells you where Mean = Median it is centered Standard deviation tells you how thick or narrow the curve will be Bell-shaped, with most of their density in center and little in the tails The 68-95-99.7 Rule. 68% of cases will take on a value that is plus or minus one standard deviation of the mean 95% of cases will take on a value that is plus or minus two standard deviations 99.7% of cases will take on a value that is plus or minus three standard deviations If we take repeated samples from a population, the sample means will be (approximately) normally distributed. The mean of the “sampling distribution” will equal the true population mean. The “standard error” (the standard deviation of the sampling distribution) equals N A “sampling distribution” of a statistic tells us what values the statistic takes in repeated samples from the same population and how often it takes them. We use the statistical properties of a distribution of many samples to see how confident we are that a sample statistic is close to the population parameter We can compute a confidence interval around a sample mean or a proportion We can pick how confident we want to be Usually choose 95%, or two standard errors The 95% confidence interval around a sample mean is: X 2 ̂ N whereˆ ( X X ) i N 1 2 If my sample of 100 donors finds a mean contribution level of $15,600 and I compute a confidence interval that is: $15,600 + or - $600 I can make the statement: I can say at the 95% confidence level that the mean contribution for all donors is between $15,000 and $16,200. The 95% confidence interval around a sample proportion is: pˆ 2 ( pˆ )(1 pˆ ) N And the 99.7% confidence interval would be: pˆ 3 ( pˆ )(1 pˆ ) N The margin of error is calculated by: pˆ 2 ( pˆ )(1 pˆ ) N In a poll of 505 likely voters, the Field Poll found 55% support for a constitutional convention. 0.55 2 (0.55)(1 0.55) 505 0.55 0.044 The margin of error for this poll was plus or minus 4.4 percentage points. This means that if we took many samples using the Field Poll’s methods, 95% of the samples would yield a statistic within plus or minus 4.4 percentage points of the true population parameter.