Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
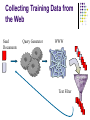
Information Extraction with Unlabeled Data Rayid Ghani Joint work with: Rosie Jones (CMU) Tom Mitchell (CMU & WhizBang! Labs) Ellen Riloff (University of Utah) The Vision training sentences answers Training Program EMPLOYEE Jan Clesius Bill Young EMPLOYER Clesius Enterprises InterMedia Inc. COMPANY Clesius Enterprises InterMedia Inc. LOCATION New York, NY Boston, MA Tables Link Analysis Models Data Base Entities Extractor Events Information Relations Extraction Geo Display J F M A M J J A Time Line What is IE? Analyze unrestricted text in order to extract information about pre-specified types of events, entities or relationships Practical / Commercial Applications Database of Job Postings extracted from corporate web paes (flipdog.com) Extracting specific fields from resumes to populate HR databases (mohomine.com) Information Integration (fetch.com) Shopping Portals Where the world is now? MUC helped drive information extraction research but most systems were fine tuned for terrorist activities Commercial systems can detect names of people, locations, companies (only for proper nouns) Very costly to train and port to new domains 3-6 months to port to new domain (Cardie 98) 20,000 words to learn named entity extraction (Seymore et al 99) 7000 labeled examples to learn MUC extraction rules (Soderland 99) IE Approaches Hand-Constructed Rules Supervised Learning Semi-Supervised Learning Goal Can you start with 5-10 seeds and learn to extract other instances? Example tasks Locations Products Organizations People Aren’t you missing the obvious? Not really! Acquire lists of proper nouns Locations : countries, states, cities Organizations : online database People: Names But not all instances are proper nouns *by the river*, *customer*,*client* Use context to disambiguate A lot of NPs are unambiguous A lot of contexts are also unambiguous “The corporation” Subsidiary of <NP> But as always, there are exceptions….and a LOT of them in this case “customer”, John Hancock, Washington Bootstrapping Approaches Utilize Redundancy in Text Noun-Phrases Contexts New York, China, place we met last time Located in <X>, Traveled to <X> Learn two models Use NPs to label Contexts Use Contexts to label NPs Algorithms for Bootstrapping Meta-Bootstrapping (Riloff & Jones, 1999) Co-Training (Blum & Mitchell, 1999) Co-EM (Nigam & Ghani, 2000) Data Set ~5000 corporate web pages (4000 for training) Test data marked up manually by labeling every NP as one or more of the following semantic categories: location, organization, person, product, none Preprocessed (parsed) to generate extraction patterns using AutoSlog (Riloff, 1996) Evaluation Criteria Every test NP is labeled with a confidence score by the learned model Calculate Precision and Recall at different thresholds Precision = Correct / Found Recall = Found / Max that can be found Seeds Results Active Learning Can we do better by keeping the user in the loop? If we can ask the user to label any examples, which examples should they be? Selected randomly Selected according to their density/frequency Selected according to disagreement between NP and context (KL divergence to the mean weighted by density) NP – Context Disagreement KL Divergence Results Results What if you’re really lazy? Previous experiments assumed a training set was available What if you don’t have a set of documents that can be used to train? Can we start from only the seeds? Collecting Training Data from the Web Use the seed words to generate web queries Simple Approaches For each seed word, fetch all documents returned Only fetch documents, where N or more seed words appear Collecting Training Data from the Web Seed Documents Query Generator WWW Text Filter Interleaved Data Collection Select a seed word with uniform probability Get documents containing that seed word Run bootstrapping on the new documents Select new seedwords that are learned with high confidence Repeat Seed-Word Density Summary Starting with 10 seed words, extract NPs matching specific semantic classes Probabilistic Bootstrapping is an effective technique Asking the user helps only if done intelligently The Web is an excellent resource for training data that can be collected automatically => Personal Information Extraction Systems