Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
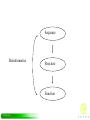
Advanced bioinformatics tools for analyzing the Arabidopsis genome Proteins of Arabidopsis thaliana (PAT) & Gene Ontology (GO) Hongyu Zhang, Ph.D. PAT project Sequence Bioinformatics Structure Function PAT project PAT: Structure-aided function annotation • PAT is a collaborating project between Ceres and San Diego Supercomputer Center: http://pat.sdsc.edu • Importance of structure-aided function annotation – Structure contains more function information than sequence, like active site, binding motif etc. – Structure is more conserved than sequence during evolution, therefore protein sequences can have similar structures even without clearly detected sequence similarity. It means that we have bigger chance to find the function relationship from structure similarity than from sequence similarity using advanced structure prediction programs like PSI-BLAST and threading algorithm. – Structure prediction programs can also be used to predict all sorts of structure features of proteins, like trans-membrane tendency, electrostatics potential distribution, or coil-coil fold tendency. Those structure features are also valuable to biologists to guess the possible functions of novel genes. PAT project Fold recognition • Frequently implies biochemical function number of folds 600 500 400 300 200 100 0 1 2 3 number of different functions PAT project 4 Highlights in PAT annotations • Domain-based prediction – Structure domain • PDB, SCOP – Sequence domain • Pfam • Predictions are strictly benchmarked PAT project Reliability categories Category Reliable level Benchmark A Certain >99.9% B Reliable >99% C Probable >90% D Possible >50% E Potential >10% PAT project Methods • Programs Protein sequences were analyzed using a spectrum of programs, including structure prediction, function prediction and feature annotation methods. • Database All the results were organized and stored in an Oracle relational database for the ease of data access and process. • Interface Web-based interface convenient for both computational and noncomputational biologist users. PAT project Programs used in PAT pipeline • Protein structure and function – Homology modeling BLAST, PSI-BLAST search against protein structure database – Threading 123D+ search against a protein fold library • Protein class and features COILS, TMHMM, SignalP, PSI-pred, PSORT PAT project structure info SCOP, PDB Building FOLDLIB: PDB chains SCOP domains PDP domains CE matches PDB vs. SCOP 90% sequence non-identical minimum size 25 aa coverage (90%, gaps <30, ends<30) sequence info NR, PFAM Protein sequences Prediction of : signal peptides (SignalP, PSORT) transmembrane (TMHMM, PSORT) coiled coils (COILS) low complexity regions (SEG) Create PSI-BLAST profiles for Protein sequences Structural assignment of domains by PSI-BLAST on FOLDLIB Only sequences w/out A-prediction Structural assignment of domains by 123D on FOLDLIB Only sequences w/out A-prediction Functional assignment by PFAM, NR, PSIPred assignments FOLDLIB Domain location prediction by sequence Store assigned regions in the DB PAT project GUI:Top Level PAT project Example: P450 family • Sequence relatives detected by ordinary Blast search – 313 hits, when E-score cutoff is 0.001 – 324 hits, when E-score cutoff is 0.01 • Sequence relatives detected by PAT – 367 hits with confidence greater or equal to 99% PAT project Figure 2. SCOP results, super-family level. It displayed the number of true positive predictions versus the number of false positive predictions for the SCOP test set. Here, if two proteins share the first three SCOP sccs ids, e.g., d.126.1.1 and d.126.1.2, they are considered having the same structure in super-family level. The results in this figure displayed that PSI-BLAST are superior than both NCBIBLAST and WU-BLAST in picking up the true positives. PAT project Acknowledgement • • • • • PAT project Dr. Nickolai Alexandrov Dr. Philip E. Bourne Dr. Wilfred W. Li Dr. Greg B. Quinn Dr. Ilya E. Shindyalov Gene Ontology (GO) project • Gene Ontology Consortium (http://www.geneontology.org) • Controlled vocabularies for the description of gene functions. • Three dimensions – Molecular Function • the tasks performed by individual gene products; examples are transcription factor and DNA helicase – Biological Process • broad biological goals, such as purine metabolism or mitosis, that are accomplished by ordered assemblies of molecular functions – Cellular Component • subcellular structures, locations, and macromolecular complexes; examples include nucleus, telomere, and origin recognition complex PAT project Three dimensions of GO Biological process Gene product Molecular Function Cellular Component PAT project Hierarchical structure of GO term tree .GO:0003673 : Gene_Ontology .GO:0003674 : molecular_function .GO:0005488 : binding .GO:0003676 : nucleic acid binding .GO:0003677 : DNA binding .GO:0003700 : transcription factor .GO:0030528 : transcription regulator .GO:0003700 : transcription factor PAT project The evidence codes used in GO • IC inferred by curator • • IDA inferred from direct assay IEA inferred from electronic annotation • • IEP inferred from expression pattern IGI inferred from genetic interaction • • IMP inferred from mutant phenotype IPI inferred from physical interaction • • ISS inferred from sequence or structural similarity NAS non-traceable author statement • • ND no biological data available TAS traceable author statement • NR not recorded PAT project Process to annotate Ceres peptide • Download GO annotations from TAIR website (http://www.arabidopsis.org) • Annotating methods If the sequence of the Ceres peptide is the same as a GO database sequence based on locus name, copy all the annotations of the GO database sequence to the Ceres peptide. Else For each Ceres peptide, pick up its best hit that does have the TAIR annotation, and then copy its annotation to this Ceres peptide. PAT project Example: P450 family • Sequence relatives detected by simple Blast search – 313 hits, when E-score cutoff is 0.001 – 324 hits, when E-score cutoff is 0.01 • Sequence relatives detected by PAT – 367 hits with confidence greater or equal to 99% • Sequence relatives annotated by GO – 365 hits – Number of Hits based on evidence • 295 with ISS (inferred from sequence or structural similarity) • 67 with IEA (inferred from electronic annotation) • 2 with TAS (traceable author statement) • 1 with IDA (inferred from direct assay) PAT project Acknowledgement • Dr. Nickolai Alexandrov • Mr. Eric Zetterbaum • Dr. Richard Flavell • etc. PAT project