Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Pathogenomics wikipedia , lookup
Minimal genome wikipedia , lookup
Whole genome sequencing wikipedia , lookup
Genomic library wikipedia , lookup
Human genome wikipedia , lookup
Oncogenomics wikipedia , lookup
Genome evolution wikipedia , lookup
Public health genomics wikipedia , lookup
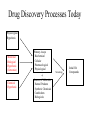
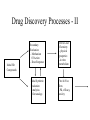
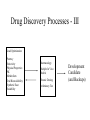
Pharm 202 “Digitally Enabled Genomic Medicine” and Its Role in Cancer Treatment Phil Bourne [email protected] http://www.sdsc.edu/pb -> Courses -> Pharm 202 Take Home Message • We are undergoing a revolution in our approach to treating disease • This has been driven by the human genome project and the technologies that go with it • A key element is the integration of information derived from genotype to phenotype • Much of this information is now digital rather than analog • This is much more than faster ways to develop drugs – it has to do with diagnostic treatments, preventive medicine, personalized medicine • Remember the two applications associated with cancer treatment Today • Overview of the revolution • Drug discovery specifically • The much more part as it relates to cancer – Improve the outcomes of radiotherapy in treatment of breast and prostate cancer – Predictive gene signatures to define treatments for breast cancer Approach Today • Rather than discuss specific papers of work completed we will take a broader perspective on proposed work on large scale projects that have the potential to impact people’s lives through digitally enabled genomic medicine • The grants we have studied are from Genome Canada and should be treated as confidential REPRESENTATIVE DISCIPLINE EXAMPLE UNITS Anatomy MRI Physiology Heart Cell Biology Neuron Proteomics Genomics Structure Sequence SCIENTIFIC RESEARCH & DISCOVERY Organisms Protease Inhibitor Migratory Sensors Organs Ventricular Modeling Cells Electron Microscopy Macromolecules Biopolymers Infrastructure Medicinal Chemistry REPRESENTATIVE TECHNOLOGY X-ray Crystallography Technologies Atoms & Molecules Training Protein Docking Digital vs Analog • The lower levels of biological complexity have always been digital – the higher levels analog • This made it very hard to correlate across biological scales • Some good examples of digital phenotypic data exist and it is now being collected in earnest Lower Levels – Digital (sort of) This digital image of cAMP dependant protein kinase (PKA) depicts years of collective knowledge. We can only interpret it in this form and the computer is vital Higher Levels – The Patient Record • • • • • 8% of patient records are lost They are mostly paper (analog) They can only be interpreted by humans Errors are rampant There are exceptions – tumor registries, digitized x-rays, clinical trials, the Cockrane library Drug Discovery as an Example of this Revolution • Requires a higher level of digital enablement • Has been accelerated by the genome(s) and associated technologies Discovery and Development • Discovery includes: Concept, mechanism, assay, screening, hit identification, lead demonstration, lead optimization • Discovery also includes in vivo proof of concept in animals and concomitant demonstration of a therapeutic index • Development begins when the decision is made to put a molecule into phase I clinical trials Discovery and Development • The time from conception to approval of a new drug is typically 10-15 years • The vast majority of molecules fail along the way • The estimated cost to bring to market a successful drug is now $800 million!! (Dimasi, 2000) Drug Discovery - Status Today • Somewhat digitally enabled (FDA still requires paper submission) • Will benefit from emergent technologies • Human targets are relatively well defined • Process for finding appropriate targets in other organisms is evolving • Process for finding leads is under revision (we will see an example of that) Drug Discovery Processes Today Physiological Hypothesis Molecular Biological Hypothesis (Genomics) Primary Assays Biochemical Cellular Pharmacological Physiological + Chemical Hypothesis Sources of Molecules Natural Products Synthetic Chemicals Combichem Biologicals Screening Initial Hit Compounds Drug Discovery Processes - II Initial Hit Compounds Secondary Evaluation - Mechanism Of Action - Dose Response Hit to Lead Chemistry - physical properties -in vitro metabolism Initial Synthetic Evaluation - analytics - first analogs First In Vivo Tests - PK, efficacy, toxicity Drug Discovery Processes - III Lead Optimization Potency Selectivity Physical Properties PK Metabolism Oral Bioavailability Synthetic Ease Scalability Pharmacology Multiple In Vivo Models Chronic Dosing Preliminary Tox Development Candidate (and Backups) Remains Serendipity • Often molecules are discovered/synthesized for one indication and then turn out to be useful for others – – – – Tamoxifen (birth control and cancer) Viagra (hypertension and erectile dysfunction) Salvarsan (Sleeping sickness and syphilis) Interferon-a (hairy cell leukemia and Hepatitis C) Issues in Drug Discovery • • • • • • • Hits and Leads - Is it a “Druggable” target? Resistance Pharmacodynamics and kinetics Delivery - oral and otherwise Metabolism Solubility, toxicity Patentability What has changed in identifying targets? In principle we know all the human targets The “Druggable Genome” human genome polysaccharides lipids nucleic acids proteins Problems with toxicity, specificity, and difficulty in creating potent inhibitors eliminate the first 3 categories... human genome polysaccharides lipids nucleic acids proteins proteins with binding site “druggable genome” = subset of genes which express proteins capable of binding small drug-like molecules Relating druggable targets to disease... GPCR • Over 400 proteins used as drug targets Other 110 families STY kinases Cys proteases Gated ionchannel Analysis of pharm industry reveals: Zinc peptidases Ion channels Nuclear PDE receptor Serine proteases P450 enzymes Fig. 3, Fauman et al. • Sequence analysis of these proteins shows that most targets fall within a few major gene families (GPCRs, kinases, proteases and peptidases) Remaining issues • Characterization of human proteins is ongoing (see each revision from Ensembl) • Our ability to locate coding regions is improving • Our ability to annotate putative proteins is improving • More targets will be identified The Structural Genomics Pipeline (X-ray Crystallography) Basic Steps Crystallomics • Isolation, Target • Expression, Data Selection • Purification, Collection • Crystallization Bioinformatics • Distant homologs • Domain recognition Automation Bioinformatics • Empirical rules Automation Better sources Anticipated Developments Structure Solution Structure Refinement Software integration Decision Support MAD Phasing Automated fitting Functional Annotation Publish No? Bioinformatics • Alignments • Protein-protein interactions • Protein-ligand interactions • Motif recognition From Structural Genomix • FAST™ is a proprietary lead generation technology developed by SGX for identification of novel, potent and selective small molecule inhibitors of drug targets within a rapid six-month timeframe. The FAST™ process involves crystallographic screening of lead-like drug fragments followed by structure-guided elaboration of the fragments by parallel chemical synthesis, guided by proprietary computational tools. Iterative determination of crystal structures for multiple target/compound complexes in parallel with assays, computational design and synthesis results in optimized leads with high binding affinities and low molecular weights. The combinatorial nature of FAST™ provides access to expansive chemical diversity in the order of 160 million compounds, while requiring only a small number of compounds to be synthesized and screened. Thus the FAST™ approach generates novel and potent lead compounds within months and with efficient deployment of chemistry resources. Summary • Need information flow from genotype to phenotype and back • Digital enablement provides that • The human genome and the associated technologies has accelerated this process dramatically • Example – human genome provides more targets • Example – structural genomics leads to faster identification of leads • Lets consider two examples related to cancer that illustrate this more specifically….