Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
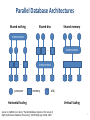
Data Management in the Cloud Data Models, Project (Lecture 2) 1 Let’s Remember… • Cloud Computing – Utility Computing – Virtualization – Economics (pay as you go) • Data management in the cloud – Cloud characteristics (elasticity if parallelizable, untrusted host, large distances) – Transactional vs. Analytical – Wish List – Map Reduce vs. Shared-Nothing -> Hybrid • DB vs. NoSQL in two lines… – Database: complex / concurrent – NoSQL: simple / scalable 2 Data Management in the Cloud (Lecture 2) SCALABLE DATA STORES 3 Overview • New systems have emerged to address requirements of data management in the cloud – so-called “NoSQL” data stores – scalable SQL databases • Horizontal Scalability – shared nothing – replicating and partitioning data over thousands of servers – distribute “simple operation” workload over thousands of servers • Simple Operations – key lookups – read and writes of one or a small number of records – no complex queries or joins 4 Parallel Database Architectures Shared nothing Shared disc Shared memory … interconnect interconnect … … processor interconnect memory disk Horizontal Scaling Source: D. DeWitt and J. Gray: “Parallel Database Systems: The Future of High Performance Database Processing”, CACM 36(6), pp. 85-98, 1992. Vertical Scaling 5 Partitioning/Sharding • Horizontal Partitioning / Sharding – Store records on different servers • Vertical Partitioning – Store parts of a single record on different servers 6 Horizontal vs. Vertical Partitioning • Horizontal Partitioning / Sharding / row-wise order server 0 (or page 0) server 1 (or page 1) server 0 ( or page 0) server 1 (or page 1) • Vertical Partitioning 7 Slide Credit: Torsten Grust, University of Tübingen, Germany Defining “NoSQL” • No agreed upon definition – “not only SQL” – “not relational” – … • Six key features 1. 2. 3. 4. 5. 6. ability to horizontally scale simple operation throughput over many servers ability to replicate and distribute (partition) data over many servers simple call level interface or protocol (in contrast to a SQL binding) weaker concurrency model than ACID transactions of most relational (SQL) database systems efficient use of distributed indexes and RAM for data storage ability to dynamically add new attributes to data records Based on: “Scalable SQL and NoSQL Data Stores” by R. Cattell, 2010 8 Data Models • Terminology – tuple: row in a relational table, where attribute names and types are defined by a schema, and values must be scalar – document: supports both scalar values and nested documents, and the attributes are dynamically defined for each document – column family: groups key/value pairs (columns) into families to partition and replicate them; one column family is similar to a document as new (nested, list-valued) attributes can be added – object: analogous to objects in programming languages, but without procedural methods • Relational – data is stored in relations (tables) of tuples (rows) of scalar values – queries expressed over arbitrary (combinations of) attributes – indexes defined over arbitrary (combinations of) attributes Based on: “Scalable SQL and NoSQL Data Stores” by R. Cattell, 2010 9 Outline: Data Models • No-SQL (in order of complexity) – Key-Value (Voldemort, Riak) – Document (SimpleDB, CouchDB) – Column-Family/Extensible Record Stores (BigTable, Hbase, Cassandra) • Other – – – – Graph (Neo4j) Array (SciDB) OODB Scalable Relational (Volt DB) 10 Key/Value Data Model k1 k2 k3 • Interface v1 v2 v3 – put(key, value) – get(key): value … kn vn • Data storage – values (data) are stored based on programmer-defined keys – system is agnostic as to the structure (semantics) of the value • Queries are expressed in terms of keys • Indexes are defined over keys – Typically primary only 11 Key/Value Systems II • Project Voldemort (LinkedIn) (2009) – Updates replicas asynchronously – no guarantee of consistent data (MVCC) – Can guarantee up-to-date if you read a majority of replicas – Optimistic locking for multi-record updates – Supports automatic sharding – Automatically detects and recovers failed nodes, automatically adapts to added/removed notes 12 Key/Value Systems II • Riak (2009) – – – – – – Open-source version of Amazon Dynamo DB “Advanced” key-value store Objects fetched / stored in JSON Lookup and indices only on primary key Sharding on primary key Symmetric architecture, no distinguished node 13 Key/Value Systems - Summary • Simple key-value lookups (“value” is opaque to system) • Scalability through key distribution over nodes • Usually persistence plus some of : replication, versioning, locking, transactions, etc… • Interface: insert, delete, lookup • Voldemort/Riak – MVCC, Redis, Scalaris, Mem* use locking… • Use Case – Simple application, one kind of object – look up on one attribute – Simple, easy to use 14 Document Data Model k1 k2 k3 “name”:“fred” “name”:“mary”;“age”:“25” “name”:“oak st” … kn • Interface – – – – set(key, document) get(key): document set(key, name, value) get(key, name): value “name”:“john”;“address”:“k3” • Data storage – documents (data) is stored based on programmer-defined keys – system is aware of the (arbitrary) document structure – support for lists and nested documents • Queries expressed in terms of key (or attribute, if index exists) • Support for key-based indexes and secondary indexes 15 Document Systems • More complex data than key-value stores • Schema: Collection (group of documents) + Attributes (name) • What is a “document”? – Can store Microsoft Word documents, but “document” is more general than that – “Document” means a “pointerless object” with structure • • • • • Usually support secondary indices Usually multiple types of documents per database Usually nested documents No ACID transaction properties SimpleDB, CouchDB, MongoDB 16 Document Systems - SimpleDB • SimpleDB (Amazon) (2007) – – – – – – – – Select, Delete, GetAttr, PutAttr Does not allow nested documents Supports eventual consistency Asynchronous replication Multiple Domains within a database Domains (databases) support multiple indices Indices automatically updated when document attrs modified Does not automatically partition (shard) data 17 Document Systems - CouchDB • CouchDB (Apache) (2008) – – – – – – – Schema is based on collections Secondary indices must be explicitly created Queries are in Javascript Indices are B-Trees Queries as Javascript => burden on users Asynchronous replication for scalability (not sharding) Queries are map-reduce views • MongoDB (10gen) (2009) – Supports automatic sharding – Replication primarily for failover – Dynamic queries with automatic use of indices 18 Document Systems - Summary • Schema-less except for attributes • Provide a mechanism to query collections based on multiple attribute constraints • Typically no explicit locks, weaker concurrency and atomicity than traditional ACID databases • Documents can be distributed over all nodes, but scalability differs – Replication (all) – Sharding (Automatic in MongoDB) • Use case – Multiple different kinds of objects – Need to look up based on multiple fields – Level of concurrency? Can you tolerate eventual consistency? 19 Key / Value vs. Document • In Key / Value databases, the “value” (“aggregate”) in the book is opaque to the database • In a Document database, the database can see the structure of the “value” (“aggregate”) • Key/Value – lookup based on key only • Document – can look up based on structure inside the document • Line is a bit blurry… 20 Data Management in the Cloud (Lecture 2) APPLICATION CHARACTERISTICS 21 Application Characteristics Aspects of applications that influence the choice of data management system PHP • Inward facing vs. outward facing • How critical is consistency? • Do answers need to be precise – Accurate data – Complete computation • Interactive vs. data analysis? What kind of response time is needed? • Does the data partition easily? 22 Application Characteristics 2 • How complex is the data? – flat records – files (e.g., audio) – nested structure • • • • • How much heterogeneity in the data? How much data is there? What is the update pattern? How sensitive and valuable is the data? How much variability in demand? 23 Application Characteristics 3 • How complex is the logic? • What is the data access pattern? – Are there hot spots and cold spots? – Is there locality of access? • How complex are the access patterns for common operations? – Single data item? – Multiple data items? – Large chunks of the data? • Can the data in use fit in memory? 24 Discussion Question Pick an online application and discuss its characteristics. Examples: Twitter, Snapchat, gmail, FaceBook, Minecraft, Healthcare.gov, Dropbox, Flickr, Instagram, Ebay, Yelp, TripAdvisor, Zillow, E*TRADE, iTunes, online banking, Amazon Three key aspects of the _____________ application: 1. 2. 3. 25 Data Management in the Cloud (Lecture 2) BACK TO … SCALABLE DATA STORES 26 Column Family Data Model Public k1 k2 k3 Private “age”:“25” “name”:“john” “title”:“Mr” – define(family) – insert(family, key, columns) – get(family, key): columns … “name”:“fred” “name”:“mary” “name”:“oak st” • Interface kn • Data storage – <name, value, timestamp> triples (so-called columns) are stored based on a column family and key; a column family is similar to a document – system is aware of (arbitrary) structure of column family – system uses column family information to replicate and distribute data • Queries are expressed based on key and column family • Secondary indexes per column family are typically supported 27 Column Family / Extensible Record Stores • BigTable, Hbase, HyperTable • BigTable (Google) – Scalability: splitting rows and columns over multiple nodes – Rows split over nodes through sharding on primary key • Typically split by range and not hash – Columns distributed over multiple nodes by using “column groups” • Customer indicates which Columns are best stored together 28 Column Family Systems – BigTable • Scalability: splitting rows and columns over multiple nodes – Horizontal and vertical partitioning • Rows split over nodes through sharding on primary key – Typically split by range and not hash • Columns distributed over multiple nodes by using “column groups” – Customer indicates which Columns are best stored together • Most extensible-record stores patterned on BigTable • HBase is open-source version (Apache) of BigTable 29 Column Family Systems – Cassandra • Facebook • Ordered hash index • Weak concurrency model, no locking, asynchronously updated replicas • Adds concept of “supercolumn” 30 Column Family Summary • Use cases similar to Document Stores – – – – Multiple kinds of objects Lookups based on any field Typically higher throughput Typically stronger concurrency guarantees 31 Graph Data Model • Interface “name”:“mary”;“age”:“25” LIKES n1 LIKES “name”:“fred” n3 “weight”:“-1” n2 – – – – – create: id get(id) connect(id1, id2): id addAttribute(id, name, value) getAttribute(id, name): value “name”:“oak st” • Data storage – data is stored in terms of nodes and (typed) edges – both nodes and edges can have (arbitrary) attributes • Queries are expressed based on system ids (if no indexes exist) • Secondary indexes for nodes and edges are supported – retrieve nodes by attributes and edges by type, start and/or end node, and/or attributes 32 Array Data Model • Nested multi-dimensional arrays – cells can be tuples or other arrays – can have non-integer dimensions • Additional “History” dimension on updatable arrays • Ragged arrays allow each row or column to have a different length • Supports multiple flavors of “null” – array cells can be “EMPTY” – user-definable treatment of special values 33 SciDB DDL CREATE ARRAY Test_Array < A: integer NULLS, B: double, C: USER_DEFINED_TYPE > [I=0:99999,1000, 10, J=0:99999,1000, 10 ] PARTITION OVER ( Node1, Node2, Node3 ) USING block_cyclic(); Attribute names Index names Chunk size Overlap A, B, C I, J 1000 10 34 Object Data Model Person “mary” 25 LIKES LIKES Person “fred” 27 • Interface – set(object) – get(query): object LIVES_AT Address “oak st” • Data storage – typed programming language objects (plus referenced objects) stored – attribute can be collection-valued – database is aware of the type (schema) of objects • Objects are retrieved using queries or by traversal from “roots” • Specialized indexes can be expressed based on schema 35 Scalable Relational Systems • • • • Complete pre-defined schema SQL Interface ACID transactions Scalability may be comparable to NoSQL data stores given: – Use small-scope operations – Use small-scope transactions – NoSQL systems avoid these issues by making it impossible to perform large-scope operations and transactions • Good if: – Complex schema – Programmers familiar with SQL – You need/want ACID transactions (what is your concurrent access pattern?) – Tools! 36 Scalable Relational Systems • MySQL Cluster (2004) – One of the earliest scalable relational systems – Shared-nothing architecture • Volt DB (2010) – – – – – – Tables partitioned over multiple servers Shared-nothing architecture Customer can chose sharding attribute Selected tables can be replicated (read-mostly data) Designed for a database that fits in (distributed) RAM Indices/record structures desinged for RAM (not disk) 37 Data Management in the Cloud COURSE PROJECT 38 Course Project • The course will be accompanied by a project that is based on a data management scenario – Task 1: Study question that will take you through a “dry run” of mapping the graph data model to a NoSQL data model and make you think about how to answer some simple queries. – Task 2: Groups of 4-5 students will pick a NoSQL system and compile a systems profile, based on papers and documentation. These profiles will be presented in class. – Task 3: Groups of 4-5 students will design a graph management and processing system based on the previously chosen NoSQL system. This time for real! – Task 4: Groups of 4-5 students implement a prototype of the graph data management and processing system. 39 Task 1: Application Design “Dry Run” • The goal of this project is to complete the following tasks – Pick a NoSQL data model and map graph data model into that model – In words or pseudo-code, describe how you would do the queries listed on the web site – Discuss how different usage profiles presented in the lecture affect the processing of these queries • Deliverable is a written report • Students will conduct this part of the project in pairs 40 Task 2: Systems Profile • Horizontally scalable data management systems – – – – – – – Riak (http://wiki.basho.com/) Project Voldemort (http://project-voldemort.com/) CouchDB (http://couchdb.apache.org/) SimpleDB (http://www.amazon.com/simpledb/) HBase (http://hbase.apache.org/) Cassandra (http://cassandra.apache.org/) OrientDB (http://www.orientechnologies.com/) • Groups of 4-5 students collaborate on a systems profile – decide in advance with who you would like to work on what 41 Task 2: Systems Profile • Data Model – Precise description of the data model, especially in terms of differences from the "standard" models presented in the lecture – Detailed summary of the basic data manipulation API, i.e. features to create, retrieve, update and delete data items. • Query Support – Supported query types, i.e. point, range, navigation, and/or arbitrary? – What is the query language of the system? Is it declarative, functional, algebraic and/or imperative? – Are queries automatically optimized? • Indexes – What index structures are available? – What can be indexed? What can be a key? What can be a value? – How are indexes managed, i.e. manually or automatically? 42 Task 2: Systems Profile • Storage – – – – – Disk or file storage In-memory (RAM) Flash or SSD Traditional database Cloud Storage (GFS, HDFS, S3) • Transactions and Concurrency Control – Does the system support transactions? – How are transactions implemented, i.e. locks, OCC, MVCC, etc.? – What consistency guarantees are given? 43 Task 2: Systems Profile • Scalability and Replication – What types of replication are supported, i.e. synchronous or asynchronous? – ... • Platform/Deployment – What cloud infrastructures are supported? – What deployment scenarios are supported, i.e. embedded, client/server, multi-core CPU, cloud, etc.? – Language bindings? – Communication protocols, i.e. JSON, REST, etc.? 44 Task 3: Application Design • Design the example data management problem in the previously profiled system – similar to Task 1, but more technical as it is based on a concrete system – consider only queries specified in the scenario – insights for other queries optional, but highly welcome and appreciated • Deliverable is a ten minute presentation in class – discuss final design and motivate the design choices made w.r.t. the requirements of the application and the capabilities of the system – give details on the mapping of data structures, planned indexes, and query implementation strategies • Same groups of 4-5 students will continue to collaborate 45 Task 4: Prototype Implementation • Implement a small prototype based on previous design – data model (with data loading capabilities) – three queries mentioned before • The goal of this part of the project is to realize of a small application and experience its performance in practice • Alternative Option: If you feel you lack implementation experience to complete this task, you may contribute to "benchmarking" the systems built by your peers • Deliverable is the developed source code by the students • The same groups of 4-5 students continue to collaborate 46 References • M. Armbrust, A. Fox, R. Griffith, A. D. Joseph, R. H. Katz, A. Konwinski, G. Lee, D. A. Patterson, A. Rabkin, I. Stoica, M. Zaharia: Above the Clouds: A Berkeley View of Cloud Computing. Tech. Rep. No. UCB/EECS-2009-28, 2009. • D. J. Abadi: Data Management in the Cloud: Limitations and Opportunities. IEEE Data Eng. Bull. 32(1), pp. 3—12, 2009. • R. Agrawal, A. Ailamaki, P. A. Bernstein, E. A. Brewer, M. J. Carey, S. Chaudhuri, A. Doan, D. Florescu, M. J. Franklin, H. Garcia‐ Molina, J. Gehrke, L. Gruenwald, L. M. Haas, A. Y. Halevy, J. M. Hellerstein, Y. E. Ioannidis, H. F. Korth, D. Kossmann, S. Madden, R. Magoulas, B. Chin Ooi, T. O’Reilly, R. Ramakrishnan, S. Sarawagi, M. Stonebraker, A. S. Szalay, G. Weikum: The Claremont Report on Database Research. 2008. • R. Cattell: Scalable SQL and NoSQL Data Stores. SIGMOD Rec. 39(4), pp. 12—27, 2010. 47