Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
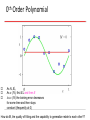
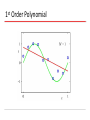
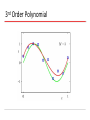
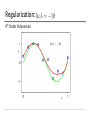
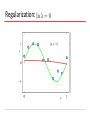
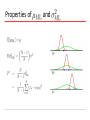
Source: Bishop book chapter 1 with modifications by Christoph F. Eick PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 1: INTRODUCTION Polynomial Curve Fitting Experiment: Given a function; create N training example What M should we choose?Model Selection Given M, what w’s should we choose? Parameter Selection Sum-of-Squares Error Function 0th Order Polynomial As N, E As c (H), first E and then E As c (H) the training error decreases for some time and then stays constant (frequently at 0) How do M, the quality of fitting and the capability to generalize relate to each other?? 1st Order Polynomial 3rd Order Polynomial 9th Order Polynomial Over-fitting Root-Mean-Square (RMS) Error: Polynomial Coefficients Data Set Size: 9th Order Polynomial Data Set Size: 9th Order Polynomial Increasing the size of the data sets alleviates the over-fitting problem. Regularization Penalize large coefficient values Idea: penalize high weights that contribute to high variance and sensitivity to outliers. Regularization: 9th Order Polynomial Regularization: Regularization: vs. The example demonstrated: As N, E As c (H), first E and then E As c (H) the training error decreases for some time and then stays constant (frequently at 0) Polynomial Coefficients Weight of regularization increases Probability Theory Apples and Oranges Probability Theory Marginal Probability Joint Probability Conditional Probability Probability Theory Sum Rule Product Rule The Rules of Probability Sum Rule Product Rule Bayes’ Theorem posterior likelihood × prior Probability Densities Cumulative Distribution Function Usually in ML! Transformed Densities Expectations (f under p(x)) Conditional Expectation (discrete) Approximate Expectation (discrete and continuous) Variances and Covariances The Gaussian Distribution Gaussian Mean and Variance The Multivariate Gaussian Gaussian Parameter Estimation Likelihood function Compare: for 2, 2.1, 1.9,2.05,1.99 N(2,1) and N(3.1) Maximum (Log) Likelihood Properties of and Curve Fitting Re-visited Maximum Likelihood Determine by minimizing sum-of-squares error, . Predictive Distribution Skip initially Model Selection Cross-Validation Entropy Important quantity in • coding theory • statistical physics • machine learning Entropy Coding theory: x discrete with 8 possible states; how many bits to transmit the state of x? All states equally likely Entropy Entropy In how many ways can N identical objects be allocated M bins? Entropy maximized when Entropy Differential Entropy Put bins of width ¢ along the real line Differential entropy maximized (for fixed in which case ) when Conditional Entropy The Kullback-Leibler Divergence Mutual Information