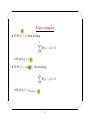
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Degrees of freedom (statistics) wikipedia , lookup
Sufficient statistic wikipedia , lookup
Renormalization group wikipedia , lookup
Foundations of statistics wikipedia , lookup
Taylor's law wikipedia , lookup
Bootstrapping (statistics) wikipedia , lookup
Resampling (statistics) wikipedia , lookup
Misuse of statistics wikipedia , lookup
'
$
Chapter 6
Robust statistics for location and scale
parameters
&
%
1
'
$
Why do we need robust statistics?
• There may be outliers in the data
– outliers are sample values that are considered very different
from the majority of the sample
• The data may depart from the underlying distribution
assumptions
&
%
2
'
$
What is a robust statistics
• A statistical method is robust if the statistic is insensitive to
slight departures from the assumptions that justify the use of
the statistic.
• We shall see some robust statistics for location and scale
parameters rather than going into the details.
• The robustness of a robust statistic can be measured by
measures such as breakdown point, influence curve and gross
error sensitivity.
&
%
3
'
$
Location estimator: trimmed mean
• It is the mean of the central 1 − 2α(0 < α < 1) part of the
distribution, so [αn] largest observations and [αn] smallest
observations are removed where [a] denotes the nearest integer
of a.
• 2α trimmed mean is defined as
ȳTα
1
=
n − 2[nα]
∑
n−[nα]
y(i)
i=[nα]+1
where y(1) , y(2) , ...y(n) are the ordered values of y1 , y2 , , ....yn .
They are also known as order statistics.
• For example, (y1 , y2 , y3 , y4 ) = (4, 5, 2, 3). Then
(y(1) , y(2) , y(3) , y(4) ) = (2, 3, 4, 5).
&
%
4
'
$
Winsorized mean
• The 2α Winsorized mean is defined as
ȳw,α
1
= [([nα] + 1)y([nα]+1) +
n
∑
n−[nα]−1
y(i) + ([nα] + 1)y(n−[nα])) ]
i=[nα]+2
• The winsorized mean is computed after all the [nα] smallest
observations are replaced by y([nα]+1) , and the [nα] largest
observations are replaces by y(n−[nα])) .
&
%
5
'
$
M-estimators for location
• Find µ which minimizes
n
∑
(yi − µ)2
i=1
• The solution is :µ̂ =
1
n
∑n
i=1
yi = ȳ
• In general, we may find µ which minimizes
n
∑
ρ(yi − µ)
i=1
where ρ is some meaningful function
&
%
6
'
$
M-estimators for location
• To minimize, we differentiate with respect to µ and equate the
derivative to 0 and solve the equation:
n
∑
ρ′ (yi − µ) = 0
i=1
• M-estimator of location parameter µ is defined as the solution
of the equation
n
∑
Ψ(yi − µ) = 0
i=1
for some function Ψ(x)
&
%
7
'
$
Some examples
• If Ψ(x) = x, then solving
n
∑
Ψ(yi − µ) = 0
i=1
will give µ̂ = ȳ.
• If Ψ(x) = sign(x), then solving
n
∑
Ψ(yi − µ) = 0
i=1
will give µ̂ = ymedian .
&
%
8
'
$
Other M-estimators
• Metrically trimmed mean
x, |x| < c,
Ψ(x) =
0, otherwise .
• Metrically winsorized Mean (Huber)
−c, x < −c,
Ψ(x) =
x, |x| < c,
c, x > c.
&
%
9
'
$
Other M-estimators
• Tukey’s bisquare:
x 22
Ψ(x) = x[1 − ( ) ]+ ,
R
where [u]+ = max{u, 0}. R=4.685 is most efficient for normal
distribution.
• Humpel’s Ψ function
|x|, 0 < |x| < a,
a, a < |x| < b,
Ψ(x) =
c−|x|
a(
c−b ), b < x < c,
0, |x| > c,
&
%
10
'
$
Robust measures of scale parameter
• The sample standard deviation is a commonly used estimator
of the population scale parameter, σ
• However, it is sensitive to outliers and may not remain bounded
when a single data point is replaced by an arbitrary number.
• With robust scale estimators, the estimates remain bounded
even when a portion of the data points are replaced by
arbitrary numbers.
&
%
11
'
$
Interquartile Range (IQR)
• IQR is defined as IQR=Q3 − Q1 where Q1 and Q3 are the first
and third quartiles respectively.
• For a normal distribution, the standard deviation σ can be
estimated by dividing the interquartile range by 1.34898.
&
%
12
'
$
Median Absolute Deviation (MAD)
• Most popular robust estimator of scale:
• MAD = mediani (|yi − medianj (yj )|) where the inner median,
medianj (yj ) is the median of n observations and the outer
median, mediani is the median of the n absolute values of the
deviations about the median.
• For normal distribution, 1.4826×MAD can be used to estimate
the standard deviation σ.
&
%
13
'
$
Gini’s mean difference
• Gini’s mean difference is defined as
G=
1
n
∑
|yi − yj |
i<j
2
• If the observations are from a normal distribution, then
is an unbiased estimator of the standard deviation σ.
&
√
πG/2
%
14
'
$
Two other robust estimators for scale parameter
• Rousseeuw and Croux (1992,1993) proposed two robust and
highly efficient estimators of scale
Sn = 1.192 × mediani (medianj (|yi − yj |))
Qn = 2.219 × {|yi − yj |; i < j}(h2 )
where h = [n/2] + 1 and {xk ; 1 ≤ k ≤ n}(a) is the a-th order
statistic of {x1 , x2 , ...xk }
• For small samples, a correction factor is used.
&
%
15
'
$
Robust estimators: SAS
Program
data ex6 1;
input x@@;
datalines;
2 3 4 6 8 10 12 14 18 27
;
proc univariate data=ex6 1 robustscale trimmed=0.2
winsorized=0.2;
var x;
run;
&
%
16
'
$
Partial Output
&
%
17
'
$
Partial Output
&
%
18
'
$
Robust estimators: R
># Calculate 40% Trimmed Mean
> mean(x,trim=0.2)
[1] 9
># Calculate MAD
> median(abs(x-median(x)))
[1] 5
># Calculate estimate of σ = 1.4826∗MAD
> mad(x)
[1] 7.413
># Calculate Interquartile Range
> IQR(x)
[1] 9
&
%
19
'
$
Robust estimators: SPSS
• “Analyze”→ “Descriptive Statistics”→ “Explore...”
• Move the variable to the “Dependent list”. Then click
“Statistics” and choose “M-estimator”
&
%
20