Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Wake-on-LAN wikipedia , lookup
Piggybacking (Internet access) wikipedia , lookup
Asynchronous Transfer Mode wikipedia , lookup
Computer network wikipedia , lookup
Zero-configuration networking wikipedia , lookup
Cracking of wireless networks wikipedia , lookup
IEEE 802.1aq wikipedia , lookup
Recursive InterNetwork Architecture (RINA) wikipedia , lookup
Deep packet inspection wikipedia , lookup
Distributed operating system wikipedia , lookup
List of wireless community networks by region wikipedia , lookup
Distributed firewall wikipedia , lookup
Network tap wikipedia , lookup
ENMA:
Co-operation in the corporation
Mort (Richard Mortier)
MSR-Cambridge
September 2004
Network management
…is the process of monitoring and controlling a
large complex distributed system of dumb devices
where failures are common and resources scarce
Enterprise networks are large but closely managed
No-one has the big picture!
Contrast with the Internet or university campus networks
Internet routeing uses distributed protocols
Current management tools all consider local info
Patchy SNMP support, configuration issues, sampling
artefacts, tools generate CPU and network load
This project
Building edge-based network management platform
Collect flow information from hosts, and
Combine with topology information from routeing protocols
Enable visualization, analysis, simulation, control
Avoid problems of not-quite-standard interfaces
Do the work where resources are plentiful
Management support is typically ‘non-critical’ (i.e. buggy )
and not extensively tested for inter-operability
Hosts have lots of cycles and little traffic (relatively)
Protocol visibility: see into tunnels, IPSec, etc
Problem context: Enterprise networks
Large
Geographically distributed
105 edge devices, 103 network devices
Multiple continents, 102 countries
Tightly controlled
IT department has (nearly) complete control over
user desktops and network connected equipment
Talk outline
System outline
What would it be good for?
In more detail…
Research issues
System outline
Packets
Routeing
protocol
Flows
Topology
Traffic matrix
Set of routes
Distributed
database
routes
srcs
dsts
Simulator
Visualize
Simulate
Control
Where is my traffic going today?
Pictures of current topology and traffic
In fact, where did my traffic go yesterday?
Routes+flows+forwarding rules BIG PICTURE
Keep historical data for capacity planning, etc
A platform for anomaly detection
Historical data suggests “normality”, live
monitoring allows anomalies to be detected
Where might my traffic go tomorrow?
Plug into a simulator back-end
Run multiple ‘what-if’ scenarios
Discrete event simulator, flow allocation solver
…failures
…reconfigurations
…technology deployments
E.g. “What happens if we coalesce all the
Exchange servers in one data-centre?”
Where should my traffic be going?
Close the loop: compute link weights to
implement policy goals
Allows more dynamic policies
Recompute on order of hours/days
Modify network configuration to track e.g. time of
day load changes
Might make network more efficient(~cheaper)
Where are we now?
Three major components
Flow collection
Route collection
Distributed database
Still studying feasibility
Starting to build prototypes
Data collection
Flow collection
Hosts track active flows
Used packet traces for feasibility study on (client, server)
Using low overhead event posting infrastructure, ETW
Built prototype device driver provider & user-space consumer
Peaks at (165, 5667) live and (39, 567) active flows per sec
Route collection
OSPF is link-state: passively collect link state adverts
Extension of my work at Sprint (for IS-IS and BGP); also
been done at AT&T (NSDI’04 paper)
The distributed database
Logically contains
1.
Traffic flow matrix (bandwidths), {srcs} × {dsts}
2.
…each entry annotated with current route from src to dst
N.B. src/dst might be e.g. (IP end-point, application)
Large dynamic data set suggests aggregation
Related work
{ distributed, continuous query, temporal } databases
Sensor networks
Potential starting points: Astrolabe or SDIMS (SIGCOMM’04)
Where/what/how much to aggregate?
Is data read- or write-dominated?
Which is more dynamic, flow or topology data?
Can the system successfully self-tune?
The distributed database
Construct traffic matrix from flow monitoring
Hosts can supply flows they source and sink
Only need a subset of this data to get complete traffic matrix
Construct topology from route collection
OSPF supplies topology → routes
Wish to be able to answer queries like
“Who are the top-10 traffic generators?”
“What is the load on link l?”
Easy to aggregate, don’t care about topology
Can aggregate from hosts, but need to know routes
“What happens if we remove links {l…m}?”
Interaction between traffic matrix, topology, even flow control
The distributed database
Building simulation model
OSPF data gives topology, event list, routes
Simple load model to start with (load ~ # subnets)
Precedence matrix (from SPF) reduces flow-data query set
Can we do as well/better than e.g. NetFlow?
Accuracy/coverage trade-off
How should we distribute the DB?
Just OSPF data? Just flow data? A mixture?
How many levels of aggregation?
How many nodes do queries touch?
What sort of API is suitable?
Example queries for sample applications
Research issues
Corner cases
Scalability
Robustness, accuracy
Control systems
Research issues
Corner cases
Multi-homed hosts: how best to define a flow
L4 routeing, NAT, proxy ARP, transparent proxies
(Solve using device config files, perhaps SNMP)
Scalability
Host measurement must not be intrusive (in terms of
packet latency, CPU load, network bandwidth)
Aggregators must elect themselves in such a way that they
do not implode under event load
What happens if network radically alters? E.g.
Extensive use of multicast
Connection patterns shift due to e.g. P2P deployment
Research issues
Robustness
Network management had better still work as nodes fail or
the network partitions!
Accuracy in the face of late, partial information
By accident: unmonitored hosts
By design: aggregation, more detail about local area
Inference of link contribution to cumulative metrics, e.g. RTT
Network control: modify link weights
How efficient is the current configuration anyway?
What are plausible timescales to reconfigure?
Summary
Aim to build a coherent edge-based network
management platform using flow monitoring and
standard routeing protocols
Applications include visualization, simulation, dynamic
control
Research issues include
Scalability: want to manage a 300,000 node network
Robustness: must work as nodes fail or network partitions
Accuracy: will not be able to monitor 100% of traffic
Control systems: use the data to optimize the network in
real-time, as well as just observe and simulate
Current status
Submitted HotNets paper
Prototype ETW provider/consumer driver
Studied feasibility of flow monitoring
Prototype OSPF collector & topology reconstruction
Investigating “distributed database” via simulation
Query properties
System decomposition
Questions, comments?
Backup slides
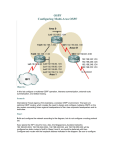
SNMP
Internet routeing
OSPF
BGP
Security
SNMP
Protocol to manage information tables at devices
Provides get, set, trap, notify operations
get, set: read, write values
trap: signal a condition (e.g. threshold exceeded)
notify: reliable trap
Complexity mostly in the table design
Some standard tables, but many vendor specific
Non-critical, so often tables populated incorrectly
Internet routeing
Q: how to get a packet from node to destination?
A1: advertise all reachable destinations and apply a
consistent cost function (distance vector)
A2: learn network topology and compute consistent
shortest paths (link state)
Each node (1) discovers and advertises adjacencies;
(2) builds link state database; (3) computes shortest paths
A1, A2: Forward to next-hop using longest-prefixmatch
OSPF (~link state routeing)
Q: how to route given packet from any node to
destination?
A: learn network topology; compute shortest paths
For each node
Discover adjacencies (~immediate neighbours); advertise
Build link state database (~network topology)
Compute shortest paths to all destination prefixes
Forward to next-hop using longest-prefix-match (~most
specific route)
BGP (~path vector routeing)
Q: how to route given packet from any node to destination?
A: neighbours tell you destinations they can reach; pick cheapest
option
For each node
Receive (destination, cost, next-hop) for all destinations known to
neighbour
Select among all possible next-hops for given destination
Advertise selected (destination, cost+, next-hop') for all known
destinations
Selection process is complicated
Routes can be modified/hidden at all three stages
General mechanism for application of policy
Security
Threat: malicious/compromised host
Threat: DoS on monitors
Authenticate participants
Must secure route collector as if a router
Difference between client under DoS and server?
Rate pace output from monitors
Threat: eavesdropping
Standard IPSec/encryption solutions