Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
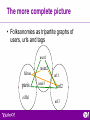
Making the Web searchable, or the Future of Web Search Peter Mika Yahoo! Research Barcelona Overview • Why a new vision? • Context – Semantic Web: metadata infrastructure – Web 2.0: user-generated metadata • Thesis: making the Web searchable • Research challenges (SW & IR) • Conclusion Motivation 1. State of Web search • Picked the low hanging fruit – Heavy investments, marginal returns – High hanging fruits • Hard searches remain… 2. The Web has changed… Hard searches • Ambiguous searches – Paris Hilton • Multimedia search – Images of Paris Hilton • Imprecise or overly precise searches – Publications by Jim Hendler – Find images of strong and adventurous people (Lenat) • Searches for descriptions – Search for yourself without using your name – Product search (ads!) • Searches that require aggregation – Size of the Eiffer tower (Lenat) – Public opinion on Britney Spears • Queries that require a deeper understanding of the query, the content and/or the world at large – Note: some of these are so hard that users don’t even try them any more Example… The Semantic Web (1996-…) • Making the content of the Web machine processable through metadata – Documents, databases, Web services • Active research, standardization, startups – Ontology languages (RDF, OWL family), query language for RDF (SPARQL) – Software support (metadata stores, reasoners, APIs) Problem: difficulties in deployment • Not enough take-up in the Web community at large – Technological challenges • Discovery • Ontology learning • Ontology mapping – Lack of attention to the social side • Over-estimating complexity for users • Need for supporting ontology creation and sharing Focus shifts from documents to databases -the Web of Data Enterprise/closed community applications Web 2.0 (2003-) • Simple, nimble, socially transparent interfaces • Simplified KR – e.g. tagging, microformats, Wikipedia infoboxes In exchange for a better experience, users are willing to • • • • • Provide content, markup and metadata Provide data on themselves and their networks Rank, rate, filter, forward Develop software and improve your site … Problem: lack of foundations • No shared syntax or semantics • No linking mechanism • Example: tag semantics – flickr:ajax = del.icio.us:ajax ? – flickr:ajax:Peter = flickr:ajax:John ? – flickr:ajax:Peter:1990 = flickr:ajax:Peter:2006 ? • Microformats – Separate agreement required for each format Thesis: making the Web searchable • The Web has changed – Content owners are interested in their content to be found (Web 2.0) • Cf. findability (Peter Morville), reusability (mashups), open data movement – Foundations are laid for a Semantic Web • We need to – Combine the best of Web 2.0 and the Semantic Web – Reconsider Web IR in this new world Semantic Web 2.0 • Getting the representation right – RDF++ – RDFa (RDF-in-HTML) • Innovations on the interface side – Semantic Wikis • New methods of reasoning – Semantics = syntax + statistics • Bottom-up, emergent semantics • Methods of logical reasoning combined with methods of graph mining, statistics – Scalability • Giving up soundness and/or completeness – Dealing with the mess • Social engineering – Collaborative spaces for creating and sharing ontologies, data – Connecting islands of semantics – Best practices, documentation, advocacy Example: Freebase Example: machine tags Example: folksonomies • Simplified view: “tags are just anchortext” hilton paris eiffel url1 url2 url3 • Can be used to generate simple cooccurrence graphs The more complete picture • Folksonomies as tripartite graphs of users, urls and tags user1 hilton paris eiffel user2 url1 user3 url2 url3 Community-based ontology mining • Opportunities for mining communityspecific interpretations of the world • Peter Mika. Ontologies are us: A unified model of social networks and semantics. Journal of Web Semantics 5 (1), page 5-15, 2007 Web IR 2.0 • Keep on improving machine technology – NLP – Information Extraction • Exploit the users for the tasks that are hard for the machine – Encourage and support users – Exploit user-generated metadata in any shape or form • Support standards of the SW architecture Vision: ontology-based search • Query: at the knowledge level – Partial description of a class/instance • Mapping of queries and resources in the conceptual space – Computing relevance in semantic terms • Novel user interfaces Ideal world • Plenty of precise metadata to harvest • User intent can be captured directly as a SPARQL query • Single ontology used both by the query and the knowledge base • Executed on a single knowledge base, gives the correct, single answer Technical challenges • Query interface • Data quality – Cleaning up metadata, tags – Spam • Ontology mapping and entity resolution • Ranking across types • Results display – How do you avoid information overload? – How do you display information you partially understand? Social challenges • Getting the users on your side – Users are unwilling to submit large amounts of structured data to a commercial entity (Google Base) – Provide a clear motivation and/or instant gratification • Trust them… but not too much (Mahalo) Example: Technorati and microformats http://technorati.com/posts/tag/semanticweb <a href="http://technorati.com/tag/semweb" rel="tag">Semantic Web</a> Example: openacademia.org and RDFa <span class="foaf:Person" property="foaf:name" about="#peter_mika"> Peter Mika </span> Conclusion • Why a new vision? • The opportunity: convergence – Semantic Web: metadata infrastructure – Web 2.0: user-generated metadata • Thesis: making the Web searchable • Research challenges What is there to gain? • Knowledge-based search – Sorting out hard searches – Creating new information needs • Beyond search – Analysis, design, diagnosis etc. on top of aggregated data • Personalization – Rich user profiles • Monetization – No more “buy virgins on eBay” Questions? • • Peter Mika. Social Networks and the Semantic Web. Springer, July, 2007. Special Issue on the Semantic Web and Web 2.0, Journal of Web Semantics, December, 2007.