Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Text Analytics Using JMP®
Melvin Alexander - Social Security Administration
JMP 12 Roadshow
Rockville MD
June 4, 2015
Disclaimer
• The views expressed in this presentation are
those of the presenters and do not necessarily
represent the views of the Social Security
Administration(SSA) or SAS Institute, Inc.
•
•
•
•
•
Agenda
Purpose: Help MAJUG leadership plan better
meetings from feedback comments using text
analytic tools of JMP®
Review MAJUG meeting data and text-analytic
methods
Demonstrate text mining techniques with JMP JSL
and other analytical tools and utilities (e.g., JMP®
free-text analyses from the Analyze > Consumer
Research > Categorical Platform, JSL commands,
SVD matrix function, Analyze platforms, etc.)
Summary and Conclusions
Q&A
Text Mining/Text Analytics
• Text mining: “refers to the process of deriving highquality information from text…through the devising
of patterns and trends through means such
as statistical pattern learning.”
• Text analytics: ”a set of linguistic, statistical,
and machine learning techniques that model and
structure the information content of textual sources
for business intelligence, exploratory data
analysis, research, or investigation”
Source: http://en.wikipedia.org/wiki/Text_mining#Text_mining_and_text_analytics (accessed 03/31/2015)..
4
Text Mining Flow
Define
Problem
Statement
•
•
Determine clear study objectives and end-state
Identify relevant data sources to answer research questions
Get and
Extract Data
•
•
•
Scrape internet with web crawling and social media tools
Extract text from disparate file types (pptx, doc, txt, pdf, html)
Strip off code, figures, extraneous characters
Parse and
Filter Text
•
•
•
Clean manually with character functions, queries, filters, R&R
Remove punctuation, numbers, stop words
Stem and tokenize text, change to lowercase, identify multiwords.
Transform
Text
•
•
•
Create document term matrix
Weight matrix based on analysis objectives
Use Singular Value Decomposition to get structured data
Structure
and Explore
Text
•
•
•
Discover topics and common themes
Group like documents and words
Subset documents and link concepts
Visualize
and Analyze
Text
•
•
•
Combine with structured data
Visualize exploitable patterns
Understand sentiments and trends
WH Rushing, J Wisnowski, “Harness the Power of Text Mining: Analyse FDA Recalls and Inspection Observations, Discovery Summit –
5
Europe: Brussels, March 24, 2015, https://community.jmp.com/docs/DOC-7204 (accessed 03/19/2015).
MAJUG meetings
are held three or
four per year
and posted on the
www.majug.com
website.
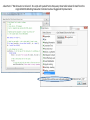
MAJUG Meeting Evaluation Form
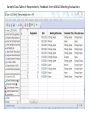
Sample Data Table of Respondent’s Feedback from MAJUG Meeting Evaluations
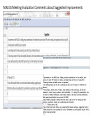
MAJUG Meeting Evaluation Comments about Suggested Improvements
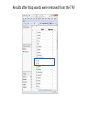
Select Where Clause using a stopwords list from the Term Frequency Vector (TFV)
Results after Stop words were removed from the TFV
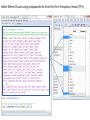
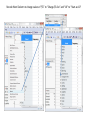
Recode Word Column to change values of “$5” to “Charge-$5-fee” and “10” to “Start-at-10”
Create single string of comma-separated words from the TFV . This string would be copied and pasted into Julian
Parris’ “Text Column” role of his “Word Counts for k words as columns” JSL script
Julian Parris’ “Word Counts to Columns” JSL script with pasted Terms Frequency Data Table Subset formed from the
original MAJUG Meeting Evaluation Comments about Suggested Improvements
Terms Frequency Data Table Subset formed from the original MAJUG Meeting Evaluation Comments about
Suggested Improvements
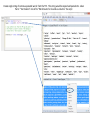
JSL script that created the Term-Document-Matrix(TDM) and Document-Term-Matrix (DTM)
//:*/
A = Data Table ( "Terms Matrix" );
/*:
Data Table( "Terms Matrix" )
//:*/
DTM=A << Get As Matrix ;
/* B Transposes DTM to form Term-Document-Matrix (TDM) */
B = DTM` ;
/*:
[1 0 0 2 0 0 0 0 0 1 0, 0 0 0 0 0 0 0 0 2 1 0,
0 0 1 2 0 0 0 0 0 0 0, 2 0 0 1 0 0 0 0 0 0 0,
0 0 2 1 0 0 0 0 0 0 0, 0 0 1 0 1 0 0 0 0 1 0,
0 0 1 1 0 0 0 0 1 0 0,
etc.
0 0 0 1 0 0 0 0 0 0 0, 1 0 0 0 0 0 0 0 0 0 0,
1 0 0 0 0 0 0 0 0 0 0, 0 0 0 1 0 0 0 0 0 0 0,
0 0 0 1 0 0 0 0 0 0 0, 0 0 0 1 0 0 0 0 0 0 0,
0 1 0 0 0 0 0 0 0 0 0, 1 0 0 0 0 0 0 0 0 0 0]
JSL scripts to compute Log Term Frequency Weights replacing raw frequencies with their logs
//Raw
B = DTM` ;
// log base10
D = J(Nrow(B),NCol(B),0);
For( i = 1, i <= n, i++,
For( j = 1, j <= p, j++,
if(B[i, j]>0, D[i,j] = 1 +log10(B[i,j]),D[i,j] = 0 );
) );
show(D);
// log base2
C= J(Nrow(B),Ncol(B),0);
For( i = 1, i <= NRow(B), i++,
For( j = 1, j <= NCol(B), j++,
C[i,j] = log(B[i,j]+1,2);
) );
show(C);
B=
[1 0 0 2 0 0 0 0 0 1 0,
0 0 0 0 0 0 0 0 2 1 0,
0 0 1 2 0 0 0 0 0 0 0,
2 0 0 1 0 0 0 0 0 0 0,
… etc. …
1 0 0 0 0 0 0 0 0 0 0];
D=
[1 0 0 1.30102999566398 0 0 0 0 0 1 0,
0 0 0 0 0 0 0 0 1.30102999566398 1 0,
0 0 1 1.30102999566398 0 0 0 0 0 0 0,
1.30102999566398 0 0 1 0 0 0 0 0 0 0,
… etc. …
1 0 0 0 0 0 0 0 0 0 0];
C=
[1 0 0 1.58496250072116 0 0 0 0 0 1 0,
0 0 0 0 0 0 0 0 1.58496250072116 1 0,
0 0 1 1.58496250072116 0 0 0 0 0 0 0,
1.58496250072116 0 0 1 0 0 0 0 0 0 0,
… etc. …
1 0 0 0 0 0 0 0 0 0 0];
SVD Formula Definition
TDM[t x d] = U[t x r] D[r x r] VT[r x d]
d
t
TDM:
txd
(t terms, d
documents)
sparsetermdocumentmatrix
r
t
=
U:
txr
(t terms, r
concepts)
left-singular
x
{LS}, rankreduced
eigenvector
term matrix
r
r
x
D:
r x r (r rank of
matrix; strength
of each ‘concept’)
diagonal {D}
matrix of singular
eigenvalues
d
r
x
V T:
r x d (r
concepts, d
documents)
right-singular
{RS}, rankreduced
eigenvector
document
matrix
JSL script snippet that created the Singular Value Matrices(LS, RS) and Eigenvalues (D) from the SVD function
//:*/
{LS,D,RS}= SVD(B); /* singular value decomposition of B = LS*D*RS` */
/*:
{[0.378096662351085 0.131824388966428 0.0211184899994071 0.10589219870066
0.180893870586793 - 0.249947997346168 0 0 - 0.0598591783533297
0.132522620357014 0, 0.0331182960691775 - 0.0292243730113285
0.337183161237851 0.583127882442963 0.125047226003007 0.154020292284754 0
0 0.16821759320533 - 0.185471956068679 0, 0.350648279538604 0.163307416493917 - 0.00534077688514531 - 0.0449366248671385 0.190147431306457 - 0.0225114783847062 0 0 0.142431314885967 0.68019673189248 0, 0.2492189633787 0.419512224556798 0.0192515782022323 0.0343837845368551 -0.0279803345343858 0.0579557417687915 0 0
etc.
0 0 0 0 0 0 0 0 0 - 1 0, 0 0 0 0 0 0 0 0 1 0 0, 0 0 0 0 0 0 0 1 0 0 0,
0.0511449194105313 - 0.0617494272704414 0.375812713862112
0.725075996234368b0.0094742784022233 0.571411451830774 0 0 0 0 0,
0.0931094176656951 0.00702825750170741 0.404132013103739
0.379678618426814 0.32464030058507 -0.76053361389797 0 0 0 0 0, 0 0 0 0 0 0 0 0
0 0 1]}
JSL scripts to create Principal Components and Left Singular Value (SVD) Data Tables
Bi-plots of Principal Components (PC2 by PC1) and SVDs (SVD2 by SVD1)
Theme 1
Theme 1
1
1
2
2
3
3
Conclusions
•
•
•
•
JMP’s Free-Text tools captured the essence of text
meanings from MAJUG-meeting participants more
analytically.
The Principal Components, SVDs provided inputs
to estimate probability models, enabling further
exploration
Employing these JMP tools will eventually lead to
greater satisfaction, and added value to MAJUG
attendees at future meetings.
That’s a worthy goal Users Group leaders all want
to achieve.
References
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
Albright, R (2004), “Taming Text with the SVD”, Cary, NC: SAS Institute, Inc. ,
ftp://ftp.dataflux.com/techsup/download/EMiner/TamingTextwiththeSVD.pdf (accessed
03/06/2015).
Alexander, M and Klick, J (2014), “Text Mining Feedback Comments from JMP® Users Group
Meeting Participants” , https://community.jmp.com/docs/DOC-6748 (accessed 02/13/2015).
Bogard, M (2012), “An Intuitive Approach to Text Mining with SAS IML”,
http://econometricsense.blogspot.com/2012/05/intuitive-approach-to-text-mining-vis.html
(accessed 02/13//2015).
Hastie, T, Tibshirani, R, and Friedman, J (2009), The Elements of Statistical Learning: Data Mining,
Inference, and Prediction, 2nd ed. New York: Springer-Verlag,
Karl, A, and Rushing, H (2013) “Text Mining with JMP and R”,
http://www.jmp.com/about/events/summit2013/resources/Paper_Karl_Rushing.pdf (accessed
02/26/2015).
McNeill, F (2014) “The Text Frontier – SAS Blog”, http://blogs.sas.com/content/text-mining/
(accessed 02/26/2015).
Mroz, P (2014) “Word Cloud in Graph Builder?” , https://community.jmp.com/thread/58441
(accessed 03/24/2015).
Rushing, H and Wisnowski, J (2015), “Harness the Power of Text Mining: Analyse FDA Recalls and
Inspection Observations”, https://community.jmp.com/docs/DOC-7204 (accessed03/19/2015)
Parris, J (2014), “Word Counts to Columns”, https://community.jmp.com/docs/DOC-7056 (accessed
02/13/2015).
Porter, MF (2006), “The Porter Stemming Algorithm”, http://tartarus.org/martin/PorterStemmer/
(accessed 02/26/2015).
Wicklin, R (2015), “Compute the rank of a matrix in SAS”,
http://blogs.sas.com/content/iml/2015/04/08/rank-of-matrix.html (accessed 04/08/2015).
Sall, J (2015), “Wide data discriminant analysis,”
http://blogs.sas.com/content/jmp/2015/05/11/wide-data-discriminant-analysis/ (accessed
05/11/2015).
Acknowledgements
(Thanks to the following for their help with this presentation)
Josh Klick
SAS Institute, Inc:
Robin Moran
Gail Massari
Tom Donnelly
John Sall & JMP‘s Development/Support Team
Lucia Ward-Alexander
Questions?
Contact:
[email protected]
JMP, SAS, and all other SAS Institute Inc. product or service names are registered trademarks or
trademarks of SAS Institute Inc. in the USA and other countries. ® indicates USA registration.
Other brand and product names are trademarks of their respective companies.