Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Pattern recognition wikipedia , lookup
Numerical weather prediction wikipedia , lookup
Predictive analytics wikipedia , lookup
Theoretical ecology wikipedia , lookup
Psychometrics wikipedia , lookup
History of numerical weather prediction wikipedia , lookup
General circulation model wikipedia , lookup
Regression analysis wikipedia , lookup
Computer simulation wikipedia , lookup
Generalized linear model wikipedia , lookup
Least squares wikipedia , lookup
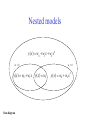
Testing models against data Bas Kooijman Dept theoretical biology Vrije Universiteit Amsterdam [email protected] http://www.bio.vu.nl/thb master course WTC methods Amsterdam, 2005/11/02 Kinds of statistics 1.2.4 Descriptive statistics sometimes useful, frequently boring Mathematical statistics beautiful mathematical construct rarely applicable due to assumptions to keep it simple Scientific statistics still in its childhood due to research workers being specialised upcoming thanks to increase of computational power (Monte Carlo studies) Tasks of statistics 1.2.4 Deals with • estimation of parameter values, and confidence of these values • tests of hypothesis about parameter values differs a parameter value from a known value? differ parameter values between two samples? Deals NOT with • does model 1 fit better than model 2 if model 1 is not a special case of model 2 Statistical methods assume that the model is given (Non-parametric methods only use some properties of the given model, rather than its full specification) Nested models y ( x) w0 w1 x w2 x 2 w2 0 y( x) w0 w1 x Venn diagram w1 0 y( x) w0 y ( x) w0 w2 x 2 Testing of hypothesis Error of the first kind: reject null hypothesis while it is true Error of the second kind: accept null hypothesis while the alternative hypothesis is true Level of significance of a statistical test: = probability on error of the first kind Power of a statistical test: = 1 – probability on error of the second kind decision No certainty in statistics null hypothesis true false accept 1- reject 1- NOEC Statistical testing Contr. Response NOEC * LOEC NOEC No Observed Effect Concentration LOEC Lowest Observed Effect Concentration log concentration What’s wrong with NOEC? Power of the test is not known No statistically significant effect is not no effect; Effect at NOEC regularly 10-34%, up to >50% Inefficient use of data – only last time point, only lowest doses – for non-parametric tests also values discarded Contr. NOEC Response • • • • LOEC OECD Braunschweig meeting 1996: * NOEC is inappropriate and should be phased out! log concentration Statements to remember • “proving” something statistically is absurd • if you do not know the power of your test, do don’t know what you are doing while testing • you need to specify the alternative hypothesis to know the power this involves knowledge about the subject (biology, chemistry, ..) • parameters only have a meaning if the model is “true” this involves knowledge about the subject Independent observations If X and Y are independent I I f Central limit theorems The sum of n independent identically (i.i.) distributed random variables becomes normally distributed for increasing n. Z X Y f ( z ) f ( z y) f ( y) dy; P( Z z ) P( X z y) P(Y y) Z X y Y y The sum of n independent point processes tends to behave as a Poisson process for increasing n. Number of events in a time interval is i.i. Poisson distributed Time intervals between subsequent events is i.i. exponentially distributed Poisson prob Exponential prob dens Sums of random variables n Y Xi; i 1 Var (Y ) nVar ( X i ) f X ( x) λ exp( λx) λ fY ( y ) (λy) n1 exp( λy ) ( n) λx P( X x) exp( λ) x! (nλ) y P(Y y ) exp( nλ) y! Normal probability density σ σ 95% (x-μ)/σ 1 x μ 2 f X ( x) exp 2 2πσ 2 σ 1 f X ( x) 1 exp x μ ' -1 x μ 2π n 2 1 Parameter estimation Most frequently used method: Maximization of (log) Likelihood likelihood: probability of finding observed data (given the model), considered as function of parameter values If we repeat the collection of data many times (same conditions, same number of data) the resulting ML estimate Profile likelihood large sample approximation 95% conf interval Comparison of models Akaike Information Criterion for sample size n and K parameters n 2 log L(θ) 2 K n K 1 in the case of a regression model n 2 n log σ 2 K n K 1 You can compare goodness of fit of different models to the same data but statistics will not help you to choose between the models Confidence intervals length, mm L(t ) L ( L L0 ) exp( rB t ) L0 ( L L0 )rB t for small t L0 1 excludes point 4 95% conf intervals rB includes point 4 time, d L correlations among parameter estimates can have big effects on sim conf intervals estimate excluding point 4 sd excluding point 4 estimate including point 4 sd including point 4 L, mm 6.46 1.08 3.37 0.096 rB,d-1 0.099 0.022 0.277 0.023 parameter :No age, but size:These gouramis are from the same nest, they have the same age and lived in the same tank Social interaction during feeding caused the huge size difference Age-based models for growth are bound to fail; growth depends on food intake Trichopsis vittatus Rules for feeding determin expectation length reserve density Social interaction Feeding time time 1 ind 2 ind length reserve density time time Dependent observations Conclusion Dependences can work out in complex ways The two growth curves look like von Bertalanffy curves with very different parameters But in reality both individuals had the same parameters!