Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
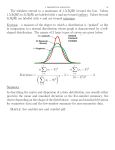
Interpreting the Standard Deviation The Empirical Rule A rule of thumb that applies to data sets that have a mound shaped, symmetric distribution • Given two samples from a population, the sample with the larger standard deviation (SD) is the more variable – Approximately 68% of the measurements will fall within 1 SD of the mean – Say we have sx 21.4; sy 29.6 • We are using the SD as a relative or comparative measure—Y is …? – Approximately 95% of the measurements will fall within 2 SDs of the mean • How does the SD provide a measure of variability for a single sample or, what does 29.6 really mean? – Approximately 99.7% of the measurements will fall within 3 SDs of the mean 1 Distribution for measurements from a normal population with 350; =25 0.015 2 Application of Empirical Rule for Mound-Shaped Distributions of Data (continued) , 350 25, 350 25 325,375 2 , 2 350 50 , 350 50 300 ,400 0.010 3 , 3 350 75, 350 75 275,425 0.005 0.000 250 275 300 325 350 375 400 425 450 3 Relationships Between Quantitative Variables 4 heights (in inches) and fully stretched handspans (in centimeters) of 167 college students. • Scatterplot, a two-dimensional graph of data values. • Use a scatterplot to look at the relationship between two quantitative variables • Plot has one variable’s values along the vertical axis and the other variable’s values along the horizontal axis • Correlation, a statistic that measures the strength and direction of a linear relationship • Regression equation, an equation that describes the average relationship between a response and explanatory variable---we will not get to this 5 6 1 Questions that might be asked • What is the average pattern? Does it look like a straight line or is it curved? • What is the direction of the pattern? • How much do individual points vary from the average pattern? • Are there any unusual data points? Use different plotting symbols or colors to represent different subgroups. 7 8 Positive/Negative Association For the handspan/height data • Two variables have a positive association when the values of one variable tend to increase as the values of the other variable increase. • Two variables have a negative association when the values of one variable tend to decrease as the values of the other variable increase. • Taller people tend to have greater handspan measurements than shorter people do (positive association) • The handspan and height measurements may have a linear relationship. 9 Look for outliers: points that have an usual combination of data values. 10 Outliers Outlier--- an unusually large or small measurement relative to the other observations Common causes: • Measurement incorrectly observed or recorded (including data entry) • Measurement comes from a different population • Measurement is correct, but represents a rare event 11 12 2 heights (in inches) and fully left foot length (in inches) of Stat 311 students Stat 311 Survey Body weights and the time it takes to chug a 12-ounce beverage for n=13 college students. The data were submitted by a student for a class project. (Source: William Harkness, Pennsylvania State University) Chug Time Left Foot Length (in) 200 150 100 8.0 6.0 4.0 2.0 140 50 0 190 240 Weight 0 100 200 300 Height (in) 400 500 13 14 Chug Time Methods for Detecting Outliers 1.5 IQR Rule and Box plots • Based on quartiles of a data set 8.0 6.0 • Quartiles partition the data set into 4 groups, each containing 25% of the measurements 4.0 2.0 140 190 240 Weight • The lower quartile, Q1 , is the 25th percentile; the middle quartile, M, is the median (50th percentile); the upper quartile, Q3 , is the 75th percentile 15 16 Methods for Detecting Outliers Methods for Detecting Outliers Example: sample of 5000 data values from the normal population with 350; =25 Interquartile Range (IQR)--distance between the upper and lower quartiles R summary output IQR Q3 Q1 Min.:257.0 1st Qu.:333.3 Lower fence = Q1 1.5 IQR Upper fence = Q3 1.5 IQR Median:350.0 Mean:349.8 3rd Qu.:366.0 Max.:439.9 17 18 3 Methods for Detecting Outliers Methods for Detecting Outliers IQR 366 333.3 32.7 1.5 IQR 49.05 Median Mean Q1, Q3 20 410 1.5 x IQR Criteria 366.0 49.05 415.05 15 360 310 10 5 333.3 49.05 284.25 0 0.0 3.1 6.3 9.4 12.6 260 19 20 Methods for Detecting Outliers 12 8 Min: 1st Qu.: Mean: Median: 3rd Qu.: Max: Total N: NA's : Std Dev.: 1.000000 3.600000 5.109434 4.500000 5.800000 12.600000 53.000000 0.000000 2.465552 4 Q1 - (1.5 x IQR) = 0.3 Q3 + (1.5 x IQR) = 9.1 0 21 4