Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
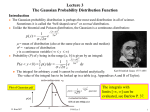
Review of Gaussian random variables If x is a Gaussian random variable (with zero mean), then its probability distribution function is given by P (x) = √ Note that Z 1 2 2 e−x /2σ . 2πσ (1) ∞ P (x) dx = 1, (2) −∞ (If x were Gaussian with non-zero mean, you could remove the mean by redefining x ← x − hxi, and then put it back again later.) The moments are easy to compute, and they all depend only on the standard deviation σ. All the odd moments vanish, hx2m+1 i = 0 (3) and the even moments are easily computed by (for example) taking the derivatives of (1) with respect to 1/2σ 2 . One finds that hx2 i = σ 2 , hx4 i = 3σ 4 , etc. Why be Gaussian? First of all, many things are. For example, the single point statistics of velocity in turbulent flow are found to approximately Gaussian. This is often considered to be a manifestation of the Central Limit Theorem, which we prove below. Second, Gaussian distributions are easy to handle mathematically. Many statistical theories of turbulence can viewed as expansions about Gaussianity. For any (not necessarily Gaussian) probability distribution P (x), the characteristic function is defined as Z ∞ φ(ω) = P (x)eiωx dx (4) −∞ Thus φ(ω) is the Fourier transform of P (x). It follows that Z ∞ 0 φ (ω) = ixP (x)eiωx dx, φ0 (0) = ihxi Z−∞ ∞ 00 φ (ω) = (ix)2 P (x)eiωx dx, φ00 (0) = −hx2 i −∞ 1 (5) etc. Thus, knowledge of the probability distribution is equivalent to knowledge of all its moments. For the Gaussian distribution (1) we obtain φ(ω) = e−σ 2 ω 2 /2 . (6) The characteristic function is often used to do proofs. As an example, we will prove the central limit theorem. Let x1 , x2 , . . . , xn be n independent but not necessarily Gaussian random variables all having zero mean and the same distribution function P1 (x). Consider the random variable defined as their average: 1 (7) x = (x1 + x2 + · · · + xn ) n The Central Limit Theorem says that, as n → ∞, x becomes Gaussian even though the xi are not. Let P (x) be the unknown distribution of x, and let φ(ω) be its characteristic function. Then Z φ(ω) = P (x)eiωx dx ZZ Z iω (x1 + x2 + · · · + xn ) dx1 dx2 · · · dxn = · · · P (x1 , x2 , . . . , xn ) exp n ZZ Z iω (x1 + x2 + · · · + xn ) dx1 dx2 · · · dxn = · · · P1 (x1 )P1 (x2 ) · · · P1 (xn ) exp n Z Z Z iωx1 iωx2 iωxn = P1 (x1 ) exp( )dx1 P1 (x2 ) exp( )dx2 · · · P1 (xn ) exp( )dxn n n n ω n = φ1 (8) n where φ1 (ω) is the Fourier transform of P1 (x). Since φ1 (ω) = 1 + 0 − σ12 2 ω + ··· 2 where σ12 is the variance of any of the xi , we have ω σ2 ω2 φ1 = 1 − 1 2 + ··· n 2 n (9) (10) Thus, by (8), as n → ∞, φ (ω) → σ2 ω2 1− 1 2 2 n 2 n (11) Since as n → ∞ s n → es 1+ n (12) we find that 2 φ (ω) → e−σ1 ω 2 /2n (13) √ and therefore (cf. (6)) x is Gaussian with standard deviation σ = σ1 / n. QED Now let x1 , x2 , . . . , xn be n random variables with probability distribution function ! 1X Aij xi xj (14) P (x1 , x2 , . . . , xn ) = C exp − 2 ij The x1 , x2 , . . . , xn are said to be jointly Gaussian. With no loss in generality we can assume that Aij is symmetric. Then the matrix A has real eigenvalues and orthogonal eigenvectors (which can be made orthonormal). That is Ae(i) = λ(i) e(i) where e(i) T e(i) = δij (15) (16) and the T means transpose. It is possible to transform from the original variables x1 , x2 , . . . , xn to new variables y1 , y2 , . . . , yn in which the quadratic form X Q= Aij xi xj (17) ij is diagonal. The transformation is given by X (j) X xi = yj ei = Uij yj j (18) j Thus yj is the amplitude of the eigenvector e(j) in an expansion of the column vector (x1 , x2 , · · · , xn )T in terms of the eigenvectors. We write this in matrix notation as x = Uy (19) with the understanding that x and y are n-dimensional column vectors. The matrix U is defined by U = (e(1) e(2) · · · e(n) ) (20) 3 Thus the column vectors of U are the eigenvectors of A. By the orthonormality of the column vectors, we have UT U = I (21) That is, the transform of U is equal to its inverse. Matrices with this property are called unitary matrices. Now we compute Q = xT Ax = (U y)T A(U y) = yT U T AU y = yT Dy X = λ(i) yi2 (22) i where U T AU = D ≡ diag(λ(1) , λ(2) , . . . λ(n) ) (23) That is, D is the diagonal matrix with the eigenvalues as its diagonal components. The probability distribution of y1 , y2 , . . . , yn takes the form ! X 1 λ(i) yi2 (24) P (y1 , y2 , . . . , yn ) = C exp − 2 i Since this factors into functions of each yi , we easily compute the normalization constant (λ(1) λ(2) · · · λ(n) )1/2 C= (25) (2π)n/2 and the covariances hyi yj i = 1 δij λ(i) (26) In matrix notation hyyT i = D−1 (27) What are the moments of our original variables xi ? By the linearity of the transformation from y to x, we have that hxi i = hxi xj xk i = 0 4 (28) In fact, all the odd moments vanish. For the second moments we have using (27) hxxT i = hU y(U y)T i = hU yyT (U )T i = U D−1 U T (29) But by (23) and (21), this is hxxT i = U (U T AU )−1 U T = A−1 (30) hxi xj i = A−1 ij (31) That is Finally we consider hxi xj xk xm i. We have X hxi xj xk xm i = hUir yr Ujs ys Ukp yp Umq yq i rspq = X Uir Ujs Ukp Umq hyr ys yp yq i (32) rspq where the summation convention is in effect. But we know that the yi are independent random variables. Thus hyr ys yp yq i = hyr ys iδrs hyp yq iδpq + hyr yp iδrp hys yq iδsq + hyr yq iδrq hys yp iδsp (33) (which is true as a special case when r = s = p = q). Substituting this back into (32), we conclude that hxi xj xk xm i = hxi xj ihxk xm i + hxi xk ihxj xm i + hxi xm ihxj xk i (34) A similar factorization rule applies to all the higher even moments, but we shall find particular use for (34). 5