Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
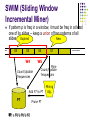
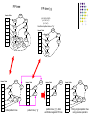
Verifying and Mining Frequent Patterns from Large Windows over Data Streams Barzan Mozafari, Hetal Thakkar, and Carlo Zaniolo ICDE 2008 Cancun, Mexico Finding Frequent Patterns for Association Rule Mining Given a set of transactions T and a support threshold s, find all patterns with support >= s Apriori [Agrawal’ 94], FP-growth [Han’ 00] Fast & light algorithms for data streams More than 30 proposals [Jiang’ 06] For mining windows over streams In particular DSMSs divide windows into panes, a.k.a. slides As in our Stream Mill Miner system Moment (Maintaining Closed Frequent Itemsets over a Stream Sliding Window) Yun Chi, Haixun Wang, Philip S. Yu, Richard R. Muntz Collaboration of UCLA + IBM Closed Enumeration Tree (CET) Very similar to FP-tree, except that keeps a dynamic set of items: Closed freq itemsets Boundary itemsets Moment Algorithm (I) Hope: In the absence of cocncept drifts, not many changes in status Maintains two types of boundary nodes; 1. Freq / non-freq 2. Closed / non-closed Taking specific actions to maintain a shifting boundary whenever a concept shift occurs Moment Algorithm (II) Infreq gateway nodes Unpromising gateway nodes Freq + prefix of a closed w/ same support Intermiddiate nodes Infreq + its parent freq + result of a candidate join Freq + has a child w/ same supp + not unpromising Closed nodes Closed freq Moment Algorithm (III) Increments: Add/Delete to/from CET upon arrival/expiration of each transaction. Downside: Batch operations not applicable, suffers from big slide sizes Advantage: Efficient for small slides CanTree [Leung’ 05] Use a fixed canonical order according to decreasing single freq. Use a single-round version of FP-growth Algorithm: Upon each window move: Add/Remove new/expired trans to/from FPtree (using the same item order) Run FP-growth! (Without any pruning) CanTree (cont.) Pros: Very efficient for large slides Cons: Inefficient for small slides Not scallable for large windows Needs memory for entire window Frequent Patterns Mining over Data Streams Expired … S4 New S5 S6 W4 W5 Challenges Computation Storage Real-time response Customization Integration with the DSMS S7 ………. Frequent Patterns Mining over Data Streams Difficult problem: [Chi’ 04, Leung’ 05, Cheung’ 03, Koh’ 04, …] Mining each window from scratch - too expensive Subsequent windows have many freq patterns in common Updating frequent patterns every new tuple, also too expensive SWIM’s middle-road approach: incrementally maintain frequent patterns over sliding windows Desiderata: scalability with slide size and window size SWIM (Sliding Window Incremental Miner) … If pattern p is freq in a window, it must be freq in at least one of its slides -- keep a union of freq patterns of all Expired New slides (PT) S4 S5 S6 W4 W5 Count/Update frequencies Mine Count/Update frequencies Add F7 to PT PT PT = F5 F4 U U F6 F5 U U F7 F6 S7 Prune PT Mining Alg. ………. SWIM For each new slide Si Verify frequency of these new patterns in each window slide Find all frequent patterns in Si (using FP-growth) Immediately or With delay (< N slides) Trade-off: max delay vs. computation. No false negatives or false positives! SWIM – Design Choices Data Structure for Si’s: FP-tree [Han’ 00] Data Structure for PT: FP-tree Mining Algorithm: FP-growth Count/Update frequencies: Naïve? Hashtree? Counting is the bottleneck New and improved counting method named Conditional Counting Conditional Counting Verification Given a set of transactions T, a set of patterns P, and a threshold s Goal: Find the exact freq of each p P w.r.t. to T, IF AND ONLY IF its freq is s If s=0, verification = counting, but if s>0 extra computation can be avoided Proposed fast verifiers DTV, DFV, hybrid Conditionalization on FP-trees FP-tree FP-tree | g FP-tree | gd Attempt I: DTV (Double-Tree Verifier) Not only conditionalize the fp-tree, but also the pattern tree FP-tree root Header Table a FP-tree | g a:5 b:1 b:5 e:1 c:5 g:1 (a:2,b:2,c:2,d:2) (a:1,b:1,c:1) (b:1,e:1) Conditional pattern base of “g” b c d root Header Table e a f d:4 g g:1 h:1 c h e:1 f:1 a:3 b:1 b:3 e:1 b g:2 d e c:3 f d:2 root:? Header Table a g:? b:? b c a b:? b d:? c d e root:? Header Table e:? f:? f g:? root:4 Header Table a b:3 c d:2 Initial pattern tree c d d d e e e f f f g h a pattern tree | “g” g:4 b:? b b d:? root:? Header Table pattern tree | “g”, after verification against FP-tree d:? e:? f:? g:2 g h Filling original pattern tree using reverse pointers DTV (cont.) Scales up well on large trees Much pruning from conditionalization However, for smaller trees Less pruning Overhead of conditionalization not always worth it Attempt II: DFV (Depth-First Verifier) Each node n in PT corresponds to a unique pattern pn, therefore: For each node n in PT Traverse the FP-tree and count the occurrence of pn in a depth-first order Keep the nodes marked as FAIL/OK while visiting their children Utilize these marks for optimized execution More efficient when both trees are small DFV (cont.) DFV (cont.) Comparing Verifiers Hybrid Verifier Start with performing DTV recursively Until the resulting trees are small enough, then perform DFV Comparing Verifiers Verifiers vs. Hash Trees (Counting) SWIM with Hybrid Verifier (I) SWIM with Hybrid Verifier (II) Applications of Verifiers (I) Improving counting in static mining methods Candidate-generation (and pruning) phase Example: Toivonen Approach [Toivonen’ 96] 1. 2. Maintain a boundary of smallest non-frequent and largest frequent patterns Check the frequency of boundary patterns Applications of Verifiers (II) In case resources are limited 1. 2. Mine once Keep monitoring the current patterns (by verifying them) 3. Since verifying is computationally cheaper Whenever a significant concept shift is detected, mine again! Monitoring/Concept Shift Detection Verification is much faster than mining (when it suffices) Privacy Preserving Applications Random noise methods: Add many fake items into the transactions to increase the variance [Evfimievski’ 03] Overhead: Long transactions (in the order of the no of items) Lemma: Max depth of the recursion in DTV is <= the max len of the patterns to be verified. Run-time independent of the transaction length Optimization when integrated into a DSMS Stream Mill Miner (SMM) provides integrated support for online mining algorithms by Constraints used for optimization User Define Aggregates (UDAs) Definition of Mining Models Max allowed delay Interesting/Uninteresting items Interesting/Uninteresting patterns These are turned from post-conditions into preconditions Conclusions SWIM for incremental mining over large windows 1. More efficient than existing approaches on data streams Trade-off between real-time response, efficiency, memory, etc. Efficient algorithms for verification/conditional counting 2. DTV, DFV, and Hybrid These can be used to speed-up many applications: Incremental mining, enhancing static algorithms, privacy preserving techniques, … Implementations of SWIM and the verifiers available at http://wis.cs.ucla.edu/swim/index.htm References [Agrawal’ 94] R. Agrawal and R. Srikant. Fast algorithms for mining association rules in large databases. In VLDB, pages 487–499, 1994. [Cheung’ 03] W. Cheung and O. R. Zaiane, “Incremental mining of frequent patterns without candidate generation or support,” in DEAS, 2003. [Chi’ 04] Y. Chi, H. Wang, P. S. Yu, and R. R. Muntz, “Moment: Maintaining closed frequent itemsets over a stream sliding window,” in ICDM, November 2004. [Evfimievski’ 03] A. Evfimievski, J. Gehrke, and R. Srikant, “Limiting privacy breaches in privacy preserving data mining,” in PODS, 2003. [Han’ 00] J. Han, J. Pei, and Y. Yin. Mining frequent patterns without candidate generation. In SIGMOD, 2000. [Koh’ 04] J. Koh and S. Shieh, “An efficient approach for maintaining association rules based on adjusting fp-tree structures.” in DASFAA, 2004. [Leung’ 05] C.-S. Leung, Q. Khan, and T. Hoque, “Cantree: A tree structure for efficient incremental mining of frequent patterns,” in ICDM, 2005. [Toivonen’ 96] H. Toivonen, “Sampling large databases for association rules,” in VLDB, 1996, pp. 134–145. Thank you! Questions? DFV (cont.) DFV (cont.)