Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Day 3:
Competition models
Roger Levy
University of Edinburgh
&
University of California – San Diego
Today
• Probability/Statistics concept: linear models
• Finish competition models
Linear models
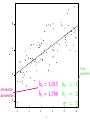
• y = a + bx
-10
0
y
10
20
Linear fit
0
2
4
6
x
8
10
Linear models (2)
• Linear regression is often formulated in terms of
“least squares” or minimizing “sum of squared
error”
-10
0
y
10
20
error
0
2
4
6
8
10
x
• For us, an alternative interpretation is more
important
• Assume that the datapoints were generated
stochastically with normally distributed error
• Least-squares fit is maximum-likelihood estimate
20
10
y
0
true
params
-10
estimated
parameters
0
2
4
6
x
8
10
Generalized
Linear models (3)
outcome
• The task of fitting a (linear) model to a
continuous real-valued output variable is called
(linear) regression
• But if our output variable is discrete and
+
unordered, then
linear regression doesn’t make
sense
0.0
0.2
0.4
0.6
0.8
x
• We can generalize linear regression by allowing
+
1
Logistic fit
outcome
new scale
interpretable
as probability
-
0
0.0
0.2
0.4
0.6
x
0.8
1.0
Linear models (4)
• We can also generalize linear models beyond one
“input” variable (also called independent variable,
covariate, feature,…)
U
• We can generalize to >2 classes by introducing
multiple predictors Ui
Today
• Probability/Statistics concept: linear models
• Finish competition models
Case study: McRae et al. 1998
• Variant of the famous garden-path sentences
• The {crook/cop} arrested by the detective was
guilty
• Ambiguity at the first verb is (almost) completely
resolved by the end of the PP
• But the viability of RR versus MC interpretations
at the temporary ambiguity is affected by a
number of non-categorical factors
• McRae et al. constructed a model incorporating
the use of these factors for incremental
constraint-based disambiguation
• linking hypothesis: competition among alternatives
drives reading times
Modeling procedure
• First, define a model of incremental online
disambiguation
• Second, fit the model parameters based on
“naturally-occurring data”
• Third, test the model predictions against
experimentally derived behavioral data, using the
linking hypothesis between model structure and
behavioral measures
Constraint types
• Configurational bias: MV vs. RR
• Thematic fit (initial NP to verb’s roles)
• i.e., Plaus(verb,noun), ranging from 0 through 6
• Bias of verb: simple past vs. past participle
• i.e., P(past | verb)*
• Support of by
• i.e., P(MV | <verb,by>) [not conditioned on specific
verb]
• That these factors can affect processing in the
MV/RR ambiguity is motivated by a variety of
previous studies (MacDonald et al. 1993, Burgess et al.
1993, Trueswell et al. 1994 (c.f. Ferreira & Clifton 1986),
cally not
calculated
this way, but this would be the rational reconstruction
Trueswell
1996)
The competition model
• Constraint
strength
determines
degree of bias
• Constraint weight
determines its
importance in the
RR/MC
decision
Interpretation
nodes
strength
Constraint nodes
weight
Evaluating the model
• The support ci,j at each constraint is normalized
• Each interpretation Ai receives support from each
constraint ci,j proportionate to constraint weight
wj
• The interpretation nodes feed additional support
back into each constraint node, at a growth rate
of wjAi
[ci step
modelt demo]
• …at each time
i
0.0
0.2
0.4
0.6
0.8
Probability of preferred candidate
1.0
CI simulation
0
5
10
15
Cycle
20
25
30
The feedback process
• Generally,* the positive feedback process means
that the interpretation Ij that has greatest
activation after step 1 will have its activation
increased more and more with each iteration of
the model
when there are ≥3 interpretation nodes, leader is not guaranteed to win
Estimating constraint strength
• RR/MC bias: corpus study
• conditional probability of RR or MC given “NP V”
sequence
• Verb tense bias: corpus study
• conditional probability (well, almost*) of simple
past/past participle given the verb
• by bias: corpus study
• conditional probability of RR or MC given “V-ed by”
• thematic fit: offline judgment study
• mean typicality rating for “cop” + “arrested” (not a
probability, though normalized)
McRae et al. 1998
Estimating constraint weight
• The idea: constraint weights that best fit offline
sentence continuations should also fit online
reading data
• Empirical data collection: gated sentence
completions
The cop arrested…
arrested by…
by the…
the detective…
• The learning procedure: minimize root mean
square error of model predictions
• …for a variety of # of time steps k
• optimal constraint weights determined by grid
search between [0,1]
Fit to offline gated completion
data
• initial MV
bias
• more
words→
increasing
RR bias
• 100% RR
after seeing
agent
• Before then,
good patient
biases
toward RR
Fit against self-paced reading data
• Competition hypothesis: associate processing
time with the number of steps required for a
model to run to a certain threshold
• Intuition: at every word, readers hesitate until one
interpretation is salient enough
• Dynamic threshold at time step i: 1 – Δcrit × i
• Intuition: the more time spent, the less fussy
readers become about requiring a salient
interpretation
• Usually,* the initially-best interpretation will reach
the threshold first
0.8
0.4
0.6
decreasing
threshold
0.2
point of intersection
determines predicted RT
0.0
Probability of preferred candidate
1.0
CI simulation with decreasing threshold (slope = 0.007)
0
5
10
15
Cycle
20
25
30
Self-paced reading expt
• Contrasted good-patient versus good-agent
subject NPs
• Compared reading time in unreduced versus
reduced relatives
The {cop/crook} (who was) arrested by the detective was guilty…
• Measurement of interest: slowdown per region in
reduced with respect to unreduced condition
• Linking hypothesis: cycles to threshold ~ reading
time per region
McRae et al. results
model still prefers MV
in good-agent case
mean activation
of RR node
Results
• Good match between reading time patterns and #
cycles in model
• Model-predicted RTs are basically monotonic in
initial equibias of candidates
• At end of agent PP, the model prefers main-clause
interpretation in good-agent (the cop arrested)
condition!
• is this consistent with gated completion results?
• Critical analysis: intuitively, do the data admit to
other interpretations besides competition?
What kind of probabilistic model is
this?
• Without feedback, this is a kind of linear model
• In general, a linear model has form (e.g., NLP
MaxEnt)
Ai cij wij
F ( x) ( x)
or
j
• McRae et al. have added the requirement that
values of {wij} are independent of i
Ai cij w j
j
• This is a discriminative model -- fits
P({MV,RR}|string)
Ai c j w
• A more commonly
seen
assumption (e.g., in much
ij
j
of statistics) is that
values of {c } are independent
Conclusions for Competition
• General picture: there is support for deployment
of a variety of probabilistic information in online
reading
• More detailed idea: when multiple possible
analyses are salient, processing gets
{slower/more difficult}
• This is uncertainty only about what has been said
• Specific formalization: a type of linear model is
coupled with feedback to simulate online
competition
• cycles-to-threshold of competition process
*CI model predictions
implementation
downloadable
from course we
determines
about
reading time
http://homepages.inf.ed.ac.uk/rlevy/esslli2006
• [one more brainstorming session…]
A recent challenge to competition
• Sometimes, ambiguity seems to facilitate
processing:
The daughteri of the colonelj who shot himself*i/j
The daughteri of the colonelj who shot herselfi/*j
harder
easier
The soni
of the colonelj who shot himselfi/j
• [colonel has stereotypical male gender]
• Argued to be problematic for parallel constraintbased competition models
(Traxler et al. 1998; Van Gompel et al. 2001,
A recent challenge to competition
(2)
The soni of the colonelj who shot himselfi/j
• The reasoning here is that when there are two
valid attachments for the RC, there is a syntactic
ambiguity that doesn’t exist when there is only
one valid attachment
• This has also been demonstrated for other
disambiguations, e.g., animacy-based:
The bodyguardi of the governorj
The governori of the provincei
easier
retiringi/j
retiringi/*j
harder
Where is CI on the serial↔parallel
gradient?
• CI is widely recognized as a parallel model
• But because of the positive feedback cycle, it can
also behave like a serial model!
• [explain on the board]
• In some ways it is intermediate serial/parallel:
• After reading of wi is complete, the top-ranked
interpretation I1 will usually* have activation a1≥p1
• This can cause pseudo-serial behavior
• We saw this at “the detective” in good-agent
condition
High-level issues
• Granularity level of competing candidates
• the old question of granularity for estimating
probs
• also: more candidates → often more cycles to
threshold
• Window size for threshold requirement
• self-paced reading: the region displayed
• eye-tracking: fixation? word? (Spivey & Tanenhaus
1998)
Further reading
• Origin of normalized recurrence algorithm:
Spivey-Knowlton’s 1996 dissertation
• Spivey and Tanenhaus 1998
• Ferretti & McRae 1999
• Green & Mitchell 2006