Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
RNA polymerase II holoenzyme wikipedia , lookup
Secreted frizzled-related protein 1 wikipedia , lookup
Eukaryotic transcription wikipedia , lookup
Epitranscriptome wikipedia , lookup
Genetic code wikipedia , lookup
Ridge (biology) wikipedia , lookup
Genomic imprinting wikipedia , lookup
Gene desert wikipedia , lookup
Community fingerprinting wikipedia , lookup
Non-coding DNA wikipedia , lookup
Gene expression wikipedia , lookup
Gene regulatory network wikipedia , lookup
Gene expression profiling wikipedia , lookup
Alternative splicing wikipedia , lookup
Transcriptional regulation wikipedia , lookup
Molecular evolution wikipedia , lookup
Promoter (genetics) wikipedia , lookup
Artificial gene synthesis wikipedia , lookup
3. Genome Annotation:
Gene Prediction (II)
Gene Prediction: Computational Challenge
• Gene: A sequence of nucleotides coding
for protein
• Gene Prediction Problem: Determine the
beginning and end positions of genes in a
genome
Eukaryotic gene finding
• On average, vertebrate gene is about 30KB
long
• Coding region takes about 1KB
• Exon sizes vary from double digit numbers to
kilobases
• An average 5’ UTR is about 750 bp
• An average 3’UTR is about 450 bp but both
can be much longer.
Exons and Introns
• In eukaryotes, the gene is a combination
of coding segments (exons) that are
interrupted by non-coding segments
(introns)
• This makes computational gene prediction
in eukaryotes even more difficult
• Prokaryotes don’t have introns - Genes in
prokaryotes are continuous
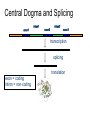
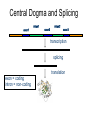
Central Dogma and Splicing
exon1
intron1
exon2
intron2
exon3
transcription
splicing
exon = coding
intron = non-coding
translation
Gene Structure
Splicing Signals
Exons are interspersed with introns and
typically flanked by GT and AG
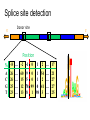
Splice site detection
Donor site
5’
3’
Position
%
A
C
G
T
-8 … -2 -1
26
26
25
23
…
…
…
…
0
1
2
… 17
60 9 0 1 54 … 21
15 5 0 1 2 … 27
12 78 99 0 41 … 27
13 8 1 98 3 … 25
Consensus splice sites
Donor: 7.9 bits
Acceptor: 9.4 bits
Promoters
• Promoters are DNA segments upstream
of transcripts that initiate transcription
Promoter
5’
3’
• Promoter attracts RNA Polymerase to the
transcription start site
Splicing mechanism
(http://genes.mit.edu/chris/)
Splicing mechanism
• Adenine recognition site marks intron
• snRNPs bind around adenine recognition
site
• The spliceosome thus forms
• Spliceosome excises introns in the mRNA
Two Approaches to Eukaryotic Gene Prediction
• Statistical: coding segments (exons) have typical
sequences on either end and use different
subwords than non-coding segments (introns).
• Similarity-based: many human genes are similar
to genes in mice, chicken, or even bacteria.
Therefore, already known mouse, chicken, and
bacterial genes may help to find human genes.
Similarity-Based Approach: Metaphor in Different Languages
If you could compare the day’s news in English, side-by-side
to the same news in a foreign language, some similarities
may become apparent
Distinguishing genes from non-coding regions
Splice
Dmel
Dsec
Dsim
Dyak
Dere
Dana
Dpse
Dper
Dwil
Dmoj
Dvir
Dgri
TGTTCATAAATAAA-----TTTACAACAGTTAGCTG-GTTAGCCAGGCGGAGTGTCTGCGCCCATTACCGTGCGGACGAGCATGT---GGCTCCAGCATCTTC
TGTCCATAAATAAA-----TTTACAACAGTTAGCTG-GTTAGCCAGGCGGAGTGTCTGCGCCCATTACCGTGCGGACGAGCATGT---GGCTCCAGCATCTTC
TGTCCATAAATAAA-----TTTACAACAGTTAGCTG-GTTAGCCAGGCGGAGTGTCTGCGCCCATTACCGTGCGGACGAGCATGT---GGCTCCAGCATCTTC
TGTCCATAAATAAA-----TTTACAACAGTTAGCTG-GTTAGCCAGGCGGAGTGCCTTCTACCATTACCGTGCGGACGAGCATGT---GGCTCCAGCATCTTC
TGTCCATAAATAAA-----TTTACAACAGTTAGCTG-CTTAGCCATGCGGAGTGCCTCCTGCCATTGCCGTGCGGGCGAGCATGT---GGCTCCAGCATCTTT
TGTCCATAAATAAA-----TCTACAACATTTAGCTG-GTTAGCCAGGCGGAGTGTCTGCGACCGTTCATG------CGGCCGTGA---GGCTCCATCATCTTA
TGTCCATAAATGAA-----TTTACAACATTTAGCTG-CTTAGCCAGGCGGAATGGCGCCGTCCGTTCCCGTGCATACGCCCGTGG---GGCTCCATCATTTTC
TGTCCATAAATGAA-----TTTACAACATTTAGCTG-CTTAGCCAGGCGGAATGCCGCCGTCCGTTCCCGTGCATACGCCCGTGG---GGCTCCATTATTTTC
TGTTCATAAATGAA-----TTTACAACACTTAACTGAGTTAGCCAAGCCGAGTGCCGCCGGCCATTAGTATGCAAACGACCATGG---GGTTCCATTATCTTC
TGATTATAAACGTAATGCTTTTATAACAATTAGCTG-GTTAGCCAAGCCGAGTGGCGCC------TGCCGTGCGTACGCCCCTGTCCCGGCTCCATCAGCTTT
TGTTTATAAAATTAATTCTTTTAAAACAATTAGCTG-GTTAGCCAGGCGGAATGGCGCC------GTCCGTGCGTGCGGCTCTGGCCCGGCTCCATCAGCTTC
TGTCTATAAAAATAATTCTTTTATGACACTTAACTG-ATTAGCCAGGCAGAGTGTCGCC------TGCCATGGGCACGACCCTGGCCGGGTTCCATCAGCTTT
*****
*
* ** *** *** *** ******* ** ** ** * * ** *
**
**
**
** **** * **
• Protein-coding genes have specific evolutionary constraints
–
–
–
–
Gaps are multiples of three (preserve amino acid translation)
Mutations are largely 3-periodic (silent codon substitutions)
Specific triplets exchanged more frequently (conservative substs.)
Conservation boundaries are sharp (pinpoint individual splicing signals)
• Encode as ‘evolutionary signatures’
– Computational test for each of them
– Combine and score systematically
Signature 1: Reading frame conservation
RFC
RFC
100%
60%
100%
55%
100%
90%
100%
40%
100%
60%
100%
100%
100%
20%
100%
30%
100%
40%
100%
60%
Mutations
Gaps
Frameshifts
Genes
Intergenic
30%
1.3%
0.14%
58%
14%
10.2%
Separation
2-fold
10-fold
75-fold
Results in yeast
~4000 named genes
~300 intergenic regions
Accept
Reject
99.9%
0.1%
1%
99%
Signature 2: Distinct patterns of codon substitution
Genes
Codon observed in species 2
Codon observed in species 1
Codon observed in species 1
Codon observed in species 2
• Codon substitution patterns specific to genes
– Genetic code dictates substitution patterns
– Amino acid properties dictate substitution patterns
Intergenic
human
Codon
Substitution
Matrix (CSM)
mouse
aliphatic
aromatic
polar
polar
negative positive
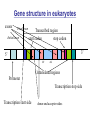
Gene structure in eukaryotes
exons
Final exon
Initial exon
Transcribed region
start codon
stop codon
3’
5’
GT
AG
Untranslated regions
Promoter
Transcription stop side
Transcription start side
donor and acceptor sides
Gene Prediction and Motifs
• Upstream regions of genes often contain
motifs that can be used for gene prediction
ATG
-35
-10
0
TTCCAA TATACT
Pribnow Box
10
GGAGG
Ribosomal binding site
Transcription start site
STOP
Ribosomal Binding Site
Splicing Signals
• Try to recognize location of splicing signals at
exon-intron junctions
– This has yielded a weakly conserved donor
splice site and acceptor splice site
• Profiles for sites are still weak, and lends the
problem to the Hidden Markov Model (HMM)
approaches, which capture the statistical
dependencies between sites
GenScan Model
• States- correspond to different functional units of a genome
(promoter region, intron, exon,….)
• The states for introns and exons are subdivided according to
“phase” three frames.
• There are two symmetric sub modules for forward and
backward strands.
Performance: 80% exon detecting (but if a gene has more than one
exon probability of detection decrease rapidly.
Donor and Acceptor Sites:
GT and AG dinucleotides
• The beginning and end of exons are signaled by donor
and acceptor sites that usually have GT and AC
dinucleotides
• Detecting these sites is difficult, because GT and AC
appear very often Donor
Acceptor
Site
GT
exon 1
Site
AC
exon 2
Donor and Acceptor Sites: Motif Logos
Donor: 7.9 bits
Acceptor: 9.4 bits
(Stephens & Schneider, 1996)
(http://www-lmmb.ncifcrf.gov/~toms/sequencelogo.html)
Popular Gene Prediction Algorithms
• GENSCAN: uses Hidden Markov Models
(HMMs)
• TWINSCAN
– Uses both HMM and similarity (e.g.,
between human and mouse genomes)
Similarity-based gene finding
• Alignment of
– Genomic sequence and (assembled) EST
sequences
– Genomic sequence and known (similar)
protein sequences
– Two or more similar genomic sequences
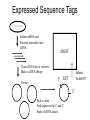
Expressed Sequence Tags
Cell or tissue
Isolate mRNA and
Reverse transcribe into
cDNA
dbEST
Clone cDNA into a vector to
Make a cDNA library
Vectors
Submit
To dbEST
5’ EST
3’
Pick a clone
And sequence the 5’ and 3’
Ends of cDNA insert
Central Dogma and Splicing
exon1
intron1
exon2
intron2
exon3
transcription
splicing
exon = coding
intron = non-coding
translation
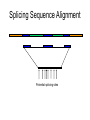
Splicing Sequence Alignment
Potential splicing sites
Comparing Genomic DNA Against
intron1 exon2
intron2
Portion of genome
{
{
{
{
{
EST
(codon sequence)
exon1
exon3
Using Similarities to Find the Exon Structure
• Human EST (mRNA) sequence is aligned to
different locations in the human genome
• Find the “best” path to reveal the exon structure
of human gene
EST sequence
Human Genome
Spliced Alignment Problem: Formulation
• Goal: Find a chain of blocks in a genomic
sequence that best fits a target sequence
• Input: Genomic sequences G, target
sequence T, and a set of candidate exons
B.
• Output: A chain of exons Γ such that the
global alignment score between Γ* and T
is maximum among all chains of blocks
from B.
Γ* - concatenation of all exons from chain Γ
Lewis Carroll Example
Spliced Alignment: Speedup
Spliced Alignment: Speedup
Spliced Alignment: Speedup
P(i,j)=maxall blocks B preceding position i S(end(B), j, B)
EST_genome
• http://www.well.ox.ac.uk/~rmott/ESTGENO
ME/est_genome.shtml
Gene finding based on multiple
genomes
• Twinscan
• PhyloHMM