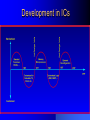
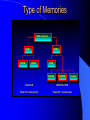
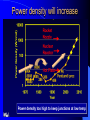
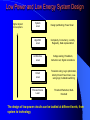
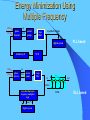
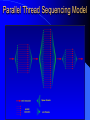
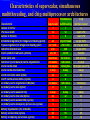
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
The Limits of Semiconductor Technology & Coming Challenges in Microarchitecture and Architecture Mile Stojčev, Teufik Tokić, Ivan Milentijević Faculty of Electonic Engineering, Niš Outline •Technology Trends •Process Technology Challenges – Low Power Design •Microprocessors’ Generations •Challenges in Education Outline – Technology Trends •Moore’s Law 1 •Moore’s Law 2 •Performance and New Technology Generation •Technology Trends – Example •Trends in Future •Processor Technology •Memory Technology Moore's Law 1 In 1965, Gordon Moore, director of research and development at Fairchild Semiconductor, later founder of Intel corp., wrote a paper for Electronics entitled “Cramming more components onto integrated circuits”. In the paper Moore observed that “The complexity for minimum component cost has increased at a rate of roughly a factor of two per year”. This observation became known as Moore's law. In fact, by 1975 the leading chips had maybe one-tenth as many components as Moore had predicted. The doubling period had stretched out to an average of 17 months in the decade ending in 1975, then slowed to 22 months through 1985 and 32 months through 1995. It has revived to a now relatively peppy 22 to 24 months in recent years. Moore’s Law 1 continue Similar exponential growth rates have occurred for other aspects of computer technology – disk capacities, memory chip capacities, and processor performance. These remarkable growth rates have been the major driving forces of the computer revolution. Logic DRAM Disk Capacity 2x in 3 years 4x in 3 years 4x in 3 years Speed (latency) 2x in 3 years 2x in 10 years 2x in 10 years Moore’s Law 1 – number of transistors Moore’s Law 1 - Linewidths One of the key drivers behind the industries ability to double transistor counts every 18 to 24 months, is the continuous reduction in linewidths. Shrinking linewidths not only enables more components to fit onto an IC (typically 2x per linewidth generation) but also lower costs (typically 30% per linewidth generation). Moore’s Law 1 - Die size Shrinking linewidths have slowed the rate of growth in die size to 1.14x per year versus 1.38 to 1.58x per year for transistor counts, and since the mid nineties accelerating linewidth shrinks have halted and even reversed the growth in die sizes. Moore's Law in Action The number of transistors on chip doubles annually Moore’s Law 1 – Microprocessor Moore’s Law 1– Capacity Single Chip DRAM Improving frequency via pipelining Process technology and microarchitecture innovations enable doubling the frequency increase every process generation The figure presents the contribution of both: as the process improves, the frequency increases and the average amount of work done in pipeline stages decreases Process Complexity Shrinking linewidths isn’t free. Linewidth shrinks require process modifications to deal with a variety of issues that come up from shrinking the devices leading to increasing complexity in the processes being used. Moore’s Law 2 (Rock’s Law) In 1996 Intel augmented Moore’s law (the number of transistor on processor double approximately every 18 mounts) with Moore’s law 2. Law 2 says that as sophistication of chip increases, the cost of fabrication rises exponentially. The cost of semiconductor tools doubles every four years. By this logic, chip fabrication plants, or fabs, were supposed to cost $5 billion each by the late 1990s and $10 billion by now Moore’s Law 2 (Rock’s Law) - continue For example: In 1986 Intel manufactured 386 that counted 250 000 transistors in fabs costing $200 million. In 1996 for Pentium processor that counted 6 million transistors $2 billion facility to produce was needed. Moore’s Law 2 (Rock’s Law) The Cost of Semiconductor Tools Doubles Every Four Years Machrone’s Law The PC you want to bay will always be $5000 Metcalfe’s Law A network’s value grows proportionately to the Number of its users squared Wirth’s Law Software is slowing faster than hardware is accelerating Performance and new technology generation According to the Moore’s law each new generation has approximately doubled logic circuit density and increased performance by about 40 % while quadrupling memory capacity. The increase in component per chip comes from following key factors: The factor of two in component density come from 20.5 shrink in each lithography dimensions (20.5 per x and 20.5 per y). An additional factor of 20.5 comes from an increase in chip area. A final factor of 20.5 comes from device and circuit cleverness. Development in ICs Semiconductor Industry Association Roadmap Summary for high-end Processors Specification/year 1997 1999 2001 2003 2006 2009 2012 Feature size (micron) 0.25 0.18 0.15 0.13 0.1 0.07 0.05 Supply voltage (V) 1.8-2.5 1.5-1.8 1.2-1.5 1.2-1.5 0.9-1.2 0.6-0.9 0.5-0.6 Transistors/chip (millions) 11 21 40 76 200 520 1400 DRAM bits/chip (mega) 167 1070 1700 4290 17200 68700 275000 Die size (mm2) 300 340 385 430 520 620 750 Global clock freq. (MHz) 750 1200 1400 1600 2000 2500 3000 Local clock freq. (MHz) 750 1250 1500 2100 3500 6000 10000 Maximum power/chip (W) 70 90 110 130 160 170 175 total transistors/chip No. of transistors (millions) 1600 Transistors/chip 1400 1200 1000 800 600 400 200 0 0.25 0.18 0.15 0.13 0.1 0.07 0.05 1997 1999 2001 2003 2006 2009 2012 Technology (micron)/year Clock Frequency Versus Year for Various Representative Machines Limiting in Clocking Traditional clocking techniques will reach their limit when the clock frequency reaches the 5-10 GHz range Frequency (MHz) 12000 Global clock freq. (MHz) 10000 Local clock freq. (MHz) 8000 6000 4000 2000 0 1997 1999 2001 2003 2006 2009 2012 0.25 0.18 0.15 0.13 0.1 0.07 0.05 Technology (micron)/year For higher frequency clocking (>10GHz) new ideas and new ways of designing digital systems are needed Intel’s Microprocessors Clock Frequency Technology Trends - Example As an illustration of just how computer technology is improving, let’s consider what would have happened if automobiles had improved equally quickly. Assume that an average car in 1977 had a top speed of 150 km/h and an average fuel economy of 10 km/l. If both top speed and efficiency improved at 35% per year from 1977 to 1987, and by 50% per year from 1987 to 2000, tracking computer performance, what would the average top speed and fuel economy of car be in 1987? In 2000? Solution In 1987:The span 1977 to 1987 is 10 years, so both traits would have improved by factor of (1.35)10 = 20.1 giving a top speed of 3015 km/h and fuel economy of 201 km/l In 2000: Thirteen more years elapse, this time at a 50% per year improvement rate, for a total factor of (1.5)13 = 194.6 over the 1987 values This gives a top speed of 586 719 km/h and fuel economy of 39 114.6 km/l. This is fast enough to cover the distance from the earth to the moon in under 39 min, and to make round trip on less than 10 liters of gasoline. Future size versus time in silicon ICs The semiconductor industry itself has developed a “roadmap” based on the idea of Moore’s law. The National Roadmap for Semiconductors (NTRS) and most recently the International Technology Roadmap for semiconductors (ITRS) now extend the device scaling and increased functionality scenario to the year 2014, at which point minimum future size are projected to be 35 nm and chips with > 1011 components are expected to be available. Trends in future size over time Processor technology today The most advanced processor technology today (year 2003) is 0.10 mm=100nm Ideally, processor technology scales by a factor of ~0.7 all physical dimensions of devices (transistors and wires) With such scaling, typical improvement figures are the following: • 1.4 – 1.5 times faster transistors • two times smaller transistors • 1.35 times lower operating voltages • three times lower switching power Processor Technology and Microprocessors Process technology is the most important technology that drives the microprocessor industry. It is characterized by growing 1000 times in frequency (from 1MHz to 1GHz) and integration (from ~10K to 1M devices) in 25 years Microarchitecture attempts to increase both IPC and frequency Process technology and microarchitecture Microarchitecture techniques such as caches, branch prediction, and out-of-order execution can increase instruction per cycle (IPC) Pipelining, as microarchitecture idea, help to increase frequency Modern architecture (ISA) and good optimizing compiler can reduce the number of dynamic instructions executed for a given program Frequency and performance improvements While in-order microprocessor used four to five pipe stages, modern out-of-order microprocessors use over ten pipe stages With frequencies higher than 1 GHz more than 20 pipeline stages are used 20 18 Frequency CPI 14 Performance 12 Power 10 8 6 4 2 Pipeline Depth 35 33 31 29 27 25 23 21 19 17 15 13 11 9 7 5 3 0 1 Relative Improvement 16 Performance of memory and CPU Memory in computer system is hierarchically organized In 1980 microprocessors were often designed without caches. Nowadays, microprocessors often come with two levels of caches. Memory Hierarchy Processor-DRAM Gap Microprocessor performance improved 55% per year since 1987, and 35% per year until 1986 Memory technology improvements aim primarily at increasing DRAM capacity not DRAM speed Relative processor/memory speed Type of Memories MOS memories ROM's RAM's SRAM DRAM ROM EPROM EEPROM FLASH VOLATILE NON VOLATILE Power off: contents lost Power off : contents kept Percentage of Usage Typical Applications of DRAM An anecdote In recent database benchmark study using TPC-C, both 200MHz Pentium Pro and 21164 Alpha systems were measured at 4.2 – 4.5 CPU cycles per instruction retired. IN other words, three out of every four CPU cycles retired zero instructions: most were spent waiting for memory ... Processor speed has seriously outstripped memory speed. Increasing the width of instruction issue and increasing the number of simultaneous instruction streams only makes the memory bottleneck worse An anecdote - continue If a CPU chip today needs to move 2GBytes/s (say, 16 bytes every 8ns) across the pins to keep itself busy, imagine a chip in the foreseeable future with twice the clock rate, twice the issue width, and two instruction streams. All this factors multiply together to require about 16 GBytes/s of pin bandwidth to keep this chip busy. If is not clear whether pin bandwidth can keep up – 32 bytes every 2ns? Memory system In 1GHz microprocessor, accessing main memory can take about 100 cycles. Such access may stall a pipelined microprocessor for many cycles and seriously impact the overall performance. To reduce memory stalls at a reasonable cost, modern microprocessor take advantage of the locality of references in the program and use a hierarchy of memory components Expensive Memory Called a Cache A small, fast, and expensive (in $/bit) memory called a cache is located on – die and holds frequently used data A somewhat bigger, but slower and cheaper cache may be located between the microprocessor and the system bus which connects the microprocessor to the main memory Two Levels of Caches Most advanced microprocessors today employ two levels of caches on chip The first level is ~ 32 – 128kB – it takes two to three cycles to access and typically catches about 95% of all accesses The second level is 256kB to over 1MB – it typically takes six to ten cycles to access and catches over 50% of misses of the first level Memory Hierarchy Impact on Performance Of – chip memory access may elapse about 100 cycles The cache miss that eventually has to go to the main memory can take about the same amount of time as executing 100 arithmetic and logic unit (ALU) instructions, so the structure of memory hierarchy has a major impact on performance Cache a made bigger and heuristics are used to make sure the cache contains portions of memory that are most likely to be used in the near future of program execution. As conclusion concerning memory - problems Today’s chip are largely able to execute code faster than we can feed then with instruction and data There are not longer performance bottlenecks in the floatingpoint multiplier or in having only a single integer unit. The real design action is in memory subsystems – caches, busses, bandwidth and latency. As conclusion concerning memory – problems, continue If the memory research community would follow the microprocessor community’s lead by learning more heavily on architecture – and system level solutions in addition to technology – level solutions to achieve higher performance, the gap might begin to close On expect that over the coming decade memory subsystems design will be the only important design issue for microprocessors. Memory Hierarchy Solutions Organization choices (CPU architecture, L1/L2 cache organizations, DRAM architecture, DRAM speed) can affect total execution time by a factor of two. System level parameters most affect performance: a) The number of independent channels and banks connecting the CPU to the DRAMs can effect a 25% performance change b) Burst – width – refers to data access granularity can effect a 15% performance change c) Magnetic RAM (MRAM) – new type of memory Magnetic RAM – MRAM or NanotechRAM (NRAM) Based on nanoscale semiconductor technology Nanotechnology RAM device consists of tiny Carbon nanotubes Differing electrical changes swing the tubes into one of two positions, representing the ones and zeroes necessary for digital storage. Moreover the tubes stay in position until a new signal resets them. MRAM Capacity The 10 Gbit devices consists of carbon nanotubes that are 1 nm – just a few thaunsand atoms – in diameter on a silicon wafer MRAM is nonvolatile, it has the perfotrmance of static RAM (SRAM) fast read-and-write The 10 Gbit devices consists of 10 Billions carbon nanotubes that are 1 nm – just a few thaunsand atoms – in diameter on a silicon wafer. MRAM as Universal Memory MRAM can replace many ofthers types of memory including SRAM, DRAM, ROM, EEPROM, Flash EEPROM, and feroelectric RAM (FRAM) . Prediction are crystalline structures that users grow on silicon. Capacity of DRAM and FLASH - MRAM 120 100 MLC(3bits/sell) 100nm 100 16Gb 80 10 70nm 8Gb FLASH 60 MLC(2bits/cell) 4Gb 4Gb SLC 2Gb 40 55nm 1Gb 1 DRAM 0.512Mb 20 0 0.1 2003 2005 2010 Density [Gb] Design Rule [nm] 90nm Surpassing the Prediction from Moore's Low – DRAM vs MRAM The famous Moore's Low predicts that the memory density will be doubled in 1,5 years, while the new growth model clearly indicates the doubling of NAND Flash memory density every year. 100 100 FLASH 2 fold density per year Density [Gb] MLC (3bits/cell) 12Gb Moore's Law 10 4Gb MLC (2bits/cell) 4Gb 2Gb DRAM 2Gb 1Gb 1 1Gb 0.512Mb 0.1 2000 2005 2010 Overall memory prediction roadmap Even though the density growth of DRAM will slow down, DRAM will still keep on leading the overall memory technology and will be able to reach 8 Gb density in ten years High-density memory growth will surpass the prediction from Moore's Low Overall memory prediction roadmap -cont 1988 Computer Food Chain 1997 Computer Food Chain 2003 Computer Food Chain Mainframe Supercomputer Outline •Technology Trends •Process Technology Challenges – Low Power Design •Microprocessors’ Generations •Challenges in Education Outline - Low Power Design •Power trends in VLSI •View Point on Power •Research Efforts in Low Power Design •Is there an Optimal Design Point Power consumption During 1995 energy consumption of all PC machines installed in USA was 60 * 106 MWh. •During 2000 energy consumption of all PC machines installed in USA was 10% of the total energy production. •During 2015 on except that the energy consumption of all PC machines will be 15% greater then 1995, or 69*106 MWh. Typical Low-Power Applications •battery operated equipments, •mobile communication equipments, •wireless communication equipments, •instrumentation, •consumer electronics, •biomedical technologies, •industry, •process controls ... Power dissipation in time “CMOS Circuits dissipate little power by nature. So believed circuit designers” (Kuroda-Sakurai, 95) 100 Power (W) x4 / 3years 10 1 0.1 0.01 80 85 90 95 “By the year 2000 power dissipation of high-end ICs will exceed the practical limits of ceramic packages, even if the supply voltage can be feasibly reduced.” Gloom and Doom predictions Power density will increase VDD, Power and Current Trend Voltage Voltage [V] 2 Power 1.5 Current 1 0.5 0 1998 2002 2006 2010 500 Power per chip [W] 200 0 2014 VDD current [A] 2.5 0 Year International Technology Roadmap for Semiconductors 1999 update sponsored by the Semiconductor Industry Association in cooperation with European Electronic Component Association (EECA) , Electronic Industries Association of Japan (EIAJ), Korea Semiconductor Industry Association (KSIA), and Taiwan Semiconductor Industry Association (TSIA) (* Taken from Sakurai’s ISSCC 2001 presentation) Power Delivery Problem (not just California) Your car starter ! Power Consumption New Dimension in Design Sources of Power Consumption The three major sources of power consumption in digital CMOS circuits are: Pavg pt CL Vdd2 f clk I sc Vdd I leakage Vdd P1 P2 P3 + P4 where: P1 – capacitive switching power (dynamic - dominant) P2 – short circuit power (dynamic) P3 – leakage current power (static) P4 – static power dissipation (minor) Research Efforts in Low-Power Design Reduce the active load: •Minimize the circuits •Use more efficient design •Charge recycling •More efficient layout Technology scaling: •The highest win •Thresholds should scale •Leakage starts to byte •Dynamic voltage scaling Psw = pt CL V2dd fCLK Reduce Switching Activity: •Conditional clock •Conditional precharge •Switching-off inactive blocks •Conditional execution Run it slower: •Use parallelism •Less pipeline stages •Use double-edge flip-flop Reducing the Power Dissipation The power dissipation can be minimized by reducing: supply voltage load capacitance switching activity – Reducing the supply voltage brings a quadratic improvement – Reducing the load capacitance contributes to the improvement of both power dissipation and circuit speed. Amount of Reducing the Power Dissipation Gate Delay and Power Dissipation in Term of Supply Voltage Power dissipation [ W ] (normalized) 25 Gate delay [ns] (normalized) 10 1 1 0.6 3.0 Supply voltage [ V ] 5.0 Needs for Low-Power • Efficient methodologies and technologies for the design of high-throughput and lowpower digital systems are needed. • The main interest of many researches is now oriented towards lowering the energy dissipation of these systems while still maintaining the high-throughput in real time processing. Low-Power Design Techniques The basic idea is: Decreasing activity of the some parts within VLSI IC. The term power manager refer to such techniques in general. Applying power management to a design typically involves two steps a) identifying idle or low active conditions for various parts of the circuit; and b) redesigning the circuits in order to eliminate or decrease switching activity in idle or low-active components. General Approaches to Reduce Power a) Reduction in fCLK is an option acceptable when some components may be idle or low-active during operation; b) Reduction in Vdd is the most effective way for power reduction, since the power is proportional to the square of Vdd. The problem with reducing Vdd is that it leads to an increase in circuit delay; c) The product pt·CL is called the average switched capacitance per cycle and the main directions for reducing this capacitance are done at system-, architectural-, RTL-, circuit- or technology level. Low Power and Low Energy System Design higher impact more options System Level Design partitioning, Power Down Algorithm Level Complexity, Concurrency, Locality, Regularity, Data representation Architecture Level Voltage scaling, Parallelism, Instruction set, Signal correlations Circuit Level Transistor sizing, Logic optimization, Activity Driven Power Down, Lowswing logic, Adiabatic switching Process Device Level Threshold Reduction, Multithreshold The design of low power circuits can be tackled at different levels, from system to technology Multiple Frequency on the Chip as Technique to Reduce Power Less aggressive approach is which attracts more attention. This technique is standardly used in VLSI ICs in order to reduce the power dissipation while maintaining the operating ff11, 11, ff12, 12,... ... ff31, 31, ff32, 32,... ... PLL PLL11/DLL /DLL11 PLL PLL33/DLL /DLL33 ffCLK CLK PLL PLL PLL PLL22/DLL /DLL22 PLL PLL44/DLL /DLL44 ff21, 21, ff21, 21,... ... ff41, 41, ff41, 41,... ... Energy Minimization Using Multiple Frequency CLKREF CLKFB up phase down detector curent pump loop filter regulated voltage PLL based digital system divider by N CLKREF CLKFB VCO up phase down detector curent pump loop filter control clock distribution & frequency multiplier logic f1 2f1 nf1 digital system TVCDL in DC1 DC2 .... VCDL out DCn DLL based Clock Gating & Clock Distribution as Techniques to Reduce Power target flip-flops latch enable A Q B Enable_A Enable_B D gated-clock C DFF clock Clk clock PLL (Clk generator) Enable_C enable C D gated-clock activated Clock distribution deactivated Clock gating - The use of gated clock is the most common approach to reduce energy. Unused modules are turned off by suppressing the clock to the module Energy Minimazation Using Multiple Supply Voltage • Multiple supply voltage on the chip, as less aggressive approach, is attracting attention • This has the advantage of allowing modules on the critical paths to use the highest voltage level (thus meeting the required timing constraints) while allowing modules on noncritical paths to use lower voltages (thus reducing the energy consumption) • This scheme tends to result in smaller area overhead compared to parallel architectures System Level Dynamic Power Management as another Techniques to Reduce Power Dynamic power management is design methodology that dynamically reconfigures an electronic system to provide the requested services and performance levels with a minimum number of active components or a minimum load on such components Power Manager Workload information OBSERVER P=400mW CONTROLLER RUN ~10ms Observations ~90ms Commands ~10ms 160ms P=50mW P=0.16mW IDLE SLEEP ~90ms SYSTEM Wait for interrupt Power Manager Wait for wake-up event Power State Machine Power Breakdown in High-Performance CPU and Dynamic Instruction Statistics Arithmetic op. Clock Compare op. 43 % 15% 13% Control Flow 5% 23% Logical op. 1% Others 12 % 25% Control, IO Datapath 16 % Memory Power breakdown 43% Data Move Dynamic instruction statistics Architecture Trade-offs – Reference Datapath Parallel Datapath The More Parallel the Better Pipeline Datapath Architecture Summary for a Simple Outline •Technology Trends •Process Technology Challenges – Low Power Design •Microprocessors’ Generations •Challenges in Education Outline Microprocessors’ Generations •First generation: 1971-78 –Behind the power curve •Second Generation: 1979-85 –Becoming “real” computers •Third Generation: 1985-89 –Challenging the “establishment” •Fourth Generation: 1990–Architectural and performance leadership The microprocessor today When we say “microprocessor” today, we generally mean the shaded area of the figure The First Generation: 1971-78 Getting enough bits and transistors Transistor counts < 50,000 Performance < 0.5 MIPS Architecture: 8-16 bits – Narrow datapaths (= slow performance) – Awkward architectures – Assembly language + some BASIC Processors: – Intel 4004, 8008. 8080, 8086 – Zilog Z-80 – Motorola 6800, 6502 Intel 4004 First general-purpose, single-chip microprocessor Shipped in 1971 8-bit architecture, 4-bit implementation 2,300 transistors Performance < 0.1 MIPS 8008: 8-bit implementation in 1972 – 3,500 transistors – First microprocessor-based computer (Micral) Targeted at laboratory instrumentation Mostly sold in Europe Intel 8080 Intel’s first 16-bit architecture – Delivered in 1974 – 4,800 transistors – Performance < 0.2 MIPS Used in Altair 8800 system – Kit form (advertised in Popular Electronics) in 1975 $297 or $395 with case! 256 bytes of memory; expandable to 64K! Keyboard and floppy 100-line bus becomes S-100, first microcomputer bus – Gates & Allen write BASIC – Wozniak builds one @ Homebrew Computer Club Intel 8086 Introduced in 1978 – Performance < 0.5 MIPS New 16-bit architecture – “Assembly language” compatible with 8080 – 29,000 transistors – Includes memory protection, support for FP coprocessor In 1981, IBM introduces PC – Based on 8088--8-bit bus version of 8086 Second Generation: 1979-85 Becoming “real” computers – First 32-bit architecture (68000) – First virtual memory support – Workstations, Macs, and PCs based on microprocessors Transistors >50,000 Performance <= 1 MIPS Processors: – Motorola 68000, 68020 – Intel 80286, 80386 Motorola 68000 Major architectural step in microprocessors: – First 32-bit architecture initial 16-bit implementation – First flat 32-bit address Support for paging – General-purpose register architecture Loosely based on PDP-11 First implementation in 1979 – 68,000 transistors – < 1 MIPS Used in – Apple Mac – Sun, Silicon Graphics, & Apollo workstations Third Generation: 1985-89 Challenging the “establishment” – Microprocessors surpass minicomputers in performance, rival mainframes – Implementation technology of choice: all new architectures are microprocessors – RISC architecture techniques take hold Transistors < 500K Performance > 5 MIPS Processors: – MIPS R2000, R3000 – Sun SPARC – HP PA-RISC MIPS R2000 Several firsts: – First RISC microprocessor – First microprocessor to provide integrated support for instruction & data cache – First pipelined microprocessor (sustains 1 instruction/clock) Implemented in 1985 – 125,000 transistors – 5-8 MIPS Fourth Generation: 1990 Architectural and performance leadership – First 64-bit architecture – First multiple-issue machine – First multilevel caches Transistors >1M Clock rates> 100MHz Performance > 50 MIPS Processors: – Intel i860, Pentium, MIPS R4000, MIPS R1000, DEC Alpha, Sun UltraSPARC, HP PA-RISC, PowerPC Generation 4.5: – same basic approach, but faster clock rates & wider issue – Alpha 21264, Pentium III & 4, Intel Itanium Key Architectural Trends Increase performance at 1.6x per year – True from 1985-present Combination of technology and architectural enhancements – Technology provides faster transistors and more of them – Faster transistors leads to high clock rates – More transistors: Architectural ideas turn transistors into performance – Responsible for about half the yearly performance growth Two key architectural directions – Sophisticated memory hierarchies – Exploiting instruction level parallelism Memory Hierarchies Caches: hide latency of DRAM and increase BW – CPU-DRAM access gap has grown by a factor of 30- 50! Trend 1: Increasingly large caches – On-chip: from 128 bytes (1984) to 100K+ bytes – Multilevel caches: add another level of caching First multilevel cache:1986 Secondary cache sizes today: 128KB to 4-16 MB Trend 2: Advances in caching techniques: – Reduce or hide cache miss latencies early restart after cache miss (1992) nonblocking caches: continue during a cache miss (1994) – Cache aware combos: computers, compilers, code writers prefetching: instruction to bring data into cache early Exploiting ILP ILP is the implicit parallelism among instructions Exploited by – Overlapping execution in a pipeline – Issuing multiple instruction per clock superscalar: uses dynamic issue decision (HW driven) VLIW: uses static issue decision (SW driven) 1985: simple microprocessor pipeline (1 instr/clock) 1990: first static multiple issue microprocessors 1995: sophisticated dynamic schemes – determine parallelism dynamically – execute instructions out-of-order – speculative execution depending on branch prediction “Off-the-shelf” ILP techniques yielded 20 year path. MIPS R4000 First 64-bit architecture Integrated caches – On-chip – Support for off-chip, secondary cache Integrated floating point Implemented in 1991: – – – – Deep pipeline 1.4M transistors Initially 100MHz > 50 MIPS Intel i860 First multiple issue microprocessor: – – – – 2 instructions/clock Dual issue mode Novel push pipeline Novel cache bypass Implemented in 1991: – 1.3M transistors – 50 mips Used primarily as attached processor (e.g., graphics) MIPS R10000 First speculative processor – Instruction scheduled and executed out-of-order – Up to 4 instructions can complete per clock – Window of 32 instructions (up to 32 in-flight) – Maintain precise state by completing instructions in order Implemented in 1996: – 6.8M transistors – 200 MHz Intel IA-64 and Itanium EPIC architecture: – Use compiler centric approach while avoiding disadvantages. – Parallelism demarcated by the compiler – Many special instruction & features for exploiting ILP in the compiler. Itanium – – – – First implementation (2001) 25 M transistors 800 MHz 130 Watts Breakdown of tasks between compiler and runtime hardware Today’s Uniprocessor ILP Menu Wide variety of approaches both hardware and compiler intensive Software Techniques – – – – – Static scheduling Static issue (i.e. VLIW) Static branch prediction Alias/pointer analysis Static speculation Lower hardware complexity More, longer range analysis More machine dependence Hardware Techniques – Dynamic scheduling – Dynamic issue (i.e. superscalar) – Dynamic branch prediction – Dynamic disambiguation – Dynamic speculation More stable performance Higher complexity Potential clock rate impact No clear cut winners at the present! Big Picture--ILP and Memory Systems My view ILP Mountain •No performance wall, but steeper slopes ahead. Speculation •Easier territory is behind us. •Industry-research gap vanished. Dynamic scheduling •Energy efficiency may be key limit. Simple pipelining Scheduled pipelines Cache Mountain Multiple issue Multipath prefetching Compiler prefetching Simple caches Multilevel caches & buffers Critical word & early restart Microprocessors today where they are, and what can do Performance 100 Supercomputers 10 Mainframes Microprocessors Minicomputers 1 0.1 1965 1970 1975 1980 1985 1990 1995 Microprocessors where they go Bit-level parallelism Instruction-level Thread-level (?) 100,000,000 10,000,000 1,000,000 R10000 Pentium Transistors i80386 i80286 100,000 R3000 R2000 i8086 10,000 i8080 i8008 i4004 1,000 1970 1975 1980 1985 1990 1995 2000 2005 Intel more Transistor Intel Faster Devices Number of Transistors in Intel’s processors Higher level parallelism Several approaches have been proposed to go beyond optimizing single-thread performance (latency) and to exploit higher performance (throughput) at better energy efficiency The more prononuced are: a) simultaneons multithreaded (SMT) processor, and b) chip multiprocessors (CMT) Multithreading Microprocessor can execute multiple operations at a time 4 or 6 operations per cycle Hard to achieve this level of parallelism from single program Can we run multiple programs (threads) on (single) processor without much effort? Simultaneous multithreading (SMT) or Hyperthreading is a solution Parallel Thread Sequencing Model Principles of SMT Multithreading in today’s processors Today many high-end microprocessors are multithreaded (e.g., Intel Pentium 4) Support for 2-4 threads but expect to get only 1.3X improvement in throughput Chip Multiprocessor Several processor cores in one die Shared L2 caches Chip Communication to build multichip module with many CMPs + memory Chip multiprocessor (CMP) platform model CMP is a simple very powerful techiniques to obtain more performance in a power-effecient manner. The idea is to put several microprocessors on a single die. This type of architecture is reffered also as Multiprocessor System-onChip (MPSoC) The performance of small-scale CMP scales close to linear with the number of microprocessors and is likely to exceed the performance of an equivalent multiprocessor system Chip multiprocessor (CMP) platform model - continue CMP is an atractive option to use when moving to a new process technology, such as SoC Typical MPSoC applications we meet in network processors, multimedia hubs, signal processors, etc MPSoCs are usually implemented as heterogenous systems CMT and SMT can coexist-a CMP die can integrate several SMT microprocessors Generic circa 2010 Microprocessor 4 – 8 general-purpose processing engines on chip used to execute independent programs Explicitly parallel programs (when possible) Speculatively parallel threads Special-purpose processing units (e.g., DSP functionality) Elaborate memory hierarchy Elaborate inter-chip communication facilities Characteristics of superscalar, simultaneous multithreading, and chip multiprocessor architectures Characteristic Number of CPUs' CPU issue width Number of threads Architecture registers (for integer and floating point) Physical registers (for integer and floating point Instruction window size Branch predictor table size (entries) Return stack size Instruction (I) and data (D) cache organization I and D cache sizes I and D cache associativities I and 0 cache line sizes (bytes) I and P cache access times (cycles) Secondary cache organization (Mbytes) Secondary cache size (bytes) Secondary cache associativity Secondary cache line size (bytes) Secondary cache access time (cycles) Secondary cache occupancy per access (cycles) Memory organization (no. of banks) Memory access time (cycles) Memory occupancy per access (cycles) Simultaneous Chip Superscalar multithreading multiprocessor 1 1 8 12 12 2 per CPU 1 8 1 per CPU 32 32 per thread 32 per CPU 32 + 256 256 + 256 32 + 32 per CPU 256 256 32 per CPU 32,768 32,768 8x4,096 64 entries 64 entries 8x8 entries 1x8 banks 1x8 banks 1 bank 128 kbytes 128 kbytes 16 kbytes per CPU 4-way 4-way 4-way 32 32 32 2 2 1 1x8 banks 1x8 banks 1x8 banks 8 8 8 4-way 4-way 4-way 32 32 32 5 5 7 1 1 1 4 4 4 50 50 50 13 13 13 The microprocessor tomorrow When we say “microprocessor” tomorrow, we generally mean the shaded area of the figure Outline •Technology Trends •Process Technology Challenges – Low Power Design •Microprocessors’ Generations •Challenges in Education Outline Challenges in Education •Changes in curricula •Fundamentals •A sort of the challenge we should accept Chalenges in Education It has often said that: Where you stand depends on where you sit In this context, starting from our positions an experiences, this is our view concerning the theme How shall we satisfy the long-term educational needs of engineers? How to organize a training of new engineers ? The engineers we are training today will still be practicing 40 years from now Are we preparing them for what they will be doing then? Is the whole system of engineering education – not just the undergraduate curriculum – organized to support today’s graduate for the next 40 years ? We think not on both counts Our view & our experience Our view is that the practice of engineering is rapidly changing, and that engineering education is not keeping up Our experiences are primarily in information technology (both in academy and industry), which, admittedly, has changed more rapidly than same other fields. Changes in curricula It is almost a cliché to talk about change – so mach so that a passing reference to it becomes a substitute for serious thought about its implications But the fact is that the practice of engineering is changing at about the same pace as the technology it creates What are fundamentals The undergraduate curriculum should teach (only) fundamentals Everyone agrees with that But what are fundamentals? Since the adoption of the engineering science model, the fundamentals have been largely continuous mathematics and physics But, as we said earlier, engineering is changing What kinds of fundamentals we need now – some examples Information technology (IT) will be embedded in virtually engineered product and process in the future – i.e., the design space for all engineers will include IT Discrete mathematics, not continuous math., is the underpinning of IT. It is a new fundamental Biological materials and process are a bit behind IT in their impact on engineering, but they a closing fast Thus the chemical and biological sciences are also becoming fundamental to engineering Kinds of Fundamentals Engineering systems are increasingly complex, and increasingly contain components from across the spectrum of traditional engineering fields. More knowledge of the full spectrum will be the fundamental Engineering is global, and is performed in a holistic business context The engineer must design under constraints that include global cultural and business contexts, and so must understand them. They two are new fundamentals. How to add these new fundamentals The challenge is that we cannot just add these new fundamentals to a curriculum that is already too full. We have to look critically at the current cherished fundamentals and either displace them or find ways to cover them much more rapidly. What will the character and essence of electrical and computer engineering education look like in the future ? It is difficult to predict the future with any accuracy, but it is safe to say that: Web-based teaching, distance learning, electronic books, and interactive learning environments will play increasingly significant roles in shaping what we teach, how we teach, and how students learn. A sort of challenge we should accept During one visit at our faculty, Prof. Krishna Shenai from University of Illinois of Chicago, director of Micro Systems Research Center says to us that he has never seen a process that cannot be speeded up by a factor of two and improved in quality at the same time. That is the sort of challenge we should accept for improving engineering education.