Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Lower and Upper Bounds on
Obtaining History Independence
Niv Buchbinder and Erez Petrank
Technion, Israel
What is History Independent DataStructure ?
• Sometimes data structures keep unnecessary
information.
– not accessible via the legitimate interface of the
data structure (the content) ,
– can be restored from the data-structure memory
layout.
• A privacy issue if an adversary gains control
over the data-structure layout.
The core problem: history of operations
applied on the data-structure may be revealed.
Weak History Independence
[Micciancio]: A Data structure implementation is
(weakly) History Independent if:
Any two sequences of operations S1 and S2
that yield the same content induce the same
distribution on memory layout.
Security: Nothing gained from layout
beyond the content.
Weak History Independence
Problems
No Information leaks if adversary gets
layout once (e.g., the laptop was stolen).
But what if adversary may get layout
several times ?
• Information on content modifications
leaks.
• We want: no more information leakage.
Strong History Independence
[Naor-Teague]: A Data structure implementation
is (Strongly) History Independent if:
Pair of sequences S1, S2
two lists of stop points in S1, S2
If content is the same in each pair of
corresponding stop points
Then: Joint distribution of memory layouts at
stop points is identical in the two sequences.
Security: We cannot distinguish between
any such two sequences.
A Short History of History
Independence
• [Micciancio97] Weak history independent 2-3
tree (motivated by the problem of private
incremental cryptography [BGG95]).
• [Naor-Teague01] History-independent hashtable, union-find. Weak history-independent
memory allocation.
• All above results are efficient.
• [Hartline et al. 02]
– Strong history independence means canonical
layout.
– Relaxation of strong history independence.
– History independent memory resize.
Our Results
1. Separations between strong & weak (lower
bounds):
Strong requires a much higher efficiency
penalty in the comparison based model.
For example, the queue data structure:
weak history independence requires O(1)
strong history independence requires Ω(n)
2. Implementations (upper bounds):
The heap has a weakly history independent
implementation with no time complexity penalty.
Bounds Summary
Operation
Weak History Strong History
Independence Independence
heap: insert
O(log n)
Ω(n)
heap: increase-key
O(log n)
Ω(n)
heap: extract-max
O(log n)
No lower bound
heap: build-heap
O(n)
Ω(n log n)
queue: max{ insertfirst, remove-last}
O(1)
Ω(n)
Why is Comparison Based
implementation important?
• It is “natural”:
– Standard implementations for most data
structure operations are like that.
– Therefore, we should know not to design
this way when seeking strong history
independence
• Library functions are easy to use:
– Only implement the comparison operation
on data structure elements.
Strong History Independence
=
Canonical Representation
Lemma [Hartline et al. 02]: Any strongly
history independent implementation of “wellbehaved” data-structure is canonical.
Any possible content has one possible layout.
Well behaved: the content graph is strongly
connected.
(Most data structures are like that)
Lower Bounds
Main Lemma:
D: Data-structure whose content is the set of
keys stored inside it.
I: Implementation of D that is :
comparison-based and canonical.
The following operations require time Ω(n).
• Insert(D, x)
• Extract(D, x)
• Increase-key(D, v1, v2)
More Lower Bounds
The main lemma applies for a comparison based
strong history independent:
• Heaps
• Dictionaries
• Search trees
• And others…
By similar methods we can show:
• For a Heap:
Build-Heap Operation requires time Ω(n log n).
• For a queue: either Insert-first or Remove-Last
requires time Ω(n).
The Binary Heap
Binary heap - a simple implementation of a priority
queue.
• The keys are stored in an almost full binary
tree.
• Heap property - For each node i:
Val(parent(i)) Val(i)
10
• Assume that all values in the
heap are unique.
7
9
6
1
4
5
2
8
3
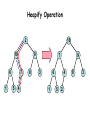
The Binary Heap: Heapify
Heapify - used to preserve the heap property.
• Input: a root and two proper sub-heaps of
height h-1.
• Output: a proper heap of height h.
2
The node always chooses to
sift down to the direction
of the larger value.
10
6
1
9
7
5
4
8
3
Heapify Operation
2
10
10
9
6
1
7
5
4
8
7
3
9
6
1
4
5
2
8
3
Reversing Heapify
heapify-1: “reversing” heapify:
Heapify-1(H: Heap, i: position)
• Root val(i)
• All the path from the root
to node i are shifted down.
The parameter i is a
position in the heap H
10
7
9
6
1
4
5
2
8
3
Heapify-1 Operation
10
2
7
9
6
1
4
5
2
8
10
3
9
6
1
7
5
8
4
Property: If all the keys in the heap are
unique then for any i:
Heapify(Heapify-1(H, i)) = H
3
Reversing Build-heap
Building a heap - applying heapify on any sub-tree
in the heap in a bottom up manner.
We define a randomized procedure Build-Heap-1:
• Uses Heapify-1 procedure
• The procedure Works in a Top-Bottom manner.
• Returns a permutation (tree).
For any random choice:
Build-heap(Build-heap-1(H)) = H
Uniformly Chosen Heaps
• Build-heap is a Many-To-One procedure.
• Build-heap-1 is a One-To-Many procedure
depending on the random choices.
Support(H) : The set of permutations (trees)
such that build-heap(T) = H
Facts (without proof):
1. For each heap H the size of Support(H) is
the same.
2. Build-heap-1 returns one of these permutations
uniformly.
How to Obtain a Weak
History Independent Heap
Main idea: keeping a uniformly random heap at
all time.
We want:
1. Build-heap: Return one of the possible heaps
uniformly.
2. Other operations: preserve this property.
Heap Implementation
Build-Heap and Increase-key are easy to
handle.
• A simple extension of standard operation.
• Efficiency maintained.
Extract-Max, Insert:
The standard extract-max and Insert operations
are NOT weakly history independent.
Naive Implementation: Extract-max
Extract-max(H)
1. T = build-heap-1(H)
2. Remove the last node v in the tree (T’).
3. H’ = build-heap(T’)
4. If we already removed the maximal value
return H’ Otherwise:
5. Replace the root with v and let v sift down
to its correct position.
build-heap-1 and build-heap works in O(n)
… but this implementation is history
independent.
Improving Complexity: Extract-max
First 3 steps of Extract-max(H)
1. T = build-heap-1(H)
2. Remove the last node v in the tree.
3. H’ = build-heap(T’)
Main problem - steps 1 to 3 that takes O(n).
Simple observation reduces the complexity of these
steps to O(log2(n)) instead of O(n)
Reducing the Complexity to O(log2(n))
Observation:
Most of the operations of build-heap-1 are redundant.
They are always canceled by the operation of buildheap. Only the operations applied on nodes lying on
the path from the root to the last leaf are needed.
Complexity analysis:
• Each heapify-1 and heapify
operation takes at most O(log n).
• There are O(log n) such
operations.
6
1
10
7
9
4
5
2
8
3
Reducing the Complexity:
O(log(n)) Expected Time
This is the most complex part
Main ideas:
• We can show that there are actually O(1)
operations of heapify-1 and heapify that make
a difference (in average over the random
choices made by the algorithm in each step).
• We can detect these operations and apply only
them.
Conclusions
1. Demanding strong history independence
usually requires a high efficiency penalty in
the comparison based model.
2. Weak history independent heap in the
comparison-based model without penalty,
Complexity:
• build-heap
- O(n) worst case.
• increase-key
- O(log n) worst case.
• extract-max, insert- O(log n) expected time,
O(log2n) worst case.
Open Questions
1. Is weak and strong History independence
different in terms of efficiency also in the
general (not comparison-based) model ?
2. History independent implementation of more
data structures.
Thank you