Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
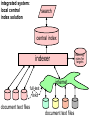
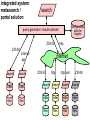
Eric Sieverts University Library Utrecht IT Department Institute for Media & Information Management (Hogeschool van Amsterdam) Google and/or/not databases • why using search engines ? • functionality of search engines (including the latest technology) • what is hidden for search engines ? • search engines databases • why would people prefer google ? • what is up for us, librarians ? Eric Sieverts | [email protected] | http://www.library.uu.nl/medew/it/eric | Bielefeld 2002 Conference, 7 febr 2002 why using search engines ? • easy to use best match technique • such a good relevance ranking (at least some of them) • still a lot of additional (hidden) functionality • recent language technological methods • such large collections Eric Sieverts | [email protected] | http://www.library.uu.nl/medew/it/eric | Bielefeld 2002 Conference, 7 febr 2002 why using search engines ? some common document ranking parameters • the more terms from your query in a document, the better (now for most engines only "all the terms") • the more prominent a term in a document, the better (in <title>, in the first few sentences, in a <meta> tag) • the more frequently repeated a search term, the better • the closer together the terms in a document, the better • the more uncommon a search term, the higher its weight • the more "popular" a web-page, the better (more hyperlinks pointing to it, more people visiting it, ..) google’s strong point Eric Sieverts | [email protected] | http://www.library.uu.nl/medew/it/eric | Bielefeld 2002 Conference, 7 febr 2002 why using search engines ? google offers a lot of additional functionality • boolean search (if you really want to - I do occasionally!) • "citation" search (other web-pages linking to "this" site) • similarity search (means here: similar linking patterns; not really better than word-based similarity search) • disappeared documents in result set can be retrieved from archive cache • many other document types than just plain html • also image search, usenet archives, integration of open directory subject tree see google Eric Sieverts | [email protected] see google advanced search | http://www.library.uu.nl/medew/it/eric | Bielefeld 2002 Conference, 7 febr 2002 why using search engines ? modern language technology aboard categorisation of result sets • (formerly) northernlight's custom search folders (rulebased method) • teoma (statistics based method) • wisenut (statistics based method) • fast-alltheweb (statistics based method) teoma Eric Sieverts | [email protected] | wisenut http://www.library.uu.nl/medew/it/eric | Bielefeld 2002 Conference, 7 febr 2002 why using search engines ? search engine “sizes” see for instance “search engine watch” december 2001 search engine watch Eric Sieverts | [email protected] | http://www.library.uu.nl/medew/it/eric | Bielefeld 2002 Conference, 7 febr 2002 what is hidden for (most) search engines ? (and consequently for their users ! ) non-HTML documents: flash, office-files, pdf (not fundamentally impossible, as google demonstrates) "real-time" data (too difficult to keep track) dynamically, database generated pages (out of fear for spider traps; but google seems to do it) all information hidden in searchable databases (spiders cannot fill out database search forms) to-be-paid-for or licensed information (bibliographic databases, full-text scientific journals, ....) all information that is not (yet) on the web Eric Sieverts | [email protected] | http://www.library.uu.nl/medew/it/eric | Bielefeld 2002 Conference, 7 febr 2002 search engines vs. databases besides - for us obvious - differences in content: differences in functionality database search engine field searching modern retrieval technology boolean, proximity, truncation relevance ranking controlled vocabulary ease of use - categories - thesauri - etc but do users use all of this ?? despite its importance !! Eric Sieverts | [email protected] | http://www.library.uu.nl/medew/it/eric | Bielefeld 2002 Conference, 7 febr 2002 why do students graduate on google" ? why do so many users prefer the use of search engines ? apparent simplicity of search engine interface too many separate other search systems to address overwhelming choice of databases overwhelming choice of digital primary sources example example plethora of different database system interfaces interfaces crowded with "functionality" what would you use ? – if you did't know what's the difference – if you did't know what you'd miss Eric Sieverts | [email protected] | http://www.library.uu.nl/medew/it/eric | Bielefeld 2002 Conference, 7 febr 2002 do you miss so much with only google ? • google also indexes .PDF , .DOC , .PPT , .XLS , .RTF • the web also contains preprints, reports, projects etc. that are NOT in databases • many scientists (and others) put copies of their published articles on their personal websites that seems fine, but you still get low recall, because: • the web remains a very fragmented incomplete mess (behind that simple google screen) • it is not indexed consistently and in a controlled way but for many users lousy recall is no problem at all ..... Eric Sieverts | [email protected] | http://www.library.uu.nl/medew/it/eric | Bielefeld 2002 Conference, 7 febr 2002 what is up for libraries ? • realise better integrated access to all our precious (and expensive) information sources • realise more advanced retrieval possibilities while keeping the advances of controlled indexing as well central index solution meta-search / portal solution - our own choice of advanced local search engine / retrieval software - problems with indexing remotely stored data - problems with non-uniform controlled indexing - many remote and locally available retrieval systems addressed in a single query (via Z39.50, http, etc.) - restricted to common denominator of classical boolean functionality - problems with non-uniform controlled indexing Eric Sieverts | [email protected] | http://www.library.uu.nl/medew/it/eric | Bielefeld 2002 Conference, 7 febr 2002 integrated system: local central index solution search central index indexingrules for targets indexer internet full-text links document text files document text files integrated system: metasearch / portal solution search configuration data for targets query-generator / result-collector Z39.50 Z39.50 internal api search search index index files files http internet Z39.50 http http xml Z39.50 search search search search index index index index files files files files and some look into the (near) future .... library based search systems will improve performance of web search engines will improve as well - automatic methods of uniform classification and controlled keyword indexing - more flexible xml-based methods for metasearch-solutions (srw, sru) - improved access to remote data to be locally indexed - xml, rdf metadata & the semantic web will improve concept- and meaning- based retrieval on the web - ever more information will be available on the web - newest technologies will continue to be tested on the web first competition between “ Eric Sieverts | [email protected] “ and "our databases" will continue | http://www.library.uu.nl/medew/it/eric | Bielefeld 2002 Conference, 7 febr 2002