Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Entity–attribute–value model wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Open Database Connectivity wikipedia , lookup
Concurrency control wikipedia , lookup
Functional Database Model wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Relational model wikipedia , lookup
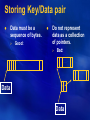
Lecture 2: Beyond Relational Databases Prof. Shahram Ghandeharizadeh Director of USC Database Lab http://dblab.usc.edu Computer Science Department University of Southern California An Emerging Phenomena User 1 Application programs DBMS User 2 Application programs Data managed by DBMS Why? Marketing campaigns have become too exaggerated! Relational vendors claim RDBMS is the answer to all data management needs. Not true. What are some examples? Data Warehousing Retail organizations record every customer transaction, producing Terabytes of data. Objective: Mine database for information about customers purchasing patterns, trends in product popularity, geographical preferences, and others. Database characteristics: Large tables (tens of Terabytes in size), Updated in bulk periodically, Read by analysts invoking tools to mine trends. Queries access only a few of the many columns in a table, and scan tables sorted in different ways. Directory Services International organizations with distributed resources and personnel. LDAP standard Requirement: fast lookup of entities arranged in a hierarchical structure that corresponds to a hierarchy of the organizaiton. Core of identification and authentication system from a number of vendors, e.g., IBM Tivoli, Microsoft Active Directory Server, SUN ONE Directory Server. Bulk updates similar to data warehousing. Multi-valued attributes. Queries are single-row retrieval or lookups based on attribute values. Web Search Semi-structured data Queries are keyword lookups and the desired response is a sorted list of possible answers. HTML pages instead of raw data. Need for efficient inverted indices. Bulk updates, read mostly. Need for nontraditional indexing. Other Examples Mobile device caching Stream management Your cell phone’s directory as a transient cache of a global directory. Real-time filtering of streams for interesting patterns. Example: identify hotly traded stock, or a stock that is not traded as heavily as expected. Filters look like SQL selection predicates, causing developers to mistake a RDBMS as the right choice. XML management Summary Relational DBMS have been designed for transaction processing and workloads consisting of ad hoc queries and significant amount of updates. Example applications are read-dominated: 25 years ago, One market for DBMS: Business data processing. This has changed to include different applications with different requirements. No need for transactional guarantees. SQL is the wrong choice for stream processing. One software architecture will not support the diverse needs of these applications. Possible solutions: 1) each application re-builds its own storage manager from scratch, 2) provide a flexible solution that can be tailored to the needs of a particular application. A handful of configurable storage systems, each of which is useful across a broad application class. Evolution Before having a handful of configurable storage managers: After having a handful of configurable storage managers: Requirements A flexible storage manager must be: Modular Configurable An application should not have to “pay” for a functionality that it does not use. “Pay” means: Adapt to the hardware and software environment of the application. Physical data design (physical clustering, choice of indexes, internal structure of items in the database). Memory consumption, Disk and CPU utilization. Application developer should be able to exclude major subsystems. Ultimate goal Modularity Simple, re-usable, plug-n-play components. View a transaction processing system as: A single table selection component that has a B+ tree index that supports simple indexing, updating and selection. Add concept of transactions. Add a select-project-join operator Add aggregates ….. Transforms a sophisticated system to a collection of components. Each component may support a large number of application domains. Data Availability High availability and data replication as components Challenge: the component must fit in a company’s high availability infrastructure, e.g., heartbeat protocols to detect failures, fail-over techniques, and redundant communication channels. Modularity: Advantages Modularity manages size and complexity of the final application while also enabling the application and data management capabilities to seamlessly interact. Modularity provides for extensibility (not provided by a monolithic system). Example: A transactional system consists of a transaction manager, a lock manager, and a log manager. If these modules are open and extensible then the developer may build systems that incorporate items that are not managed by the database itself. A network switch with an operation such as “power up the backup network interface card” as a transaction using locking and logging components. Configurability While modularity is an architectural mechanism, configuration is mostly an initialization and runtime mechanism. Configure the system with a buffer pool size of 1 GB and disk page size of 32K. Space consumed by transaction logs. Buffer pool size is a run-time parameter. Disk page size is an initialization parameter. Why? Configurability refers to how well a system can be matched to its environment and application requirements. Underlying hardware platform: PDAs, embedded systems, 64-way multiprocessor with gigabytes of DRAM. Neutral to different network protocols and how a developer may decide to use a protocol. Different Operating Systems: Linux, Windows (to be portable, storage manager must use common services to different OSs). Whether database is main memory resident or not. A configurable system would try to use the CPU cache. Use of compression is another good example. It depends on the hardware platform, and tradeoff associated with the amount of power consumed by the processor to compress versus transmitting larger chunks. Flash as a layer in the memory hierarchy. Challenge: sensitive to the number of write operations. Spectrum of configuration Ideally, a full spectrum of possible choices should be supported (relative to the extreme ends of the spectrum). Different policies such be implemented by the same transactional component. Data in main memory with no xact guarantees Persistence with full xact guarantees Physical Data Design A configurable storage manager must support components for physical layout of data and indexing techniques: Physical clustering: design & runtime decisions. Indexing mechanism (B+-tree, Hash): runtime configuration decisions. Grouping of relevant data to enhance cache hit ratio and minimize seek time. The criteria used for clustering is paramount. Extensibility means the developer may introduce a new indexing mechanism as a component. Internal structure of items in the database: design decision. Application is King! At the end of the day, the choice of a storage manager must match the requirements of an application! If the requirements of an application calls for use of relational technology with SQL then DO use such a system. Think as follows: you have options when it comes to data management, and you should select the right tool to get the job done as efficiently, robustly, and simply as possible. Homework 1 Download C++ version of Berkeley DB storage manager, compile it using Visual Studio, author a project to insert 100 records into a database. Each record has the following attributes: Id: an integer (4 bytes) MemberName: a variable sized array of characters constructed by concatenating a string token (JaneDoe) with the id. Age: an integer (4 bytes) and a function of the record Id; Age = 20 + (id % 15) Salary: an integer (4 bytes) and a function of age; Salary = 40,000 + (Age * 1000) Homework 1 Due date: January 27th lunch time. Assumption: You’ll use your own PC/laptop. Let me know if you need access to resources and we’ll try to make SAL 200C available. Please send email by Thursday, Jan 22nd at the latest. Visual studio 2005 SP1 is available to you for free download. Use Google with keywords “Visual Studio 2005 SP1 Free” Steps to download BDB Download Berkeley DB from http://www.oracle.com/technology/software/products/berkeleydb/index.html Download Berkeley DB 4.7.25.zip Extract db-4.7.25 folder Place it under the projects folder in your Visual Studio Open project in db-4.7.25\build_windows (help pages in http://doc.gnudarwin.org/ref/build_win/intro.html) Make sure your Platform is Win32 and Configuration is Debug x86. Check mark db_dll as your build. Start to compile. Introduce a new “Win32 Console Application” project with your desired project name. This will contain the code that you will write for your homework. Build your new project to make sure that it does build. Now, you are ready to add code your software. Start by including “db.h” file and the BDB library that you just compiled. In the “Property Pages” add a new reference to your compiled db_dll In the “Property Pages”, choose “Configuration Properties”, expand “C/C++”, choose general and type in the absolute path of build_windows in the “Additional Include Directories” Make sure your project compiles with a simple “db.h” addition. Berkeley DB Start to read the manual (in the docs directory). Make sure you understand: A database is a collection of key/data pairing. Flags are used to create a database and open a database. Use of secondary index structures is somewhat complicated and requires a careful read of documentation and sample code. Storing Key/Data pair Make sure you understand the concept of a pointer and the memory space the pointer points to. Storing Key/Data pair Data must be a sequence of bytes. Good: Do not represent data as a collection of pointers. Bad: Data Data