Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
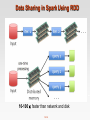
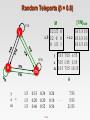
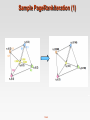
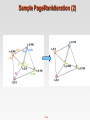
COMP9313: Big Data Management Lecturer: Xin Cao Course web site: http://www.cse.unsw.edu.au/~cs9313/ Chapter 12: Revision and Exam Preparation 12.2 Learning outcomes After completing this course, you are expected to: elaborate the important characteristics of Big Data (Chapter 1) develop an appropriate storage structure for a Big Data repository (Chapter 5) utilize the map/reduce paradigm and the Spark platform to manipulate Big Data (Chapters 2, 3, 4, and 7) use a high-level query language to manipulate Big Data (Chapter 6) develop efficient solutions for analytical problems involving Big Data (Chapters 8-11) 12.3 Final exam Final written exam (100 pts) Six questions in total on six topics Three hours You can bring the printed lecture notes If you are ill on the day of the exam, do not attend the exam – I will not accept any medical special consideration claims from people who already attempted the exam. 12.4 Topic 1: MapReduce (Chapters 2 and 3) 12.5 Data Structures in MapReduce Key-value pairs are the basic data structure in MapReduce Keys and values can be: integers, float, strings, raw bytes They can also be arbitrary data structures The design of MapReduce algorithms involves: Imposing the key-value structure on arbitrary datasets E.g.: for a collection of Web pages, input keys may be URLs and values may be the HTML content In some algorithms, input keys are not used, in others they uniquely identify a record Keys can be combined in complex ways to design various algorithms 12.6 Map and Reduce Functions Programmers specify two functions: map (k1, v1) → list [<k2, v2>] Map transforms the input into key-value pairs to process reduce (k2, [v2]) → [<k3, v3>] Reduce aggregates the list of values for each key All values with the same key are sent to the same reducer Optionally, also: combine (k2, [v2]) → [<k3, v3>] Mini-reducers that run in memory after the map phase Used as an optimization to reduce network traffic partition (k2, number of partitions) → partition for k2 Often a simple hash of the key, e.g., hash(k2) mod n Divides up key space for parallel reduce operations The execution framework handles everything else… 12.7 Combiners Often a Map task will produce many pairs of the form (k,v1), (k,v2), … for the same key k E.g., popular words in the word count example Combiners are a general mechanism to reduce the amount of intermediate data, thus saving network time They could be thought of as “mini-reducers” Warning! The use of combiners must be thought carefully Optional in Hadoop: the correctness of the algorithm cannot depend on computation (or even execution) of the combiners A combiner operates on each map output key. It must have the same output key-value types as the Mapper class. A combiner can produce summary information from a large dataset because it replaces the original Map output Works only if reduce function is commutative and associative In general, reducer and combiner are not interchangeable 12.8 Partitioner Partitioner controls the partitioning of the keys of the intermediate map-outputs. The key (or a subset of the key) is used to derive the partition, typically by a hash function. The total number of partitions is the same as the number of reduce tasks for the job. This controls which of the m reduce tasks the intermediate key (and hence the record) is sent to for reduction. System uses HashPartitioner by default: hash(key) mod R Sometimes useful to override the hash function: E.g., hash(hostname(URL)) mod R ensures URLs from a host end up in the same output file Job sets Partitioner implementation (in Main) 12.9 A Brief View of MapReduce 12.10 MapReduce Data Flow 12.11 MapReduce Data Flow 12.12 Design Patter 1: Local Aggregation Programming Control: In mapper combining provides control over when local aggregation occurs how it exactly takes place Hadoop makes no guarantees on how many times the combiner is applied, or that it is even applied at all. More efficient: The mappers will generate only those key-value pairs that need to be shuffled across the network to the reducers There is no additional overhead due to the materialization of key-value pairs Combiners don't actually reduce the number of key-value pairs that are emitted by the mappers in the first place Scalability issue (not suitable for huge data) : More memory required for a mapper to store intermediate results 12.13 Design Patter 2: Pairs vs Strips The pairs approach Keep track of each team co-occurrence separately Generates a large number of key-value pairs (also intermediate) The benefit from combiners is limited, as it is less likely for a mapper to process multiple occurrences of a word The stripe approach Keep track of all terms that co-occur with the same term Generates fewer and shorted intermediate keys The framework has less sorting to do Greatly benefits from combiners, as the key space is the vocabulary More efficient, but may suffer from memory problem These two design patterns are broadly useful and frequently observed in a variety of applications Text processing, data mining, and bioinformatics 12.14 Design Pattern 3: Order Inversion Common design pattern Computing relative frequencies requires marginal counts But marginal cannot be computed until you see all counts Buffering is a bad idea! Trick: getting the marginal counts to arrive at the reducer before the joint counts Caution: You need to guarantee that all key-value pairs relevant to the same term are sent to the same reducer 12.15 Design Pattern 4: Value-to-key Conversion Put the value as part of the key, make Hadoop do sorting for us Provides a scalable solution for secondary sorting. Caution: You need to guarantee that all key-value pairs relevant to the same term are sent to the same reducer 12.16 Topic 2: Spark (Chapter 7) 12.17 Data Sharing in MapReduce Slow due to replication, serialization, and disk IO Complex apps, streaming, and interactive queries all need one thing that MapReduce lacks: Efficient primitives for data sharing 12.18 Data Sharing in Spark Using RDD 10-100× faster than network and disk 12.19 What is RDD Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In- Memory Cluster Computing. Matei Zaharia, et al. NSDI’12 RDD is a distributed memory abstraction that lets programmers perform in-memory computations on large clusters in a faulttolerant manner. Resilient Fault-tolerant, is able to recompute missing or damaged partitions due to node failures. Distributed Data residing on multiple nodes in a cluster. Dataset A collection of partitioned elements, e.g. tuples or other objects (that represent records of the data you work with). RDD is the primary data abstraction in Apache Spark and the core of Spark. It enables operations on collection of elements in parallel. 12.20 RDD Operations Transformation: returns a new RDD. Nothing gets evaluated when you call a Transformation function, it just takes an RDD and return a new RDD. Transformation functions include map, filter, flatMap, groupByKey, reduceByKey, aggregateByKey, filter, join, etc. Action: evaluates and returns a new value. When an Action function is called on a RDD object, all the data processing queries are computed at that time and the result value is returned. Action operations include reduce, collect, count, first, take, countByKey, foreach, saveAsTextFile, etc. 12.21 Working with RDDs Create an RDD from a data source by parallelizing existing Python collections (lists) by transforming an existing RDDs from files in HDFS or any other storage system Apply transformations to an RDD: e.g., map, filter Apply actions to an RDD: e.g., collect, count Users can control two other aspects: Persistence Partitioning 12.22 RDD Operations 12.23 More Examples on Pair RDD Create a pair RDD from existing RDDs val pairs = sc.parallelize( List( (“This”, 2), (“is”, 3), (“Spark”, 5), (“is”, 3) ) ) pairs.collect().foreach(println) Output? reduceByKey() function: reduce key-value pairs by key using give func val pair1 = pairs.reduceByKey((x,y) => x + y) pairs1.collect().foreach(println) Output? mapValues() function: work on values only val pair2 = pairs.mapValues( x => x -1 ) pairs2.collect().foreach(println) Output? groupByKey() function: When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs pairs.groupByKey().collect().foreach(println) 12.24 Topic 3: Link Analysis (Chapter 8) 12.25 PageRank: The “Flow” Model A “vote” from an important page is y/2 worth more y A page is important if it is pointed to by other important pages a/2 y/2 Define a “rank” rj for page j a ri rj i j di m a/2 “Flow” equations: ry = ry /2 + ra /2 ra = ry /2 + rm rm = ra /2 12.26 m Google’s Solution: Random Teleports di … out-degree of node i 12.27 The Google Matrix 12.28 Random Teleports ( = 0.8) [1/N]NxN M 7/15 y 1/2 1/2 0 0.8 1/2 0 0 0 1/2 1 y 7/15 7/15 1/15 a 7/15 1/15 1/15 m 1/15 7/15 13/15 13/15 a 1/3 1/3 1/3 + 0.2 1/3 1/3 1/3 1/3 1/3 1/3 m A y a = m 1/3 1/3 1/3 0.33 0.20 0.46 0.24 0.20 0.52 12.29 0.26 0.18 0.56 ... 7/33 5/33 21/33 Topic-Specific PageRank Random walker has a small probability of teleporting at any step Teleport can go to: Standard PageRank: Any page with equal probability To avoid dead-end and spider-trap problems Topic Specific PageRank: A topic-specific set of “relevant” pages (teleport set) Idea: Bias the random walk When walker teleports, she pick a page from a set S S contains only pages that are relevant to the topic E.g., Open Directory (DMOZ) pages for a given topic/query For each teleport set S, we get a different vector rS 12.30 Matrix Formulation 12.31 Hubs and Authorities j1 j2 j3 j4 i i j1 12.32 j2 j3 j4 Hubs and Authorities 12.33 Hubs and Authorities Convergence criterion: Repeated matrix powering 12.34 Example of HITS 111 A= 101 010 110 AT = 1 0 1 110 Yahoo Amazon M’soft h(yahoo) = h(amazon) = h(m’soft) = .58 .80 .80 .58 .53 .53 .58 .27 .27 .79 .57 .23 ... ... ... .788 .577 .211 a(yahoo) = a(amazon) = a(m’soft) = .58 .58 .62 .58 .58 .49 .58 .58 .62 .62 .49 .62 ... ... ... .628 .459 .628 12.35 Topic 4: Graph Data Processing 12.36 From Intuition to Algorithm Data representation: Key: node n Value: d (distance from start), adjacency list (list of nodes reachable from n) Initialization: for all nodes except for start node, d = Mapper: m adjacency list: emit (m, d + 1) Sort/Shuffle Groups distances by reachable nodes Reducer: Selects minimum distance path for each reachable node Additional bookkeeping needed to keep track of actual path 12.37 Multiple Iterations Needed Each MapReduce iteration advances the “known frontier” by one hop Subsequent iterations include more and more reachable nodes as frontier expands The input of Mapper is the output of Reducer in the previous iteration Multiple iterations are needed to explore entire graph Preserving graph structure: Problem: Where did the adjacency list go? Solution: mapper emits (n, adjacency list) as well 12.38 BFS Pseudo-Code Equal Edge Weights (how to deal with weighted edges?) Only distances, no paths stored (how to obtain paths?) class Mapper method Map(nid n, node N) d ← N.Distance Emit(nid n,N) //Pass along graph structure for all nodeid m ∈ N.AdjacencyList do Emit(nid m, d+w) //Emit distances to reachable nodes class Reducer method Reduce(nid m, [d1, d2, . . .]) dmin←∞ M←∅ for all d ∈ counts [d1, d2, . . .] do if IsNode(d) then M←d //Recover graph structure else if d < dmin then //Look for shorter distance dmin ← d M.Distance ← dmin //Update shortest distance Emit(nid m, node M) 12.39 Stopping Criterion How many iterations are needed in parallel BFS (equal edge weight case)? Convince yourself: when a node is first “discovered”, we’ve found the shortest path Now answer the question... The diameter of the graph, or the greatest distance between any pair of nodes Six degrees of separation? If this is indeed true, then parallel breadth-first search on the global social network would take at most six MapReduce iterations. 12.40 BFS Pseudo-Code (Weighted Edges) The adjacency lists, which were previously lists of node ids, must now encode the edge distances as well Positive weights! In line 6 of the mapper code, instead of emitting d + 1 as the value, we must now emit d + w, where w is the edge distance The termination behaviour is very different! How many iterations are needed in parallel BFS (positive edge weight case)? Convince yourself: when a node is first “discovered”, we’ve found the shortest path 12.41 Additional Complexities search frontier r s q p Assume that p is the current processed node In the current iteration, we just “discovered” node r for the very first time. We've already discovered the shortest distance to node p, and that the shortest distance to r so far goes through p Is s->p->r the shortest path from s to r? The shortest path from source s to node r may go outside the current search frontier It is possible that p->q->r is shorter than p->r! We will not find the shortest distance to r until the search frontier expands to cover q. 12.42 Computing PageRank Properties of PageRank Can be computed iteratively Effects at each iteration are local Sketch of algorithm: Start with seed ri values Each page distributes ri “credit” to all pages it links to Each target page tj adds up “credit” from multiple in-bound links to compute rj Iterate until values converge 12.43 Simplified PageRank First, tackle the simple case: No teleport No dangling nodes (dead ends) Then, factor in these complexities… How to deal with the teleport probability? How to deal with dangling nodes? 12.44 Sample PageRank Iteration (1) 12.45 Sample PageRank Iteration (2) 12.46 PageRank Pseudo-Code 12.47 Complete PageRank Two additional complexities What is the proper treatment of dangling nodes? How do we factor in the random jump factor? Solution: If a node’s adjacency list is empty, distribute its value to all nodes evenly. In mapper, for such a node i, emit (nid m, ri/N) for each node m in the graph Add the teleport value In reducer, M.PageRank = * s + (1- ) / N 12.48 Topic 5: Streaming Data Processing Types of queries one wants on answer on a data stream: (we’ll learn these today) Sampling data from a stream Queries over sliding windows Number of items of type x in the last k elements of the stream Filtering a data stream Construct a random sample Select elements with property x from the stream Counting distinct elements (Not required) Number of distinct elements in the last k elements of the stream 12.49 Topic 6: Machine Learning Recommender systems User-user collaborative filtering Item-item collaborative filtering SVM Given you the training dataset, find out the optimal solution 12.50 CATEI and myExperience Survey 12.51 End of Chapter 12