Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
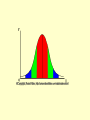
Chapter 12: Analysis of Quantitative Data • Introduction • Dealing with Data: Coding, Entering, and Cleaning • Descriptive Statistics – One Variable – Two Variables – More than Two Variables • Inferential Statistics • Conclusion Introduction • Data collected in quantitative research is in the form of – Numbers • To use this data, researchers: – Present it in charts or graphs – Reorganize it for computer analysis – Interpret or give theoretical meaning to it Chapter 12: Analysis of Quantitative Data • Introduction • Dealing with Data: Coding, Entering, and Cleaning • Descriptive Statistics – One Variable – Two Variables – More than Two Variables • Inferential Statistics • Conclusion Dealing with Data • Coding - reorganizing raw data into a format that – is easily entered into a computer – or is machine-readable. • Entering data – typically (see figure 12.1): – each row is a case – each column is a variable – Four means of entering: code sheet, direct-entry, optical scan, bar code • Cleaning data – checking the accuracy of coding and data entry. Chapter 12: Analysis of Quantitative Data • Introduction • Dealing with Data: Coding, Entering, and Cleaning • Descriptive Statistics – One Variable – Two Variables – More than Two Variables • Inferential Statistics • Conclusion Descriptive Statistics • Describe numerical data – one variable at a time (univariate) – two variables at a time (bivariate) – or more than two (multivariate) Chapter 12: Analysis of Quantitative Data • Introduction • Dealing with Data: Coding, Entering, and Cleaning • Descriptive Statistics – One Variable – Two Variables – More than Two Variables • Inferential Statistics • Conclusion Frequency Distributions • Summarize information – including counts and percentages – and cumulative counts and percentages – for nominal, ordinal, interval, or ratio measurements. • Graphic representations include the – Histogram – bar chart – pie chart Example of a histogram (showing two variables – each bar would be a univariate histogram) 90 80 70 60 East West North 50 40 30 20 10 0 1st Qtr 2nd Qtr 3rd Qtr 4th Qtr Example of a Pie Chart 1st Qtr 2nd Qtr 3rd Qtr 4th Qtr Measures of Central Tendency • Mode – the most common or frequently occurring number. • Median – the middle point or 50th percentile – used with ordinal, interval or ratio data • Mean – the arithmetic average used with interval or ratio level data – very sensitive to extreme values Example of mean vs. median We survey seven people and ask each how many alcoholic drinks he or she consumed in the past month. The results are Person 1 2 3 4 5 6 7 Drinks 0 1 3 4 5 6 80 The median number is 4 – three people consumed fewer, and three people consumed more The mean number is 14.14: the total number of drinks is 99, divided by 7 people is 14.4 From this example, you can see how ‘outliers’ – extreme values – affect the mean much more than the median. Measures of Variation • Variation is – the spread, dispersion, or variability – around the center of the distribution • Range – the distance between smallest and largest scores – e.g. ages might vary from a range of ages 21–59. • Percentiles – scores at a specific place within the distribution – if someone age 26 is at the 25th percentile, that means that 25% of the respondents were under age 26 Measures of Variation continued… • Standard deviation – an average distance of each score from the mean – A nice explanation on the web • Z score – a standardized score • What are standardized scores? – it represents the number of standard deviations of a particular score above or below the mean. • One standard deviation away from the mean in either direction on the horizontal axis (the red area on the above graph) accounts for somewhere around 68 percent of the people in this group. Two standard deviations away from the mean (the red and green areas) account for roughly 95 percent of the people. And three standard deviations (the red, green and blue areas) account for about 99 percent of the people. • If this curve were flatter and more spread out, the standard deviation would have to be larger in order to account for those 68 percent or so of the people. So that's why the standard deviation can tell you how spread out the examples in a set are from the mean. Chapter 12: Analysis of Quantitative Data • Introduction • Dealing with Data: Coding, Entering, and Cleaning • Descriptive Statistics – One Variable – Two Variables – More than Two Variables • Inferential Statistics • Conclusion Results with Two Variables • Bivariate statistics – indicate whether there is a statistical relationship between two variables • There are two possible relationships: – Covariation • two variables are associated statistically. – Independence • there is no association between two variables Seeing the relationship – the scattergram • a graph on which a social researcher plots each case or observation • each axis represents the value of one variable What can be learned from a scattergram? • Form - relationships can take three forms: – independence (no relationship) – linear (forming a straight line) – curvilinear (forming either a ‘u’ or an ‘s’ curve). • Direction - can be one of two values – positive, higher values on one variable go with higher values on the other – negative, higher values on one variable go with lower values on the other. What can be learned continued… • Precision – the amount of spread in the points on a graph – A high amount of precision occurs when the points hug the line that summarizes a relationship, – a low level of precision occurs when the points are widely spread out. Bivariate Contingency Table • presents the same information as a scattergram but in a more condensed fashion. • is ordinarily based on a cross tabulation of two variables at the same time. • Shows how the pattern of distribution of one variable is “contingent” on the other variable Percentage Tables • Be able to read a percentaged bivariate contingency table, such as table 12.1 on page 347 • Understand the difference between what is shown in a – Column-percentaged table – Row-percentaged table Reading a Percentage Table – Look At: • • the title, variable names, and any background information. the direction in which percentages have been computed, in rows or columns. – How do you tell? • See where the percentages total 100% (or near 100%) • the comparisons relevant to the cross tabulation. – – Comparisons are made in the opposite direction from that in which percentages are computed. Compare across if the table is percentaged down, compare down if percentaged across. Example from the text • Table 12.1, page 347 Measures of Association • A measure of association is a single number that expresses the strength, and often the direction, of a relationship between two or more variables. – It can help you interpret the pattern of data found in a bivariate contingency table • Researchers may choose from several different measures of association – The appropriate one depends partly on the level of measurement of the variables (nominal, ordinal, interval, or ratio) • Measures of association are lambda, gamma, tau, chi (squared), and rho. • If there is a strong association it means that there is a definite pattern in predicting scores on the dependent variable from variations in the independent variable. Measures of Association continued… • If there is a weak association it means that there is not much of a pattern between scores on the dependent variable compared to variations in the independent variable. • Measures of association normally range from 0.0 to +1.0, or from –1.0 to 0.0 to + 1.0. • In either case, the closer the association is to 1.0 (+ or -), the stronger the relationship is • The closer to 0.0, the weaker the association. Measures of Association, continued • Most measures of association follow a “proportionate reduction in error” logic: – How much does knowing the value of the independent variable, for each case, help in predicting the value of the dependent variable – The better the prediction, the greater the reduction in error Five Measures • Lambda is for nominal level data and ranges from 0.0 to 1.0 • Gamma is for ordinal level data, and it ranges from – 1.0 to 0.0 to +1.0 • Tau is for ordinal data, and is similar to Gamma’s range of –1.0 to 0.0 to +1.0 Five Measures continued… • Rho is Pearson’s Product Moment Correlation, – – – – – ranges from –1.0 to 0.0 to +1.0, for data at the interval or ration level. It is interpreted just like Gamma. It can only measure linear relationships (not curvilinear) It is the most commonly-used measure of correlation • R-squared – the commonly-used term for Rho-squared: – Tells what percentage of the variation in the dependent variable is caused by the independent variable • Chi Squared – can be used as a measure of association in descriptive statistics such as the others listed here – or it can be used in inferential statistics to test a null hypothesis. – It ranges from 0.0 to infinity. Chapter 12: Analysis of Quantitative Data • Introduction • Dealing with Data: Coding, Entering, and Cleaning • Descriptive Statistics – One Variable – Two Variables – More than Two Variables • Inferential Statistics • Conclusion Statistical Control • A way to test whether an observed relationship between two variables is spurious, which means: – Caused by a third variable – that separately affects the two variables we had been examining – Like in the examples we’ve seen: • Ice cream consumption, short-sleeve shirts – warm weather • Use of night light, nearsightedness in children – nearsightedness in parents Statistical Control, continued • New example from the text: – Height and preference for baseball • Taller children tend to like baseball more than shorter children • What is the third variable here? – Gender: affects both height (boys tend to be taller than girls) and preference for baseball (boys tend to like baseball more than do girls) • How does one “control” for a third variable? – Essentially, by creating categories of the third variable, and testing for the bivariate relationship within each category – In this example, create two gender categories, male and female – Ask whether: • Taller boys prefer baseball more than do shorter boys • Taller girls prefer baseball more than do shorter girls – If the answers are no, then controlling for the third variable eliminated the relationship between the first two variables • This relationship turns out to be spurious Statistical Control, continued • When we look closely at such relationships, by constructing trivariate tables, we may find more complex results requiring more complex explanations The Elaboration Model of Percentaged Tables • It is possible to create tables that include control variables • By creating separate subtables for each value of the control variables • In each subtable, we crosstabulate the independent and dependent variables • We will look at the case of one control variable • Therefore we will be looking at trivariate tables Example – based on text, tables page 352 • IV: concern for community • DV: social action • Control variable: sense of social justice “Elaboration Paradigm” • Each pattern represents a particular combination of results, looking at: – The bivariate table crosstabulating the IV and DV, with no control variables – The “partials” – each showing the crosstabulation of the IV and DV for one value of the control variable Elaboration Paradigm, continued • replication pattern – partials show the same relationship between IV and DV as does the bivariate table – Therefore, the IV-DV relationship holds, even when controlling for the third (control) variable • specification pattern – one partial replicates the initial bivariate relationship but other partials do not. – Therefore the IV-DV relationship holds, but only for one value of the control variable Elaboration Paradigm continued… • Interpretation and explanation patterns – The bivariate table shows a relationship between IV and DV – But none of the partials tables show a relationship – Conclusion: once the third variable is controlled for, the IV-DV relationship disappears – Therefore the apparent IV-DV relationship is • Spurious • The difference between interpretation and explanation is a matter of whether the control variable comes before the IV (explanation) or after the IV (interpretation) Elaboration Paradigm continued… • Suppressor pattern – bivariate table: no relationship between IV and DV – Partials all (both) show IV-DV relationship – But in opposite directions, so they cancel each other out when combined into the bivariate table – Conclusion: IV and DV are associated; control variable determines direction of relationship A note on percentage tables • Neuman’s tables – box 12.6, page 354 do not specify what type of percentaging is being shown – Cell: number of cases in cell / total number of cases • four cells together total 100% – Row: number of cases in cell divided by number in row • The two cells in each row total 100% – Column: number of cases in cell divided by number in column • The two cells in each column total 100% • A good explanation on the web • Therefore, the bivariate table for the specification pattern can exist, if the table is using ____ percentaging – Column • However, this would not match the partials shown • Therefore, this is a mistake, and the table should look like 85 15 15 85 Multiple Regression Analysis • A statistical technique for variables measured at interval or ratio levels • Results in a measure called R2 (R-squared), which measures the combined influence of multiple independent variables on one dependent variable • Regression also shows the independent effect of each variable, controlling for the other variables • The effect on the dependent variable is measured by a standardized regression coefficient: beta (ß) • Example – see box 12.7, and associated text pp. 355-356 Chapter 12: Analysis of Quantitative Data • Introduction • Dealing with Data: Coding, Entering, and Cleaning • Descriptive Statistics – One Variable – Two Variables – More than Two Variables • Inferential Statistics • Conclusion The Purpose of Inferential Statistics 1. Test hypotheses (using probability theory) 2. Determine how confident one is in making inferences from a sample to a population 3. Test whether descriptive results are likely to be due to: - real relationship, or - random factors Statistical Significance • Means that results are unlikely to be due to chance • Indicates the probability of finding a relationship in the sample when there is none in the larger population. • Cannot tell us if something is causing something else – it can only tell us what is likely. Levels of Statistical Significance • Statistical significance is usually expressed in terms of levels – usually .05, .01, or .001 • This means that results (within the sample) are likely due to chance factors – only 5%, 1%, or 1/10 % of the time, • See different ways to express this, page 357 Type I and Type II Errors • Type I Error – is claiming that a relationship exists, when it does not – In other words, falsely rejecting null hypothesis • Type II Error – Is claiming that there is no relationship in the data when there really is one – Is falsely accepting a null hypothesis • Setting a very low acceptable significance level (e.g. .001), increases the chances of type II error • Setting a very high acceptable significance level (e.g. .1), increases the chances of type I error Type I and Type II Errors continued… • The odds of making a Type I or a Type II error are inversely proportional • As the odds of making a Type I error increase, the odds of making a Type II error decrease.