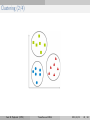
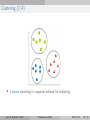
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
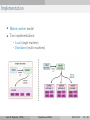
Machine Learning MLlib and Tensorflow Amir H. Payberah [email protected] KTH Royal Institute of Technology 2016/10/10 Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 1 / 56 Data Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 2 / 56 Data Amir H. Payberah (KTH) Actionable Knowledge Tensorflow and MLlib 2016/10/10 2 / 56 Data Actionable Knowledge That is roughly the problem that Machine Learning addresses! Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 2 / 56 Data and Knowledge Data I Knowledge Is this email spam or no spam? Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 3 / 56 Data and Knowledge Data I Knowledge Is this email spam or no spam? Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 3 / 56 Data and Knowledge Data Knowledge I Is this email spam or no spam? I Is there a face in this picture? Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 3 / 56 Data and Knowledge Data Knowledge I Is this email spam or no spam? I Is there a face in this picture? Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 3 / 56 Data and Knowledge Data Knowledge I Is this email spam or no spam? I Is there a face in this picture? I Should I lend money to this customer given his spending behavior? Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 3 / 56 Data and Knowledge Data Knowledge I Is this email spam or no spam? I Is there a face in this picture? I Should I lend money to this customer given his spending behaviour? Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 3 / 56 Data and Knowledge I Knowledge is not concrete I Spam is an abstraction I Face is an abstraction I Who to lend to is an abstraction You do not find spam, faces, and financial advice in datasets, you just find bits! Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 4 / 56 Knowledge Discovery from Data (KDD) I Preprocessing I Data mining I Result validation Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 5 / 56 KDD - Preprocessing I Data cleaning I Data integration I Data reduction, e.g., sampling I Data transformation, e.g., normalization Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 6 / 56 KDD - Mining Functionalities I Classification and regression (supervised learning) I Clustering (unsupervised learning) I Mining the frequent patterns I Outlier detection Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 7 / 56 KDD - Result Validation I Needs to evaluate the performance of the model on some criteria. I Depends on the application and its requirements. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 8 / 56 Data Mining Functionalities Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 9 / 56 Data Mining Functionalities I Classification and regression (supervised learning) I Clustering (unsupervised learning) I Mining the frequent patterns I Outlier detection Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 10 / 56 Classification and Regression (Supervised Learning) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 11 / 56 Supervised Learning (1/3) I Right answers are given. • Training data (input data) is labeled, e.g., spam/not-spam or a stock price at a time. I A model is prepared through a training process. I The training process continues until the model achieves a desired level of accuracy on the training data. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 12 / 56 Supervised Learning (2/3) I Face recognition Training data Testing data [ORL dataset, AT&T Laboratories, Cambridge UK] Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 13 / 56 Supervised Learning (3/3) I Set of N training examples: (x1 , y1 ), · · · , (xn , yn ). I xi = hxi1 , xi2 , · · · , xim i is the feature vector of the ith example. I yi is the ith feature vector label. I A learning algorithm seeks a function yi = f(Xi ). Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 14 / 56 Classification vs. Regression I Classification: the output variable takes class labels. I Regression: the output variable takes continuous values. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 15 / 56 Classification/Regression Models I Linear models I Decision trees I Naive Bayes models Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 16 / 56 Linear Models (1/2) I Training dataset: (x1 , y1 ), · · · , (xn , yn ). I xi = hxi1 , xi2 , · · · , xim i I Model the target as a function of a linear predictor applied to the input variables: yi = g(wT xi ). • E.g., yi = w1 xi1 + w2 xi2 + · · · + wm xim Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 17 / 56 Linear Models (1/2) I Training dataset: (x1 , y1 ), · · · , (xn , yn ). I xi = hxi1 , xi2 , · · · , xim i I Model the target as a function of a linear predictor applied to the input variables: yi = g(wT xi ). • E.g., yi = w1 xi1 + w2 xi2 + · · · + wm xim Pn I Loss function: f (w) := i=1 L(g (w I An optimization problem minm f(w) T x ), y ) i i w∈R Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 17 / 56 Linear Models (2/2) I g(wT xi ) = w1 xi1 + w2 xi2 + · · · + wm xim I Loss function: minimizing squared different between predicted value and actual value: L(g (wT xi ), yi ) := 21 (wT xi − yi )2 Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 18 / 56 Linear Models (2/2) I g(wT xi ) = w1 xi1 + w2 xi2 + · · · + wm xim I Loss function: minimizing squared different between predicted value and actual value: L(g (wT xi ), yi ) := 21 (wT xi − yi )2 I Gradient descent Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 18 / 56 Decision Tree (1/2) I A greedy algorithm. I It performs a recursive binary partitioning of the feature space. I Decision tree construction algorithm: • • Find the best split condition (quantified based on the impurity measure). Stops when no improvement possible. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 19 / 56 Decision Tree (2/2) I Random forest I Train a set of decision trees separately. I The training can be done in parallel. I The algorithm injects randomness into the training process, so that each decision tree is a bit different. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 20 / 56 Naive Bayes (1/3) I Using the probability theory to classify things. I Find p(y|x). Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 21 / 56 Naive Bayes (1/3) I Using the probability theory to classify things. I Find p(y|x). I Replace p(y|x) with Amir H. Payberah (KTH) p(x|y)p(y) p(x) Tensorflow and MLlib 2016/10/10 21 / 56 Naive Bayes (2/3) p(x|y)p(y) p(x) I Bayes theorem: p(y|x) = I p(y|x): probability of instance x being in class y. I p(x|y): probability of generating instance x given class y. I p(y): probability of occurrence of class y I p(x): probability of instance x occurring. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 22 / 56 Naive Bayes (3/3) Is officer Drew male or female? Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 23 / 56 Naive Bayes (3/3) p(x|y)p(y) p(x) I p(y|x) = I p(male|drew) = ? I p(female|drew) = ? Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 23 / 56 Naive Bayes (3/3) p(x|y)p(y) p(x) I p(y|x) = I p(male|drew) = I p(female|drew) = Amir H. Payberah (KTH) p(drew|male)p(male) p(drew) = 1 × 83 3 3 8 p(drew|female)p(female) p(drew) Tensorflow and MLlib = 0.33 = 2 × 58 5 3 8 = 0.66 2016/10/10 23 / 56 Naive Bayes (3/3) Officer Drew is female. p(x|y)p(y) p(x) I p(y|x) = I p(male|drew) = I p(female|drew) = Amir H. Payberah (KTH) p(drew|male)p(male) p(drew) = 1 × 83 3 3 8 p(drew|female)p(female) p(drew) Tensorflow and MLlib = 0.33 = 2 × 58 5 3 8 = 0.66 2016/10/10 23 / 56 Clustering (Unsupervised Learning) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 24 / 56 Clustering (1/4) I Clustering is a technique for finding similarity groups in data, called clusters. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 25 / 56 Clustering (1/4) I Clustering is a technique for finding similarity groups in data, called clusters. I It groups data instances that are similar to each other in one cluster, and data instances that are very different from each other into different clusters. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 25 / 56 Clustering (1/4) I Clustering is a technique for finding similarity groups in data, called clusters. I It groups data instances that are similar to each other in one cluster, and data instances that are very different from each other into different clusters. I Clustering is often called an unsupervised learning task as no class values denoting an a priori grouping of the data instances are given. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 25 / 56 Clustering (2/4) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 26 / 56 Clustering (2/4) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 26 / 56 Clustering (2/4) I k-means clustering is a popular method for clustering. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 26 / 56 Clustering (3/4) I K: number of clusters (given) • One mean per cluster. I Initialize means: by picking k samples at random. I Iterate: • • Assign each point to nearest mean. Move mean to center of its cluster. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 27 / 56 Clustering (4/4) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 28 / 56 Clustering (4/4) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 28 / 56 Clustering (4/4) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 28 / 56 Clustering (4/4) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 28 / 56 MLlib Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 29 / 56 MLlib Data Types - Local Vector I Stored on a single machine I Dense and sparse • • Dense (1.0, 0.0, 3.0): [1.0, 0.0, 3.0] Sparse (1.0, 0.0, 3.0): (3, [0, 2], [1.0, 3.0]) val dv: Vector = Vectors.dense(1.0, 0.0, 3.0) val sv1: Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)) val sv2: Vector = Vectors.sparse(3, Seq((0, 1.0), (2, 3.0))) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 30 / 56 Data Types - Labeled Point I A local vector (dense or sparse) associated with a label. I label: label for this data point. I features: list of features for this data point. case class LabeledPoint(label: Double, features: Vector) val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0)) val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 31 / 56 Supervised Learning in Spark I Linear models I Decision trees I Naive Bayes models Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 32 / 56 Linear Models - Regression val data: RDD[LabeledPoint] = ... val splits = labelData.randomSplit(Array(0.7, 0.3)) val (trainigData, testData) = (splits(0), splits(1)) val numIterations = 100 val stepSize = 0.00000001 val model = LinearRegressionWithSGD .train(trainigData, numIterations, stepSize) val valuesAndPreds = testData.map { point => val prediction = model.predict(point.features) (point.label, prediction) } Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 33 / 56 Linear Models - Classification (Logistic Regression) val data: RDD[LabeledPoint] = ... val splits = labelData.randomSplit(Array(0.7, 0.3)) val (trainigData, testData) = (splits(0), splits(1)) val model = new LogisticRegressionWithLBFGS() .setNumClasses(10) .run(trainingData) val predictionAndLabels = testData.map { point => val prediction = model.predict(point.features) (prediction, point.label) } Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 34 / 56 Decision Tree - Regression val data: RDD[LabeledPoint] = ... val splits = data.randomSplit(Array(0.7, 0.3)) val (trainingData, testData) = (splits(0), splits(1)) val val val val categoricalFeaturesInfo = Map[Int, Int]() impurity = "variance" maxDepth = 5 maxBins = 32 val model = DecisionTree.trainRegressor(trainingData, categoricalFeaturesInfo, impurity, maxDepth, maxBins) val labelsAndPredictions = testData.map { point => val prediction = model.predict(point.features) (point.label, prediction) } Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 35 / 56 Decision Tree - Classification val data: RDD[LabeledPoint] = ... val splits = data.randomSplit(Array(0.7, 0.3)) val (trainingData, testData) = (splits(0), splits(1)) val val val val val numClasses = 2 categoricalFeaturesInfo = Map[Int, Int]() impurity = "gini" maxDepth = 5 maxBins = 32 val model = DecisionTree.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo, impurity, maxDepth, maxBins) val labelAndPreds = testData.map { point => val prediction = model.predict(point.features) (point.label, prediction) } Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 36 / 56 Random Forest - Regression val val val val val val val numClasses = 2 categoricalFeaturesInfo = Map[Int, Int]() numTrees = 3 featureSubsetStrategy = "auto" impurity = "variance" maxDepth = 4 maxBins = 32 val model = RandomForest.trainRegressor(trainingData, categoricalFeaturesInfo, numTrees, featureSubsetStrategy, impurity, maxDepth, maxBins) val labelsAndPredictions = testData.map { point => val prediction = model.predict(point.features) (point.label, prediction) } Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 37 / 56 Random Forest - Classification val val val val val val val numClasses = 2 categoricalFeaturesInfo = Map[Int, Int]() numTrees = 3 featureSubsetStrategy = "auto" impurity = "gini" maxDepth = 4 maxBins = 32 val model = RandomForest.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo, numTrees, featureSubsetStrategy, impurity, maxDepth, maxBins) val labelAndPreds = testData.map { point => val prediction = model.predict(point.features) (point.label, prediction) } Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 38 / 56 Naive Bayes val data: RDD[LabeledPoint] = ... val splits = data.randomSplit(Array(0.7, 0.3)) val (trainingData, testData) = (splits(0), splits(1)) val model = NaiveBayes.train(trainingData, lambda = 1.0, modelType = "multinomial") val predictionAndLabel = test.map(p => (model.predict(p.features), p.label)) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 39 / 56 Unsupervised Learning in Spark I Kmeans clustering Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 40 / 56 KMeans Clustering val data: RDD[LabeledPoint] = ... val numClusters = 2 val numIterations = 20 val clusters = KMeans.train(data, numClusters, numIterations) // Evaluate clustering by computing Within Set Sum of Squared Errors val WSSSE = clusters.computeCost(data) println("Within Set Sum of Squared Errors = " + WSSSE) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 41 / 56 Tensorflow Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 42 / 56 Tensorflow I TensorFlow • • An interface for expressing machine learning algorithms An implementation for executing such algorithms I Tensor: the data structure used. I Flow: the computational model. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 43 / 56 Programming Model - Dataflow I A computation is described by a directed graph composed of a set of nodes. I Tensors (values) flow along normal edges in the graph. I Control dependencies are special edges with no data flows. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 44 / 56 Programming Model - Operations and Kernels I Operation: a node in the dataflow graph that represents an abstract computation. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 45 / 56 Programming Model - Operations and Kernels I Operation: a node in the dataflow graph that represents an abstract computation. I Operations can have attributes: they must be provided or inferred at graph-construction time. • To make operations polymorphic over different tensor element types, e.g., add of two tensors of type float or int32. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 45 / 56 Programming Model - Operations and Kernels I Operation: a node in the dataflow graph that represents an abstract computation. I Operations can have attributes: they must be provided or inferred at graph-construction time. • I To make operations polymorphic over different tensor element types, e.g., add of two tensors of type float or int32. Kernel: a particular implementation of an operation. • Can be run on a particular type of device, e.g., CPU or GPU. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 45 / 56 Programming Model - Tensors (1/4) I Tensor: the data structure used. I Dense numerical arrays of the same datatype. I Specified by: • • • Rank Shape Type Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 46 / 56 Programming Model - Tensors (2/4) I Rank: the level of nesting Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 47 / 56 Programming Model - Tensors (3/4) I Shape: the number of elements for each dimension. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 48 / 56 Programming Model - Tensors (4/4) I Type: the datatype of the numbers stored in the tensor. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 49 / 56 Programming Model - Variables I Most tensors do not survive past a single execution of the graph. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 50 / 56 Programming Model - Variables I Most tensors do not survive past a single execution of the graph. I Variable: a special kind of operation that returns a handle to a persistent mutable tensor that survives across executions of a graph. I Handles to these persistent mutable tensors can be passed to a handful of special operations, e.g., AssignAdd (equivalent to +=) that mutate the referenced tensor. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 50 / 56 Programming Model - Sessions I Session: clients programs interact with the TensorFlow system by creating a Session. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 51 / 56 Programming Model - Sessions I Session: clients programs interact with the TensorFlow system by creating a Session. I Extend method: to augment the current graph managed by the session with additional nodes and edges. I Run method: to compute the transitive closure of all nodes that must be executed to compute the outputs. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 51 / 56 Programming Model - Sessions I Session: clients programs interact with the TensorFlow system by creating a Session. I Extend method: to augment the current graph managed by the session with additional nodes and edges. I Run method: to compute the transitive closure of all nodes that must be executed to compute the outputs. I Usually a Session is set up once, and then execute the full graph or a few distinct subgraphs thousands or millions of times via Run calls. Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 51 / 56 Example - Logistic Regression I ŷ = 1 1+e −(β0 +β.x) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 52 / 56 Example - Logistic Regression I ŷ = 1 1+e −(β0 +β.x) import tensorflow as tf x = tf.placeholder(tf.float32, [1]) # add a placeholder node for the input x beta0 = tf.Variable(tf.zeros(1)) # the bias beta = tf.Variable(tf.ones(1)) # the coefficient for x log_odds = beta0 + x * beta # perform the linear regression step y_hat = 1 / (1 + tf.exp(-log_adds)) # apply the logistic function initializer = tf.initialize_all_variables() with tf.Session() as sess: sess.run(initializer) pred = sess.run(y_hat, feed_dict={x:[1]}) # evaluate the y_hat node print(pred) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 52 / 56 Implementation I Master-worker model I Two implementations: • • Local (single machine) Distributed (multi machines) Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 53 / 56 Summary Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 54 / 56 Summary I Data mining: classification, clustering, frequent patterns, anomaly I MLlib and Tensorflow Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 55 / 56 Questions? Amir H. Payberah (KTH) Tensorflow and MLlib 2016/10/10 56 / 56