Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
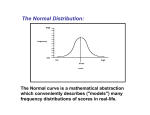
The Standard Normal Distribution Now we consider a special normal distribution N(0,1), called the "standard normal distribution," with a mean of 0 and a standard deviation of 1. This will be considered the "standard" and values from other normal distributions can be standardized by the following formula: This standardized value is often called a z-score (pronounced “zee-score” but also pronounced “zet-score”). There are many reasons to standardize, the most frequent, of which, is to eliminate the effect of scale. In other words, sometimes we are interested in how far an observation falls from a mean in sterms of standard deviations that are not integers. We can compare standardized scores readily, even when they come from different normal distributions. If a variable has a normal distribution with a mean and standard deviation, then the standardized variable has a standard normal distribution. Let me go through a couple of examples to show you how a z-score can be used to determine relative standing (i.e., percentiles) First, let’s look at a basic problem. Suppose that the SAT Math scores for all students in the United States that same year was 486 with a standard deviation of 22. What percent of the scores were less than 508? Recall that in a normal distribution, the 68-95-99.7 (or Empirical) rule tells us approximately what percentage of the observations lie within one, two or three standard deviations from the mean. If the mean is 486, then a score of 508 will be one standard deviation (or 34%) above the mean. Since the mean marks the 50th percentile, it can be seen that 84% of the observations were a score of 508 or lower. If you didn’t see where 84% came from, just add 50% (the area under the curve from 486 and left) and 34% (the area under the curve between 486 and 508). What if the question was asking for something a little different? What percentage of the scores are less than 516? Notice that 516 lies between 508 and 530 so it is between one and two standard deviations above the mean. But can we be more precise? The answer is yes, if we use z-scores. Look at the beginning of this document and look at the formula for z-scores. If I substitute numbers in for the symbols I can get a z-score and from there I can find the percent of observations that lie around that score. Look at the math I provide below: z x 516 486 30 1.36 22 22 (always round z-scores to two decimal places) So, this means that on the x-axis of the normal distribution a score of 516 lies approximately 1.36 standard deviations above the mean of 486 But how does this translate to percentiles. In a normal curve, percentages are found by measuring the area under the normal curve between two numbers. In this case, we are interested in the percentage of observations that lie below 516 so we are looking at the percentage of observations between the lowest observation and 516. In the case of the SAT, the lowest observation attainable (I think) is 200 so we are looking at the percent of observations between 200 and 516. The picture below gives an illustration. The blue shaded area is what we are interested in So, to find this area all we need to do is find the z-score in Table A located on the first page of your textbook and then cross reference it with the percentage provided. To do this, look at the first column in the table. That is the z-score column. The table covers both sides of the page and our z-score is positive, so if you haven’t discovered this yet you need to be on the back side of the page! Our z-score is 1.36. So, we go down the column to find the “1.3”. Once we are there we move right seven columns to place ourselves in the “.06” column. Now we are located at 1.36 standard deviations. There is a number in this location. It is 0.9131. This means that 91.31% of the area under the curve is between the lowest score and our z-score of 1.36. What if we changed the question to ask “what percentage of the scores are greater than 5.16”? Our process is the same as far as finding z-scores and a location in Table A. But now we are interested in percentage of scores between 516 and the top score. See the curve below for a picture You learned in the first part of this module that the total area under a density curve is 1. So, the percent of scores greater than 516 is 1-0.9131 = 0.0869. So, approximately 8.69% of the scores are greater than 516. One more question. What percent of the scores are between 476 and 516? Look at the picture below for an illustration We already know that the area between the lowest score and 516 is 0.9131. We can also find the area between the lowest score and 476 by: z x 476 486 10 0.45 22 22 (remember to round to two decimal places) This time go to the front page of Table A and find the z-score of – 0.45 and the number that is in that location (like we did in the example above). You should get 0.3264. To get the answer to our question, subtract out the two. So, the percentage of scores between 476 and 516 is 0.9131 – 0.3264 = 0.5867 or about 58.67%