Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Borrowed from UMD ENEE631
Spring’04
Unitary Transforms
UMCP ENEE631 Slides (created by M.Wu © 2004)
Image Transform: A Revisit
With A Coding Perspective
UMCP ENEE631 Slides (created by M.Wu © 2001)
Why Do Transforms?
Fast computation
– E.g., convolution vs. multiplication for filter with wide support
Conceptual insights for various image processing
– E.g., spatial frequency info. (smooth, moderate change, fast change, etc.)
Obtain transformed data as measurement
– E.g., blurred images, radiology images (medical and astrophysics)
– Often need inverse transform
– May need to get assistance from other transforms
For efficient storage and transmission
– Pick a few “representatives” (basis)
– Just store/send the “contribution” from each basis
UMCP ENEE631 Slides (created by M.Wu © 2004)
Basic Process of Transform Coding
Figure is from slides at Gonzalez/ Woods DIP book website (Chapter 8)
UMCP ENEE631 Slides (created by M.Wu © 2001/2004)
1-D DFT and Vector Form
{ z(n) } { Z(k) }
n, k = 0, 1, …, N-1
WN = exp{ - j2 / N }
1 N 1
nk
Z
(
k
)
z
(
n
)
W
N
N n 0
N 1
1
nk
z ( n)
Z
(
k
)
W
N
N k 0
~ complex conjugate of primitive Nth root of unity
Vector form and interpretation for inverse transform
z = k Z(k) ak
ak = [ 1 WN-k WN-2k … WN-(N-1)k ]T / N
Basis vectors
– akH = ak* T = [ 1 WNk WN2k … WN(N-1)k ] / N
– Use akH as row vectors to construct a matrix F
– Z = F z z = F*T Z = F* Z
– F is symmetric (FT=F) and unitary (F-1 = FH where FH = F*T )
A vector space consists of a set of vectors, a
field of scalars, a vector addition operation,
and a scalar multiplication operation.
UMCP ENEE631 Slides (created by M.Wu © 2001)
Basis Vectors and Basis Images
A basis for a vector space ~ a set of vectors
– Linearly independent ~ ai vi = 0 if and only if all ai=0
– Uniquely represent every vector in the space by their linear combination
~ bi vi ( “spanning set” {vi} )
Orthonormal basis
– Orthogonality ~ inner product <x, y> = y*T x= 0
– Normalized length ~ || x ||2 = <x, x> = x*T x= 1
Inner product for 2-D arrays
– <F, G> = m n f(m,n) g*(m,n) = G1*T F1 (rewrite matrix into vector)
!! Don’t do FG ~ may not even be a valid operation for MxN matrices!
2D Basis Matrices (Basis Images)
– Represent any images of the same size as a linear combination of basis
images
UMCP ENEE631 Slides (created by M.Wu © 2001)
1-D Unitary Transform
Linear invertible transform
– 1-D sequence { x(0), x(1), …, x(N-1) } as a vector
– y = A x and A is invertible
Unitary matrix ~ A-1 = A*T
– Denote A*T as AH ~ “Hermitian”
– x = A-1 y = A*T y = ai*T y(i)
– Hermitian of row vectors of A form a set of orthonormal basis vectors
ai*T = [a*(i,0), …, a*(i,N-1)] T
Orthogonal matrix ~ A-1 = AT
– Real-valued unitary matrix is also an orthogonal matrix
– Row vectors of real orthogonal matrix A form orthonormal basis vectors
UMCP ENEE631 Slides (created by M.Wu © 2001/2004)
Properties of 1-D Unitary Transform y = A x
Energy Conservation
– || y ||2 = || x ||2
|| y ||2 = || Ax ||2= (Ax)*T (Ax)= x*T A*T A x = x*T x = || x ||2
Rotation
– The angles between vectors are preserved
– A unitary transformation is a rotation of a vector in an
N-dimension space, i.e., a rotation of basis coordinates
UMCP ENEE631 Slides (created by M.Wu © 2001/2004)
Properties of 1-D Unitary Transform
(cont’d)
Energy Compaction
– Many common unitary transforms tend to pack a large fraction of signal
energy into just a few transform coefficients
Decorrelation
– Highly correlated input elements quite uncorrelated output coefficients
– Covariance matrix E[ ( y – E(y) ) ( y – E(y) )*T ]
small correlation implies small off-diagonal terms
Example: recall the effect of DFT
Question: What unitary transform gives the best compaction and decorrelation?
=> Will revisit this issue in a few lectures
UMCP ENEE631 Slides (created by M.Wu © 2001/2004)
Review: 1-D Discrete Cosine Transform
(DCT)
N 1
( 2n 1) k
Z
(
k
)
z
(
n
)
(
k
)
cos
2N
n 0
N 1
( 2n 1) k
z ( n)
Z ( k ) ( k ) cos
2N
k 0
(0)
1
, (k )
N
2
N
Transform matrix C
– c(k,n) = (0) for k=0
– c(k,n) = (k) cos[(2n+1)/2N] for k>0
C is real and orthogonal
– rows of C form orthonormal basis
– C is not symmetric!
– DCT is not the real part of unitary DFT!
See Assignment#3
related to DFT of a symmetrically extended signal
UMCP ENEE631 Slides (created by M.Wu © 2004)
Periodicity Implied by DFT and DCT
Figure is from slides at Gonzalez/ Woods DIP book website (Chapter 8)
From Ken Lam’s DCT talk 2001 (HK Polytech)
UMCP ENEE631 Slides (created by M.Wu © 2001)
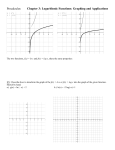
Example of 1-D DCT
100
100
50
50
z(n)
Z(k)
0
0
DCT
-50
-50
-100
-100
0
1
2 3
4
n
5 6
7
0
1
2 3
4
k
5 6
7
From Ken Lam’s DCT talk 2001 (HK Polytech)
UMCP ENEE631 Slides (created by M.Wu © 2001)
Example of 1-D DCT (cont’d)
1.0
1.0
100
100
0.0
0.0
0
0
-1.0
-1.0
-100
1.0
1.0
100
100
0.0
0.0
0
0
-1.0
-1.0
-100
u=0 to 1 -100
1.0
1.0
100
100
0.0
0.0
0
0
-1.0
-1.0
-100
u=0 to 2 -100
1.0
1.0
100
100
0.0
0.0
0
0
-1.0
-1.0
-100
u=0 to 3 -100
z(n)
n
Original signal
u=0
-100
u=0 to 4
u=0 to 5
u=0 to 6
Z(k)
k
Transform coeff.
Basis vectors
Reconstructions
u=0 to 7
2-D DCT
UMCP ENEE631 Slides (created by M.Wu © 2001)
Separable orthogonal transform
– Apply 1-D DCT to each row, then to each column
Y = C X CT X = CT Y C = mn y(m,n) Bm,n
DCT basis images:
– Equivalent to represent
an NxN image with a set
of orthonormal NxN
“basis images”
– Each DCT coefficient
indicates the contribution
from (or similarity to) the
corresponding basis image
UMCP ENEE631 Slides (created by M.Wu © 2001/2004)
2-D Transform: General Case
N 1 N 1
y ( k , l ) x( m, n) ak ,l (m, n)
m 0 n 0
N 1 N 1
x( m, n)
y ( k , l ) hk ,l (m, n)
k 0 l 0
A general 2-D linear transform {ak,l(m,n)}
– y(k,l) is a transform coefficient for Image {x(m,n)}
– {y(k,l)} is “Transformed Image”
– Equiv to rewriting all from 2-D to 1-D and applying 1-D transform
Computational complexity
– N2 values to compute
– N2 terms in summation per output coefficient
– O(N4) for transforming an NxN image!
UMCP ENEE631 Slides (created by M.Wu © 2001)
2-D Separable Unitary Transforms
Restrict to separable transform
– ak,l(m,n) = ak(m) bl(n) , denote this as a(k,m) b(l,n)
Use 1-D unitary transform as building block
– {ak(m)}k and {bl(n)}l are 1-D complete orthonormal sets of basis vectors
use as row vectors to obtain unitary matrices A={a(k,m)} & B={b(l,n)}
– Apply to columns and rows Y = A X BT
often choose same unitary matrix as A and B (e.g., 2-D DFT)
For square NxN image A: Y = A X AT X = AH Y A*
– For rectangular MxN image A: Y = AM X AN T X = AMH Y AN*
Complexity ~ O(N3)
– May further reduce complexity if unitary transf. has fast implementation
Basis Images
UMCP ENEE631 Slides (created by M.Wu © 2001)
X = AH Y A* => x(m,n) = k l a*(k,m)a*(l,n) y(k,l)
– Represent X with NxN basis images weighted by coeff. Y
– Obtain basis image by setting Y={(k-k0, l-l0)} & getting X
{ a*(k0 ,m)a*(l0 ,n) }m,n
*T ~ a* is kth column vector of
in matrix form A*k,l = a*k al
k
AH
trasnf. coeff. y(k,l) is the inner product of A*k,l with
the image
1
1
1 2
2
A
1
2
2
1
2
X
3
4
(Jain’s e.g.5.1, pp137)
UMCP ENEE631 Slides (created by M.Wu © 2001)
Common Unitary Transforms and Basis
Images
DFT
DCT
Haar transform
K-L transform
See also: Jain’s Fig.5.2 pp136
UMCP ENEE631 Slides (created by M.Wu © 2001/2004)
2-D DFT
2-D DFT is Separable
– Y = F X F X = F* Y F*
– Basis images Bk,l = (ak ) (al )T
where ak = [ 1 WN-k WN-2k … WN-(N-1)k ]T / N
1 N 1 N 1
nl
mk
Y
(
k
,
l
)
X
(
m
,
n
)
W
W
N
N
N m 0 n 0
N 1 N 1
1
nl
mk
X (m, n)
Y
(
k
,
l
)
W
W
N
N
N
k 0 l 0
Summary and Review (1)
UMCP ENEE631 Slides (created by M.Wu © 2001)
1-D transform of a vector
– Represent an N-sample sequence as a vector in N-dimension vector space
– Transform
Different representation of this vector in the space via different basis
e.g., 1-D DFT from time domain to frequency domain
– Forward transform
In the form of inner product
Project a vector onto a new set of basis to obtain N “coefficients”
– Inverse transform
Use linear combination of basis vectors weighted by transform coeff.
to represent the original signal
2-D transform of a matrix
– Rewrite the matrix into a vector and apply 1-D transform
– Separable transform allows applying transform to rows then columns
UMCP ENEE631 Slides (created by M.Wu © 2001)
Summary and Review (1) cont’d
Vector/matrix representation of 1-D & 2-D sampled signal
– Representing an image as a matrix or sometimes as a long vector
Basis functions/vectors and orthonomal basis
– Used for representing the space via their linear combinations
– Many possible sets of basis and orthonomal basis
Unitary transform on input x ~ A-1 = A*T
– y = A x x = A-1 y = A*T y = ai*T y(i) ~ represented by basis vectors {ai*T}
– Rows (and columns) of a unitary matrix form an orthonormal basis
General 2-D transform and separable unitary 2-D transform
– 2-D transform involves O(N4) computation
– Separable: Y = A X AT = (A X) AT ~ O(N3) computation
Apply 1-D transform to all columns, then apply 1-D transform to rows
UMCP ENEE631 Slides (created by M.Wu © 2004)
Optimal Transform
Optimal Transform
UMCP ENEE631 Slides (created by M.Wu © 2004)
Recall: Why use transform in coding/compression?
– Decorrelate the correlated data
– Pack energy into a small number of coefficients
– Interested in unitary/orthogonal or approximate orthogonal transforms
Energy preservation s.t. quantization effects can be better understood
and controlled
Unitary transforms we’ve dealt so far are data independent
– Transform basis/filters are not depending on the signals we are processing
What unitary transform gives the best energy compaction and decorrelation?
– “Optimal” in a statistical sense to allow the codec works well with
many images
Signal statistics would play an important role
Review: Correlation After a Linear
Transform
UMCP ENEE631 Slides (created by M.Wu © 2004)
Consider an Nx1 zero-mean random vector x
– Covariance (autocorrelation) matrix Rx = E[ x xH ]
give ideas of correlation between elements
Rx is a diagonal matrix for if all N r.v.’s are uncorrelated
Apply a linear transform to x: y = A x
What is the correlation matrix for y ?
Ry = E[ y yH ] = E[ (Ax) (Ax)H ] = E[ A x xH AH ]
= A E[ x xH ] AH = A Rx AH
Decorrelation: try to search for A that can produce a decorrelated y (equiv. a
diagonal correlation matrix Ry )
K-L Transform (Principal Component
Analysis)
UMCP ENEE631 Slides (created by M.Wu © 2001/2004)
Eigen decomposition of Rx: Rx uk = k uk
– Recall the properties of Rx
Hermitian (conjugate symmetric RH = R);
Nonnegative definite (real non-negative eigen values)
Karhunen-Loeve Transform (KLT)
y = UH x x = U y with U = [ u1, … uN ]
– KLT is a unitary transform with basis vectors in U being the
orthonormalized eigenvectors of Rx
– UH Rx U = diag{1, 2, … , N} i.e. KLT performs decorrelation
– Often order {ui} so that 1 2 … N
– Also known as the Hotelling transform or
the Principle Component Analysis (PCA)
UMCP ENEE631 Slides (created by M.Wu © 2001/2004)
Properties of K-L Transform
Decorrelation
– E[ y yH ]= E[ (UH x) (UH x)H ]= UH E[ x xH ] U = diag{1, 2, … , N}
– Note: Other matrices (unitary or nonunitary) may also decorrelate
the transformed sequence [Jain’s e.g.5.7 pp166]
Minimizing MSE under basis restriction
– If only allow to keep m coefficients for any 1 m N, what’s the
best way to minimize reconstruction error?
Keep the coefficients w.r.t. the eigenvectors of the first m largest
eigenvalues
Theorem 5.1 and Proof in Jain’s Book (pp166)
KLT Basis Restriction
UMCP ENEE631 Slides (created by M.Wu © 2004)
Basis restriction
– Keep only a subset of m transform coefficients and then perform
inverse transform (1 m N)
– Basis restriction error: MSE between original & new sequences
Goal: to find the forward and backward transform matrices to minimize the
restriction error for each and every m
– The minimum is achieved by KLT arranged according to the
decreasing order of the eigenvalues of R
K-L Transform for Images
UMCP ENEE631 Slides (created by M.Wu © 2001)
Work with 2-D autocorrelation function
– R(m,n; m’,n’)= E[ x(m, n) x(m’, n’) ] for all 0 m, m’, n, n’ N-1
– K-L Basis images is the orthonormalized eigenfunctions of R
Rewrite images into vector form (N2x1)
– Need solve the eigen problem for N2xN2 matrix! ~ O(N 6)
Reduced computation for separable R
– R(m,n; m’,n’)= r1(m,m’) r2(n,n’)
– Only need solve the eigen problem for two NxN matrices ~ O(N3)
– KLT can now be performed separably on rows and columns
Reducing the transform complexity from O(N4) to O(N3)
UMCP ENEE631 Slides (created by M.Wu © 2001)
Pros and Cons of K-L Transform
Optimality
– Decorrelation and MMSE for the same# of partial coeff.
Data dependent
– Have to estimate the 2nd-order statistics to determine the transform
– Can we get data-independent transform with similar performance?
DCT
Applications
– (non-universal) compression
– pattern recognition: e.g., eigen faces
– analyze the principal (“dominating”) components
UMCP ENEE631 Slides (created by M.Wu © 2004)
Energy Compaction of DCT vs. KLT
DCT has excellent energy compaction for highly
correlated data
DCT is a good replacement for K-L
– Close to optimal for highly correlated data
– Not depend on specific data like K-L does
– Fast algorithm available
[ref and statistics: Jain’s pp153, 168-175]
Energy Compaction of DCT vs. KLT (cont’d)
UMCP ENEE631 Slides (created by M.Wu © 2004)
Preliminaries
– The matrices R, R-1, and R-1 share the same eigen vectors
– DCT basis vectors are eigenvectors of a symmetric tri-diagonal matrix Qc
– Covariance matrix R of 1st-order stationary Markov sequence with has an
inverse in the form of symmetric tri-diagonal matrix
DCT is close to KLT on 1st-order stationary Markov
– For highly correlated sequence, a scaled version of R-1 approx. Qc
Summary and Review on Unitary Transform
UMCP ENEE631 Slides (created by M.Wu © 2001)
Representation with orthonormal basis Unitary transform
– Preserve energy
Common unitary transforms
– DFT, DCT, Haar, KLT
Which transform to choose?
– Depend on need in particular task/application
– DFT ~ reflect physical meaning of frequency or spatial
frequency
– KLT ~ optimal in energy compaction
– DCT ~ real-to-real, and close to KLT’s energy compaction