Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
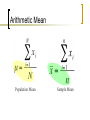
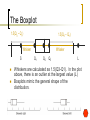
Numerical Descriptive Techniques Statistics for Management and Economics Chapter 4 Objectives Measures of Central Location Measures of Variability Measures of Relative Standing and Box Plots Measures of Linear Relationship Graphical vs. Numerical Techniques Data Exploration Measures of Central Location Numerical measure of the center, or middle, of the data Arithmetic Mean Median Mode Geometric Mean Measure of Center: Arithmetic Mean The arithmetic mean, a.k.a. average, shortened to mean, is the most popular & useful measure of central location. Appropriate for describing interval data. The arithmetic mean for a population is denoted with Greek letter “mu”: The arithmetic mean for a sample is denoted with an “x-bar”: It is computed by simply adding up all the observations and dividing by the total number of observations: Sum of the observations Mean = Number of observations Arithmetic Mean Population Mean Sample Mean Measure of Center: Median The median is another useful measure of central location. Appropriate for describing interval or ordinal data. Best measure of central location when dealing with data that has extreme values. Computed the same for population and sample. Calculated by placing all the observations in order; the observation that falls in the middle is the median. HINT! The middle of the dataset falls at the location (n+1)/2 Measures of Center: Mode The mode of a set of observations is the value that occurs most frequently. A set of data may have one mode (or modal class), or two, or more modes. Mode is a useful measure of center for all data types, though mainly used to identify the group with the highest frequency for nominal data. For large data sets the modal class is much more relevant than a single-value mode. Computed the same for population and sample. Mean vs. Median vs. Mode Mean and median for a symmetric distribution Mean Median Mode Left skew or Negative skew Mean Median Mode Mean and median for skewed distributions Mean Median Mode Right skew or Positive skew Mean vs. Median vs. Mode Symmetric distribution: the mean, median, and mode will be approximately the same. Multimodal distribution: report the mean, median and/or mode for each subgroup. Nominal data: Mode calculation is useful for determining highest frequency but not “central location”; the calculation of the mean is not valid. Ordinal data: Median is appropriate; the calculation of the mean is not valid. Interval data: Mean is appropriate; in the case of skewed data, report the median as well. Measures of Center: Geometric Mean The geometric mean is used when the variable is a growth rate or rate of change, such as the value of an investment over periods of time. If Ri denotes the rate of return in period i (i = 1, 2, …, n), then The geometric mean Rg of the returns R1, R2, … Rn is defined such that: Measures of Center: Geometric Mean Solving for Rg we produce the following formula: The upper case Greek Letter “Pi” represents a product of terms… Measures of Center: Summary Use the… Mean To describe… The central location of a single set of interval data Median Mode the central location of a single set of interval or ordinal data a single set of nominal data Geometric Mean a single set of interval data based on growth rates Measures of Variability Tell how variable, or spread out, the data falls around the mean Used in conjunction with measures of center to describe a distribution with numbers Used primarily for interval data Three measures: Range Variance Standard Deviation Measures of Variability: Range Simplest measure of variability, easily computed Calculated as: largest observation – smallest observation Not very descriptive of the variability of the data – how? Measures of Variability: Variance Widely used Used to summarize data but also plays an important role in statistical inference In general, explains how data is spread about the mean. For the population, denoted by the lower case Greek letter sigma (squared): 2 For the sample, s2 Measures of Variability: Variance population mean The variance of a population is: population size sample mean The variance of a sample is: Note! the denominator is sample size (n) minus one ! Shortcut: Calculating Variance A short-cut formulation to calculate sample variance directly from the data without the intermediate step of calculating the mean… Measures of Variability: Standard Deviation Square root of the variance Population: Sample: Interpretation: Standard Deviation Together with the sample mean, the standard deviation can be used to “build” the picture of a distribution. It can also be used to compare the variability of different distributions. To do this, we can use… The Empirical Rule Chebysheff’s Theorem Interpretation: The Empirical Rule For distributions with bell shaped histograms. States that… 1) 2) 3) Approximately 68% of all observations fall within one standard deviation of the mean. Approximately 95% of all observations fall within two standard deviations of the mean. Approximately 99.7% of all observations fall within three standard deviations of the mean. A.K.A. The 68% - 95% - 99.7% Rule Interpretation: Chebysheff’s Theorem Applies to all shapes of histograms (not limited to bell shaped) The proportion of observations in any sample that lie within k standard deviations of the mean is at least: Note: The Empirical Rule provides approximate proportions given the limits where Chebysheff provides the lower bound on the proportions. Measures of Variability: Coefficient of Variation The coefficient of variation of a set of observations is the standard deviation of the observations divided by their mean, that is: Population coefficient of variation = CV = Sample coefficient of variation = cv = This coefficient provides a proportionate measure of variation (thus is useful for comparing variation among two datasets). For example, a standard deviation of 10 may be perceived as large when the mean value is 100, but only moderately large when the mean value is 500. Measures of Relative Standing Measures of relative standing are designed to provide information about the position of particular values relative to the entire data set. Percentile: the Pth percentile is the value for which P percent are less than that value and (100-P)% are greater than that value. Specifically, the 25%, 50%, and 75% percentiles are Quartiles. You may also see fifths – Quintiles or tenths – Deciles. Percentiles and Quartiles… First (lower) decile = 10th percentile First (lower) quartile, Q1 = 25th percentile Second (middle) quartile,Q2 = 50th percentile Third quartile, Q3 = 75th percentile Ninth (upper) decile = 90th percentile Locating Percentiles The following formula allows us to approximate the location of any percentile: Measures of Variability: Interquartile Range Interquartile Range (IQR) = Q3 – Q1 The interquartile range measures the spread of the middle 50% of the observations. Large values of this statistic mean that the 1st and 3rd quartiles are far apart indicating a high level of variability. Usually reported with the Median (M) Graphical Description of the Quartiles: The Boxplot Sometimes also called a box-and-whisker plot Uses the Five Number Summary: Minimum Q1 M Q3 Maximum The “box” shows the center of the data and the general shape, the “whiskers” show the spread of the data If the data extends beyond the whiskers of the plot, there are outliers in the dataset, therefore, this is a good summary of data with outliers! You can easily create side-by-side boxplots to compare multiple groups The Boxplot 1.5(Q3 – Q1) 1.5(Q3 – Q1) Whisker S Whisker Q1 Q2 Q3 L Whiskers are calculated as 1.5(Q3-Q1). In the plot above, there is an outlier at the largest value (L) Boxplots mimic the general shape of the distribution. Measures of Linear Relationship Numerical measures of linear relationship that provide information as to the strength & direction of a linear relationship (if any) between two variables. Covariance - is there any pattern to the way two variables move together? Coefficient of correlation - how strong is the linear relationship between two variables? Measures of Linear Relationship: Covariance population mean of variable X, variable Y sample mean of variable X, variable Y Note: divisor is n-1, not n as you may expect. Measures of Linear Relationship: Covariance There is also a shortcut for calculating sample covariance directly from the data: Interpretation: Covariance When two variables move in the same direction (both increase or both decrease), the covariance will be a large positive number. When two variables move in opposite directions, the covariance is a large negative number. When there is no particular pattern, the covariance is a small number. Measures of Linear Relationship: Correlation The Coefficient of Correlation (a.k.a., the correlation) is the covariance divided by the standard deviations of the variables Greek letter “rho” From the correlation, we can determine the strength, direction, and linearity of the association between X and Y. The correlation is the “numerical scatterplot” Interpretation: Correlation The advantage of the coefficient of correlation over covariance is that it has fixed range from -1 to +1, thus: If the two variables are very strongly positively related, the coefficient value is close to +1 (strong positive linear relationship). If the two variables are very strongly negatively related, the coefficient value is close to -1 (strong negative linear relationship). No straight line relationship is indicated by a coefficient close to zero. Measures of Linear Relationship: Least Squares Method Recall, the slope-intercept equation for a line is expressed in these terms: y = mx + b Where: m is the slope of the line b is the y-intercept. If we’ve determined that a linear relationship exists, can we determine a linear function? Measures of Linear Relationship: Least Squares Method …produces a straight line drawn through the points so that the sum of squared deviations between the points and the line is minimized. This line is represented by the equation: Value of x data (usually given) Estimated value of y determined by the line y-intercept slope