Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
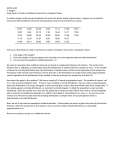
MATH-1410 C. Haugen Using PHStat2 to Create Confidence Intervals for a Population Mean A random sample of the annual precipitation (in inches) for Nome, Alaska is given below. Suppose we are asked to construct a 95% confidence interval for the population mean and to interpret our answer. 18.31 14.93 24.38 14.30 17.13 13.05 13.43 19.87 9.08 22.15 7.39 10.44 14.17 17.62 19.76 20.66 24.25 20.09 22.06 15.46 17.49 17.10 12.29 13.67 9.93 19.25 16.27 19.06 20.14 20.80 14.97 14.92 15.23 There are a few things we need to ask before we build a confidence interval for a population mean. 1. How large is the sample? 2. Does the variable of interest appear to be normally or at least approximately normally distributed? 3. Do we know the population standard deviation, ? We need to remember that confidence intervals are based on sampling distributions of statistics. The Central Limit Theorem (see p. 268) gives us information about the distribution of sample means for samples of size n. If the variable of interest is normally distributed, then the distribution of sample means will be normal regardless of the sample size. The beauty of the Central Limit Theorem is that it also tells us the distribution of sample means will be approximately normal regardless of the distribution of the variable of interest as long as the sample size is at least 30. How does that apply to this problem? We have a sample of 33 annual precipitation levels. The variable of interest, call it X, is the annual precipitation level. X may or may not follow a normal distribution. We can make an educated guess about the distribution of X using a histogram, a stem-and-leaf plot, and/or a box-and-whisker plot of the sample data. If the sample appears normally distributed, i.e. symmetric and bell-shaped, it is likely the population is also normally distributed. When the sample size is less than 30, Statisticians will go one step further and create a normal probability plot to check for normality (see Appendix C p. A30 for more details). Fortunately for us, since n = 33, we can use the Central Limit Theorem to claim that the sampling distribution of sample mean annual precipitation levels is approximately normally distributed. Next, we ask if we know the population standard deviation. Unfortunately we were not given this piece of information. However, when the sample size is 30 or greater, we can use the sample standard deviation as a reasonable approximation of . Now we are ready to create our confidence interval. 1. Open a new Excel Workbook, enter the sample data in the first column, click on the Add-Ins tab, click PHStat2 in the Add-Ins ribbon, and then click on Confidence Intervals. We are given several options to choose from. The first two are used for estimating a population mean. The very first option assumes we know the population standard deviation (or at least have a good approximation for it). We would use this option if we wanted to build a confidence interval based on a normal distribution. The second option assumes we do not know the population standard deviation (and the sample size is less than 30). In this case, the confidence interval is based on a t-distribution. For our problem, we will select the first option. Before we do that, we can have Excel calculate the sample standard deviation of the data set (Data → Data Analysis → Descriptive Statistics…). 2. The Confidence Interval dialog box should appear on the screen. We can enter our approximation for the population standard deviation. The default confidence level is 95%. We know the sample size and Excel already found the sample mean for us. We can enter at Title for our output if we like. 3. Once we click the Ok button, we should see something like the following in a new worksheet. Here is a copy of the output: Annual Precipitation Data Population Standard Deviation Sample Mean Sample Size Confidence Level 4.2345 16.656 33 95% Intermediate Calculations Standard Error of the Mean 0.737131834 Z Value -1.95996398 Interval Half Width 1.444751847 Confidence Interval Interval Lower Limit 15.21124815 Interval Upper Limit 18.10075185 The cyan table displays what we entered in the dialog box earlier. The white table shows us some of the intermediate work (The Interval Half Width is also known as the Margin of Error). The yellow table gives us the final result. Interpretation: We are 95% confident that the mean annual precipitation in Nome, Alaska is somewhere between 15.211 and 18.101 inches.