Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
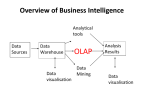
The purpose of this lecture is to provide you with an understanding of the OLAP concepts. In the literature, you will find that different OLAP tools may have different names for the exact same concept. This lecture focuses on the names and definitions when using the Cognos suite of OLAP tools. For more details, refer to OLAP dictionary here. Upon successful completion of this tutorial, you will be able to: 1. Define OLAP 2. Explain OLAP cubes 3. Describe Dimensions 4. Explain Categories 5. Describe Measures 6. Describe Nesting 7. Explain Aggregation Cubes What is an OLAP Cube? As you saw in the definition of OLAP, the key requirement is multidimensional. OLAP achieves the multidimensional functionality by using a structure called a cube. The OLAP cube provides the multidimensional way to look at the data. The cube is comparable to a table in a relational database. The specific design of an OLAP cube ensures report optimization. The design of many databases is for online transaction processing and efficiency in data storage, whereas OLAP cube design is for efficiency in data retrieval. In other words, the storage of OLAP cube data is in such a way as to make easy and efficient reporting. A traditional relational database treats all the data in a similar manner. However, OLAP cubes have categories of data called dimensions and measures. For now, a simple definition of dimensions and measures will suffice. A measure represents some fact (or number) such as cost or units of service. A dimension represents descriptive categories of data such as time or location. The term cube comes from the geometric object and implies three dimensions, but in actual use, the cube may have more than three dimensions. The following illustration graphically represents the concept of an OLAP cube. Figure 1: OLAP Cube In figure 1, time, product, and location represent the dimensions of the cube, while 174 represents the measure. Recall that a dimension is a category of data and a measure is a fact or value. Three important concepts associated with analyzing data using OLAP cubes and an OLAP reporting tool are slicing, dicing, and rotating. Cubes Slicing A slice is a subset of a multidimensional array corresponding to a single value for one or more members of the dimensions not in the subset. For example, if the member Actuals is selected from the Scenario dimension, then the sub-cube of all the remaining dimensions is the slice that is specified. The data omitted from this slice would be any data associated with the non-selected members of the Scenario dimension, for example Budget, Variance, Forecast, etc. From an end user perspective, the term slice most often refers to a two- dimensional page selected from the cube. Figure 2: Slicing-Wireless Mouse Figure 2 illustrates slicing the product Wireless Mouse. When you slice as in the example, you have data for the Wireless Mouse for the years and locations as a result. Stated another way, you have effectively filtered the data to display the measures associated with the Wireless Mouse product. Figure 3: Slicing-Asia Figure 3 illustrates slicing the location Asia. When you slice as in the example, you have data for Asia for the product and years as a result. Stated another way, you have effectively filtered the data to display the measures associated with the Asia location. Top Bottom Cubes Dicing of of Form Form A related operation to slicing is dicing. In the case of dicing, you define a subcube of the original space. The data you see is that of one cell from the cube. Dicing provides you the smallest available slice. Figure 4 provides a graphical representation of dicing. Figure 4: Dicing Cubes Rotating Rotating changes the dimensional orientation of the report from the cube data. For example, rotating may consist of swapping the rows and columns, or moving one of the row dimensions into the column dimension, or swapping an off-spreadsheet dimension with one of the dimensions in the page display (either to become one of the new rows or columns), etc. You also may hear the term pivoting. Rotating and pivoting are the same thing. Figure 5: Rotating Dimensions Recall, that a dimension represents descriptive categories of data such as time or location. In other words, dimensions are broad groupings of descriptive data about a major aspect of a business, such as dates, markets, or products. The value of OLAP in reporting data is having levels within the dimensions. Each dimension includes different levels of categories. Dimension levels allow you to view general things about your data and then look at the details of your data. Think of the levels of categories as a hierarchy. For example, your OLAP cube could have a time dimension. The time dimension then could have year, quarter, and month as the levels, as in Figure 6. Another example is location as a dimension. For the location dimension, you could have region, country, and city as the levels (shown in Figure 6). An important concept to OLAP is drilling. Drilling refers to the ability to drill-up or drill-down. These levels of categories (hierarchies) are what provide the ability to drill-up or drill-down on data in an OLAP cube. When you drill-down on a dimension, you increase the detail level of viewing the data. For example, you start with the year and view that data, but you want to see the data by each quarter of the year. You would drill-down to see the quarterly data. You could drill-down again to see the monthly data within a specific quarter. Figure 6: Dimensions Categories Dimensions have members or categories. A category is an item that matches a specific description or classification such as years in a time dimension. Categories can be at different levels of information within a dimension. You can group any category into a more general category. For instance, you can group a set of dates into a month, a set of months into quarters, and a set of quarters into years. In this example, years, quarters, and months are all categories of the time dimension. Categories have parents and children. A parent category is the next higher level of another category in a drill-up path. For example, 2003 is the parent category of 2003 Q1, 2003 Q2, 2003 Q3, and 2003 Q4. A child category is the next lower level category in a drill-down path. For example, January is a child category of 2003 Q1. Figure 7 below shows you the time, product, and location dimensions with the parent and children categories. In the time dimension, you see the parent Year Category and the children Quarter Category and Month Category. Figure 7: Categories Measures The tutorial to this point has provided you with a definition of OLAP, a description of cubes, the meaning of dimensions, and a description of categories. The focus now is an explanation of measures. The measures are the actual data values that occupy the cells as defined by the dimensions selected. Measures include facts or variables typically stored as numerical fields, which provide the focal point of investigation using OLAP. For instance, you are a manufacturer of cellular phones. The question you want answered is how many xyz model cell phones (product dimension) did a particular plant (location dimension) produce during the month of January 2003 (time dimension). Using OLAP, you found that plant a produced 2,500 xyz model cell phones during January 2003. The measure in this example is the 2,500. Additionally, measures occupy a confusing area of OLAP theory. Some believe that measures are like any other dimension. For example, one can think of a spreadsheet containing cell phones produced by month and plant as a two-dimensional picture, but the values (measures)—the cell phones produced—effectively form a third dimension. However, although this dimension does have members (e.g. actual production, forecasted production, planned production), it does not have its own hierarchy. It adopts the hierarchy of the dimension it is measuring, so production by month consolidates into production by quarter, production by quarter consolidates into production by year. The example in Figure 8 shows the measure Volume of Product. Each value in Figure 8 is the measure of Volume of Product per year listed by product. From Figure 8, ABC Company produced 84,000 modems in 2003. Figure 8: Measures Nesting Nesting is a function in which you have more than one dimension or category in a row or column. Nesting provides a display that shows the results of a multidimensional query that returns a sub-cube, i.e., more than a two-dimensional slice or page. The column/row labels will display the extra dimensionality of the output by nesting the labels describing the members of each dimension. Figure 9 illustrates nesting. In the top table, the nested dimensions are time (year) and location (countries) in rows. By nesting in this example, you can see the volume of products for each North American Country in 2003. In the bottom table, the nested dimensions are products (devices) and location (countries) in columns. By nesting in this example, you can see the volume of products by quarter for each North American Country for 2003 Q1 and Q2. Figure 9: Nesting Aggregation One of the keywords for OLAP is fast. Recall that fast refers to the speed that an OLAP system is able to deliver most responses to the end user. Essential for OLAP is to produce fast query times. This is one of the basic tenets for OLAP—the capability to naturally control data requires quick retrieval of information. In general, the more calculations that OLAP needs to perform in order to produce a piece of information, the slower the response time. Consequently, to keep query times fast, pieces of information that users frequently will access, but need to be calculated, are pre-aggregated. Pre-aggregated data means that the OLAP system calculates the values and then stores them in the database as new data. An example of a type of data that may be precalculated is summary data, such as failure rate for days, months, quarters, or years. Approaches to aggregation affect both the size of the database and the response time of queries. The more values a system precalculates, the more likely a user request already has a value that has already been calculated, thus increasing the the response time because the value does not need to be requested. On the other hand, if a system precalculates all possible values, not only will the size of the database be unmanageable, but also the time it takes to aggregate will be long. Additionally, when values are added to the database, or perhaps changed, that information again needs to be propagated through the precalculated values that depend on the new data. Thus, updating the database can be time-consuming if too many values are pre-calculated for the database. Figure 10: Aggregation Summary To summarize what you learned in this tutorial: • OLAP is a category of software tools that provides Fast Analysis of Shared Multidimensional Information (FASMI). • An OLAP cube is the concept that achieves the multidimensional functionality that provides the method to look at data from a variety of angles. • Slicing, dicing, and rotating are methods in OLAP that change the view of the data in different ways. • Dimensions are the descriptive categories of data that apply to major aspects of a business and that dimensions have hierarchies. • Categories are items that match a precise organization that you use to perform drill-up or drill-down operations. • Measures are the actual data values for a select set of dimensions. • Nesting provides the ability to add more than one dimension or category to a column or row. • Aggregation is the process of precalculating summary data values.