Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
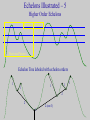
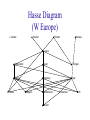
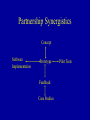
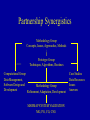
This report is very disappointing. What kind of software are you using? Space Age and Stone Age Syndrome • Data: • Analysis: Data Analysis Space Age Stone Age Space Age/Stone Age Space Age/Stone Age Space Age Stone Age + + + The Value of Mapping Maps provide an efficient and unique method of demonstrating distributions of phenomena in space. Though [maps are] constructed primarily to show facts, to show spatial distributions with an accuracy which cannot be attained in pages of description or statistics, their prime importance is as research tools. They record observations in succinct form; they aid analysis; they stimulate ideas and aid in the formation of working hypotheses; they make it possible to communicate findings; they assist in research and policy research. Disease Mapping •Disease Mapping is about the use and interpretation of maps showing the incidence or prevalence of disease. •Disease data occur either as individual cases or as groups (or counts) of cases within census tracts. •Any disease map must be considered with the appropriate background population which gives rise to the incidence. •Maps answer the question: where? They can reveal spatial patterns not easily recognized from lists of statistical data. •Maps showing infectious diseases can help elucidate the cause of disease. Maps showing non-infectious diseases may be used to generate hypotheses of disease causation. National Mortality Maps and Health Statistics • Health Service Areas, Counties, Zip Codes, … • Geographical Patterns for Health Resource Allocation • Study Areas for Putative Sources of Health Hazard – Balance between dilution effect and edge effect • Case Event Analysis and Ecological Analysis – Thresholds, contours, corresponding data • Regional Comparisons and Rankings with Multiple Indicators/Criteria • Choices of Reference/Control Areas Baltimore Asthma Project Interdisciplinary Analysis of Childhood Asthma in Baltimore, MD The impact of asthma is escalating within the U.S. and children are particularly impacted with hospitalization increasing 74% since 1979. This study is investigating climate and environmental links to asthma in Baltimore, Maryland, a city in the top quintile for children’s asthma in the U.S. Aerosol Size Inner Harbor 1. Collect and integrate in-situ measurements, remotely sensed measurements and clinical records that have possible relationships to the occurrence of asthma in the Baltimore, Maryland region. 2. Identify key trigger variables from the data to predict asthma occurrence on a spatial and temporal basis. 3. Organize a multidisciplinary team to assist in model design, analysis and interpretation of model results. 4. Develop tools for integrating, accessing and manipulating relevant health and remote sensing data and make these tools available to the scientific and health communities. Time Partners: • • • • • • Baltimore City Health Department Baltimore City School System Baltimore City Planning Council, Mayor’s Office State of Maryland Department of the Environment State of Maryland Department of Health and Human Services University of Maryland Asthma Assessment from GIS techniques Urban Heat Islands • Use of aircraft and spacecraft remote sensing data on a local scale to help quantify and map urban sprawl, land use change, urban heat island, air quality, and their impact on human health • (e.g. pediatric asthma) Infectious Diseases • Use of remote sensing data and other available geospatial data on a continental scale to help evaluate landscape characteristics that may be precursors for vector-borne diseases leading to early warning systems involving landscape health, ecosystem health, and human health • Water-Borne Diseases • Air-Borne Diseases • Emerging Infectious Diseases Mekong Malaria and Filariasis Projects • • To develop a predictive model for assessing risk areas of malaria transmission in the Greater Mekong Subregion, and To make risk maps for filariasis map breeding sites for major vector species explore the linkage between vector population density and disease transmission intensity with environmental variables Anticipated Benefits – Reduce malaria and filariasis transmission rates – Minimize environmental damage by strategically using larvicides and insecticides – Improve the health status and economic activity of populations affected by malaria and filariasis in the Greater Mekong Sub-region Source: Southeast Asian Journal of Tropical Medicine and Public Health, volume 30 supplement 4, 1999. • Quantities of African dust transported by winds across the Atlantic have been increasing due to prolonged and agricultural practices in North Africa • Recent studies show dust carries microbes and pollutants that have been detected in the US and Caribbean Islands • Objectives of new studies are to determine harmful effects, e.g., childhood asthma in Puerto Rico African Dust Vector-Borne Disease Detection Using NASA Satellite Data Using near real-time climate data and satellite imagery, scientists have discovered environmental triggers for Rift Valley Fever and other diseases Prediction of Rift Valley Fever outbreaks may be made up to 5 months in advance in Africa NDVI anomaly patterns over Africa during the 1997/98 ENSO warm event • Research program on the relationships between environmental parameters (e.g vegetation), climate ( e.g. rainfall) and outbreaks of diseases such as: • Rift Valley Fever (RVF) • St. Louis Encephalitis Fever (EHF) • Dengue Fever • Ebola Fever • Hanta Virus and others BENEFITS • Map and monitor Eco-climatic patterns associated with disease outbreaks from satellite platforms • Better understanding the dynamics of climate-disease interactions • Advance warning of disease outbreaks would enable preventive measures (vaccination, vector control, etc.) to be undertaken • Provide disease surveillance tools to public health authorities A New NASA Initiative... • To apply Space-based capabilities to examine environmental conditions that affect human health • To enable easy use of and timely access to Earth science data and models • To help our health community partners to develop practical early warning systems Statistical Ecology, Environmental Statistics, Health Statistics—1 Sampling, Monitoring, and Observational Economy Initiatives — Twentieth Century— • • • • • Capture-Mark-Recapture Composite, Ranked Set Adaptive with Clusters and Networks Transect, Selection Bias, Meta-Analysis Partnerships: Statistical Ecology, Environmental Statistics, Health Statistics—2 Multiscale Advanced Raster Map Analysis System Initiative—1 • Geospatial Patterns and Pattern Metrics – Landscape patterns, disease patterns, mortality patterns • Surface Topology and Spatial Structure – Hotspots, outbreaks, critical areas – Intrinsic hierarchical decomposition, study areas, reference areas – Change detection, change analysis, spatial structure of change Statistical Ecology, Environmental Statistics, Health Statistics—3 Multiscale Advanced Raster Map Analysis System Initiative—2 • Partially Ordered Sets and Hasse Diagrams – Multiple indicators, comparisons, fuzzy rankings – Intrinsic hierarchical groups, reference areas – Performance measures, composite indices • System Design and Development – BAT, BPT, and synergistic collaboration – Bilateral and multilateral partnerships National Mortality Maps and Statistics Geographic Patterns—1 • Mortality rate due to a specific cause of death • Elevated rates areas, patterns • Ordinal thematic maps • Transition pattern, transitionogram • Transition matrices; spatial association with varying distance • Comparatives with different causes of death National Mortality Maps and Statistics Geographic Patterns—2 • Surface topology and spatial structure • High mortality area delineation – Hotspots, clusters, outbreaks, corridors • Surface smoothing • Masking of true geographic patterns? • Echelon analysis, original surface, smoothed surface National Mortality Maps and Statistics Relationships—1 • Study areas for response and explanatory variables relationships • Response proximity – Hotspots, thresholds, contours, counter strips • Spatial proximity – Buffers, putative hazards • Dilution effect and edge effect National Mortality Maps and Statistics Relationships—2 • • • • • • • Intrinsic study areas Intrinsic hierarchical decomposition Consistent vertical and horizontal balance Echelons and echelon trees Urban heat islands and pediatric asthma Infectious and vector-borne diseases UV radiation Multiscale Advanced Raster Map System • MARMAP SYSTEM • Design and Development • PARTNERSHIP NSF Digital Government Research Program Proposal for Invited Re-Submission MARMAP SYSTEM • Partnership communication of June 11, 2001. • NSF Partnership Proposal. • Review and Response-1 • Review and Response-2 • Review and Response-3 MARMAP SYSTEM • Partnership Research and Outreach Prospectus: http://www.stat.psu.edu/~gpp/PDFfiles/prospectus 8-00.pdf • Our web page for raster map analysis: http://www.stat.psu.edu/~gpp/newpage11.htm • Our web page for raster map monographs: http://www.stat.psu.edu/~gpp/raster.htm • Our web page for UNEP HEI http://www.stat.psu.edu/~gpp/unephei.htm Geospatial Cell-based Data Kinds of Data • Cell as a Unit (Regular grid layout) – – – – Categorical Ordinal Numerical Multivariate Numerical • Cell as an Object (Irregular cell sizes and shapes) – – – – Partially Ordered Ordinal Numerical Multivariate Numerical Approaches to Research Issues Methods and Tools Data Procurement and Management Model-based Pattern Extraction Echelons for Change Detection Surface Analysis Visualization Tools for Research & Communication PHASES for Data Compression Model-based Error Maps for Thematic Accuracy Assessment Echelons for Spatial Complexity with Multiple Indicators Software Design and Development Data-based Empirical Pattern Extraction Sampling Designs for Thematic Accuracy Assessment Partial Ordering Procedures with Multiple Indicators Partnership Synergistics Landscape Pattern Extraction Regional Geographic Patterns Spectral data Empirical extraction Thematic data Empirical extraction Spectral data Model-based extraction Thematic data Model-based extraction Model-based Pattern Extraction • Pattern = Spatial variability in thematic maps • Proposed research limited to raster maps • Possible Parametric Models: – Geostatistics (Multi-indicator) – Markov Random Fields – Hierarchical Markov Transition Matrix models (HMTM) Upper Echelons of Surfaces Spatial Complexity with Single Response Variable Echelons Approach • Echelon method analyzes cellular data pertaining to surface variables. Examines changes in topological connectivity of upper level sets as the level changes. • Echelons elucidate spatial structure, help determine critical areas and corridors, emphasize areas of complexity, and map various aspects of surface organization • Response can be numerical or ordinal • Cellular tessellation can be regular or irregular Echelons sDescription—1 Ingredients of an Echelon Analysis: – Tessellation of a geographic region: j c k h f d a b e g a, b, c, … are cell labels i – Response value Z on each cell. Determines a tessellated (piece-wise constant) surface with Z as elevation. • How does connectivity (number of connected components) of the tessellation change with elevation? Echelons Description -- 2 • Think of the tessellated surface as a landform • Initially the entire surface is under water • As the water level recedes, more and more of the landform is exposed • At each water level, cells are colored as follows: – Green for previously exposed cells (green = vegetated) – Yellow for newly exposed cells (yellow = sandy beach) – Blue for unexposed cells (blue = under water) • For each newly exposed cell, one of three things happens: – New island emerges. Cell is a local maximum. Morse index=2. Connectivity increases. – Existing island increases in size. Cell is not a critical point. Connectivity unchanged. – Two (or more) islands are joined. Cell is a saddle point Morse index=1. Connectivity decreases. Echelons Illustrated -- 1 Newly exposed island j c k Echelon Tree h f d a b e g a g a b,c i Island grows j c k h f d a b e i Echelons Illustrated -- 2 Echelon Tree Second island appears j h f d a b e c k g i c k h f d a b e d New echelon Both islands grow j a b,c i g a b,c e d f,g Echelons Illustrated -- 3 Islands join – saddle point j h f d a b e c k a c k d f,g e i h New echelon a h f d a b e b,c g Exposed land grows j Echelon Tree i g b,c e d f,g h i,j,k Three echelons Echelons Illustrated -- 4 • • • • Each branch in echelon tree determines an echelon Each echelon consists of cells in the tessellation The echelons partition the region Each echelon determines a set of response values Z (and a corresponding set of values of the explanatory variables X, if any) Echelon Partitioning j c k h f d a b e i Echelon Tree g a b,c e d f,g h i,j,k Three echelons Echelons Illustrated – 5 Higher Order Echelons Receding Waterline Previous Pictures Echelon Tree labeled with echelon orders 1 1 1 1 2 2 2 (not 3) 3 1 Echelons Illustrated – 6 Echelon Order Defined Echelon Tree labeled with echelon orders 1 1 1 1 1 2 2 2 (not 3) 3 • Analogy with stream networks (Horton-Strahler order) • Leaf branches have order 1 • When two branches of orders p and q join, the new branch has order: Max(p, q) if p q p+1 if p = q Echelons Illustrated – 7 Echelon Smoothing Echelon Tree labeled with echelon orders Prune ? 1 1 Prune ? 1 1 1 2 2 2 (not 3) 3 • Need for smoothing echelon trees • Alternative to direct smoothing of surface values • In complicated echelon trees, root nodes may be most indicative of noise and become prime candidates for pruning (contraction would be a better term) • Criteria for pruning: Echelon relief, Echelon basal area, others? • What is the corresponding smoothed surface? Spatial Complexity with Single Response Variable Echelons Approach • • • • • • Issues to be addressed: Echelon trees and maps Echelon profiles and other tree metrics Noise effects and filtering Comparing echelon trees and maps Echelon stochastics: surface simulation, tree simulation, tree metric distributions Pre-Classification Change Detection Echelons Approach • Change vector approach (cell by cell) with actual spectral data • Change vector approach (cell by cell) with compressed (hyperclustered) spectral data • Pattern-based approach (compressed data only): Compare segment pattern at time1 with segment pattern at time 2. Spatial Complexity with Multiple Indicators Echelons Approach • Compare echelon features among indicators for consistency/inconsistency: – Order – Number of ancestors (distance from root of tree) • Compression by treating features as pseudobands Geospatial Analysis for Disease Surveillance—1 Case Event Point Data & Areal Unit Count Data • • • • • Geospatial surveillance Cluster detection and evaluation Spatial scan statistics Choice of zonal parameter space Candidate zones as circular windows of expanding size • Elliptical windows: long island breast cancer study • Hyperclusters, echelon trees, upper surface sets defined by thresholds-based nodes Geospatial Analysis for Disease Surveillance—2 Case Event Point Data & Areal Unit Count Data • • • • Spatio-temporal surveillance Cylinders-based spatio-temporal scan statistics Three-dimensional echelons and echelon trees Candidate zones as upper surface sets defined by thresholds-based nodes • Temporal persistence and patterns • Cluster alarms, suspect clusters, and their evaluation Geospatial and Spatiotemporal Patterns of Change • • • • • • • • • • Multiple cancer mortality statistics and maps Multiple disease incidence statistics and maps Across United States over years Across individual states over years Pooling over types of cancer/disease Pooling over types of people Change detection and change analysis In space, in time, in space-time Structure and behavior of chance Persistence and patterns of elevated areas Spatial and Spatiotemporal Scan Statistics—1 SaTScan • To evaluate reported spatial or spatiotemporal disease clusters • To see if they are statistically significant • To test whether a disease is randomly distributed • To perform geographical surveillance of disease • To detect areas of significantly high or low rates Spatial and Spatiotemporal Scan Statistics—2 SaTScan • Poisson model, where the number of events in an area is Poisson distributed under the null hypothesis • Bernoulli model, with 0/1 event data such as cases and controls • The program adjusts for the underlying inhomogeneity of a background population • With the Poisson model, the program can also adjust for any number of categorical variates provided by the user SaTSCAN – 1 • Goal: Identify geographic zone(s) in which a response is significantly elevated relative to the rest of a region • A list of candidate zones Z is specified a priori. – This list becomes part of the parameter space and the zone must be estimated from within this list. – Each candidate zone should generally be spatially connected, e.g., a union of contiguous spatial units or cells. – Longer lists of candidate zones are usually preferable – Expanding circles or ellipses about specified centers are a common method of generating the list SaTSCAN – 2 • Example: Infected individuals in a tessellated region G with cells (spatial units) A • m(A) = # individuals in cell A (known) x(A) = # infected individuals in cell A (data) • Individual infection results from independent Bernoulli trials • Full model: – Bernoulli parameter is p inside zone Z and q p outside Z – p, q, Z have unknown parameter values and must be estimated • Null model: Bernoulli parameter is constant (but unknown) throughout the region G SaTSCAN – 3 • Estimation: Maximum likelihood Likelihood = L( Z, p, q ) – For fixed Z maximize (analytically) with respect to p and q giving a partial likelihood L(Z) – Maximize L(Z) by explicit search through the list of candidate zones giving the likelihood estimate of Z SaTSCAN – 4 • Hypothesis Testing: Likelihood ratio statistic L(Full) L(Null) L( Zˆ , pˆ , qˆ | Full) L( pˆ | Null) – Non-standard situation. Traditional ML theory does not apply – Need to determine the null distribution by Monte Carlo simulation of replicate data sets under the null model. For each data set Z must be estimated and the value of the likelihood ratio test statistic computed SaTSCAN – 5 • Question: Are there data-driven (rather than a priori) ways of selecting the list of candidate zones ? • Motivation for the question: A human being can look at a map and quickly determine a reasonable set of candidate zones and eliminate many other zones as obviously uninteresting. Can the computer do the same thing? • A data-driven proposal: Candidate zones are the connected components of the upper level sets of the response surface. The candidate zones have a tree structure (echelon tree is a subtree), which may assist in automated detection of multiple, but geographically separate, elevated zones. Null distribution: If the list is data-driven (i.e., random), its variability must be accounted for in the null distribution. A new list must be developed for each simulated data set. Multiple Criteria Analysis Multiple Indicators Partial Ordering Procedures • Cells are objects of primary interest, such as countries, states, watersheds, counties, etc. • Cell comparisons and rankings are the goals • Suite of indicators are available on each cell • Different indicators have different comparative messages, i.e., partial instead of linear ordering • Hasse diagrams for visualization of partial orders. Multilevel diagram whose top level of nodes consists of all maximal elements in the partially ordered set of objects. Next level consists of all maximal elements when top level is removed from the partially ordered set, etc. Nodes are joined by segments when they are immediately comparable. Multiple Criteria Analysis Multiple Indicators Partial Ordering Procedures • • • • Issues to be addressed: Crisp rankings, interval rankings, fuzzy rankings Fuzzy comparisons Echelon analysis of partially ordered sets with ordinal response levels determined by successive levels in the Hasse diagram • Hasse diagram metrics: height, width, dimension, ambiguity (departure from linear order), etc. • Hasse diagram stochastics (random structure on the indicators or random structure on Hasse diagram) • Hasse diagram comparisons, e.g., compare Hasse diagrams for different regions Hasse Diagram (all countries) 1 2 3 8 9 13 17 22 4 10 45 15 25 26 36 46 6 12 23 28 43 5 48 11 14 18 21 32 27 39 47 7 29 41 50 31 56 20 40 35 51 54 19 38 33 42 52 16 53 60 24 44 55 65 68 76 71 72 34 49 66 69 30 73 37 82 80 114 86 102 88 112 113 57 58 61 62 63 64 67 74 75 77 78 79 83 84 85 93 94 96 98 99 101 104 111 131 59 81 70 89 95 100 97 87 107 90 103 105 135 117 91 106 116 119 92 108 110 109 118 122 130 115 120 121 127 124 126 129 138 136 133 123 125 140 132 134 128 137 139 141 Hasse Diagram (W Europe) Iceland Sweden Finland Norway Austria Greece Switzerland Spain Portugal France Germany Italy Belgium Netherlands Ireland Denmark UK Ranking Partially Ordered Sets – 2 An Example Poset (Hasse Diagram) e a b c d f Jump Size: 3 Some linear extensions a a a b b c c b a a b e c c c e b d d e d d e e d f f f f f 1 5 4 2 Jump or Imputed Link (-------) is a link in the ranking that is not implied by the partial order Ranking Partially Ordered Sets – 3 In the example from the preceding slide, there are a total of 16 linear extensions, giving the following frequency table. Rank Element 1 2 3 4 5 6 Totals a 9 5 2 0 0 0 16 b 7 5 3 1 0 0 16 c 0 4 6 6 0 0 16 d 0 2 4 6 4 0 16 e 0 0 1 3 6 6 16 f 0 0 0 0 6 10 16 Totals 16 16 16 16 16 16 • Each (normalized) row gives the rank-frequency distribution for that element • Each (normalized) column gives a rank-assignment distribution across the poset Ranking Partially Ordered Sets – 5 Linear extension decision tree Poset (Hasse Diagram) e a b c d f b a c e b b b e d d e d c d e f d d e c e c f d a e f d e d f e d a c c f e f e f f e f e f f e f e f e Jump Size: 1 3 3 2 3 5 4 3 3 2 4 3 4 4 2 2 f f f Ranking Partially Ordered Sets – 8 • In many cases of practical interest e(S) is too large for actual enumeration in a reasonable length of time. • For example, HEI data set has 141 countries arranged in a Hasse diagram with 14 levels and level sizes 16, 14, 15, 12, 16, 24, 10, 9, 10, 7, 2, 2, 3, 1 This gives 8.6 10105 e(S) 1.9 10243 which is completely beyond present-day computational capabilities. • So what do we do? • Markov Chain Monte Carlo (MCMC) applied to the uniform distribution on the set of all linear extensions lets us estimate the normalized rank-frequency distributions. Estimating the absolute frequencies (approximate counting) is also possible but somewhat more difficult. Cumulative Rank Frequency Operator – 5 An Example of the Procedure In the example from the preceding slide, there are a total of 16 linear extensions, giving the following cumulative frequency table. Rank Element 1 2 3 4 5 6 a 9 14 16 16 16 16 b 7 12 15 16 16 16 c 0 4 10 16 16 16 d 0 2 6 12 16 16 e 0 0 1 4 10 16 f 0 0 0 0 6 16 Each entry gives the number of linear extensions in which the element (row) label receives a rank equal to or better that the column heading Cumulative Rank Frequency Operator – 6 An Example of the Procedure Cumulative Frequency 16 a b c d e f 12 8 16 4 0 1 2 3 4 5 6 Rank The curves are stacked one above the other and the result is a linear ordering of the elements: a > b > c > d > e > f Cumulative Rank Frequency Operator – 7 An Example where Original Poset F (Hasse Diagram) F 2 F 3 a a a f f f e e e b b b ad ad ad c c,g (tied) h h f a b c F must be iterated e g h d g c h g Breast Cancer by ZIP Code New York State, 1993-1997 Simple SIRs as observed/expected SIR (maximum likelihood estimate) more than 100% above expected 50% to 100% above expected 15% to 49% above expected within 15% of expected 15% to 50% below expected more than 50% below expected very sparse data (28) (93) (279) (471) (338) (100) (104) Ranking Possible Disease Clusters in the State of New York Data Matrix cluster * SIR LF2 LM14 LM4 LF7 B2 B4 LM1 LM3 LM7 2.09 1.5 2.04 1.51 1.21 1.25 2.32 2.13 2.12 LL 10.36 36 19.21 15.43 31.3 28.4 21.91 21.26 13.33 Young Multiple Atypical Late Stage Cases Cancers Demographics of Diagnosis 2 1 1 2 2 0 0 2 2 0 0 2 1 1 1 1 2 1 0 2 1 0 0 0 0 1 0 2 1 1 0 1 1 0 0 2 * LF = lung, female; LM = lung, male; B = breast Multiple Criteria Analysis Multiple Indicators and Choices Health Statistics Disease Etiology, Health Policy, Resource Allocation • First stage screening – Significant clusters by SaTScan and/or upper surface level echelon sets • Second stage screening – Multicriteria noteworthy clusters • Final stage screening – Follow up clusters for etiology, intervention based on multiple criteria MARMAP SYSTEM Software Design and Development • • • • • • Algorithm development Computer programming/Coding User interface design and implementation User output/Visualization Documentation/On-line help Other considerations: – Supported platforms (Windows, UNIX ?, LINUX ?) – Programming languages ? (C/C++, Java, Visual Basic, Delphi, etc.) – Software distribution (CD, Website) CENTER FOR GEOSPATIAL INFORMATICS AND STATISTICS -proposed federal partnershipNSF: DGP, FRG, ITR, SDSC-NPACI NASA, USGS, EPA, USFS, NRCS, NASS, DOT, NCHS, CDC, NCI, CENSUS, NIMA, DOD, NOAA Case Study –UNEP - PSU • Nationwide Human Environment Index worldwide • Construction and Evaluation of HEI • Multiple Indicators and Comparisons without Integration of Indicators • Hasse Diagrams, fuzzy rankings, and visualizations • Handbook • Interactive Queries Case Study – NASA - PSU • Issues Involved: • Landcover classification – with available spectral image(s) – with a previous map and current spectral image – with fine or coarse segmentation • Multi-period change detection • Data Integration Case Study – EPA – PSU Issues Involved: • Indicators of Watershed Ecosystem Health • Multiple Landscape Fragmentation Analysis • Echelon Analysis of Spatial Structure and Behavior • Multiscale Bivariate Raster Map Analysis • Regional Human Environment Index: Formulation, Visualization, Evaluation, and Validation Partnership Synergistics Concept Software Implementation Prototype Feedback Case Studies Pilot Tests Partnership Synergistics MG- PG PI/CO-PI CG CSG Partnership Synergistics Methodology Group Concepts, Issues, Approaches, Methods Prototype Group Techniques, Algorithms, Routines Computational Group Data Management, Software Design and Methodology Group Development Refinement, Adaptation, Development MARMAP SYSTEM VALIDATION MG, PG, CG, CSG Case Studies Data Resources Issues Answers Logo for Statistics, Ecology, Environment, and Society