Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
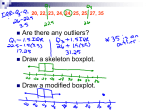
REAL LIMITS Part 1: Getting the Basic Concept of Real Limits Source: http://www.uop.edu/cop/psychology/Statistics/sigfig.html Real Limits- When measuring a continuous variable like time, for example, we must understand that the measure is only an approximation. If we say that a sprinter ran the one hundred meters in 9.4 seconds, we realize that the measurement could range from 9.35 to 9.45 seconds. That is, the runner's time was between 9.35 and 9.45 seconds or 9.4 +/- .05 seconds. These numbers are called the real limits of that measure. Source: http://www.uwsp.edu/psych/stat/2/prelim.htm#RealLim] Since continuous numbers are rounded, they are only approximate. Thus, the number 33 more precisely falls in the range of 32.5-33.5. More generally, the real limits of a number equals the number plus and minus () 1/2 the unit of measurement. Examples: Number Real Limits Unit of 1/2 Unit of meas. meas. Lower Upper 33.3 .1 .05 33.25 33.33 .01 .005 33.325 33.335 33.333 .001 .0005 33.3325 33.3335 1 .5 33 32.5 33.35 33.5 Source: http://visualstats.org/vista-frames/help/class-notes.html Histograms and Real Limits A histogram is used to portray the (grouped) frequency distribution of a variable at the interval or ratio level of measurement. It consists of vertical bars drawn above scores (or score intevals) so that 1. The height of the bar corresponds to the frequency 2. The width of the bar extends to the real limits of the score (interval) Real Limits, Apparent Limits, and Frequency Distributions o Recall that a continuous variable has an infinite number of possible values. It can be represented by a number line that is continuous and has an infinite number of points. However, when we measure a continuous variable we have only a finite measurement process, resulting in numbers that have a finite precision. o If our measurements of a continuous variable are all numbers that are all in whole integer units, our precision of measurement is 1 unit. In this measurement situation, an observed value of 8 would be obtained when the "real value" is 7.8 or 8.21, or any other value between 7.5 and 8.5. Thus, the observed value of 8 actually represents a range of "real values" from 7.5 to 8.5. These values are called the "real limits". o The concept of "real limits" also applies to class intervals. In the table at the right the interval denoted as "60-64" actually has "real limits" of 59.5-64.5. The values denoting the interval as 60-64 are called the "apparent limits". Part 2: Real Limits in Chapter 6 (Normal Distribution, Probability) Source: http://www.psychstat.missouristate.edu/introbook/sbk10m.htm Probability = Area Under the Curve Between any Two Scores Although probability is a common term in the natural language, meaning likelihood or chance of occurrence, statisticians define it much more precisely. The probability of an event is the theoretical relative frequency of the event in a model of the population. The models that have been discussed up to this point assume continuous measurement. That is, every score on the continuum of scores is possible, or there are an infinite number of scores. In this case, no single score can have a relative frequency because if it did, the total area would necessarily be greater than one. For that reason probability is defined over a range of scores rather than a single score. Thus a shoe size of 8.00 would not have a specific probability associated with it, although the interval of shoe sizes between 7.75 and 8.25 would. An Example: Shoe Sizes Let’s say we want a graph of the distribution of women’s shoe sizes. In actuality shoe size a discrete variable, on an interval scale, so we would use a histogram. We can also use a frequency polygon, and smooth out the curve, so that it would look like a normal curve. Suppose that the frequency polygon of shoe size for women actually looked like the following: If this were the case the proportion (.12) or percentage (12%) of size eight shoes could be computed by finding the relative area between the real limits for a size eight shoe (7.75 to 8.25). The relative area is called probability. The probability model attempts to capture the essential structure of the real world by asking what the world might look like if an infinite number of scores were obtained and each score was measured infinitely precisely. Nothing in the real world is exactly distributed as a probability model. However, a probability model often describes the world well enough to be useful in making decisions. Source: http://visualstats.org/vista-frames/help/class-notes.html Percentiles & Percentile Ranks In order to define what we mean by percentiles and percentile ranks, we first begin by defining cumulative frequencies and cumulative percentages. Cumulative Frequencies: The cumulative frequency of a particular category in a frequency table or distribution is the number of observations in or below that category. Cumulative Percentages: The cumulative percentage of a particular category in a frequency table or distribution is the percentage of observations in or below that category. In the following table, the "cf" column presents cumulative frequencies and the "c%" column presents cumulative percentages. _________________ X f cf c% 5 1 20 100% 4 5 19 95% 3 8 14 70% 2 4 6 30% 1 2 2 10% A "cf" value of a category is the sum of the frequencies in the categories at and below the category in question. A "c%" value of a category is 100 times the cumulative frequency of the category, divided by the total frequency. That is c%=100*(cf/N) Percentile Rank The percentile rank of a particular score is defined as the percentage of the scores in a distribution which are at or below the particular score. It is possible to determine some percentile ranks directly from the frequency distribution table, provided that the percentile ranks are percentages that appear in the table. For example, the percentile rank of X=3.5 is 70% (note that 3.5 is the upper real limit of the category where X=3). Percentile When a score is identified by its percentile rank, the score is called a percentile. It is also possible to determine some percentiles directly from the frequency distribution table, provided that the percentiles are upper real limits of a category. Thus, the 95th percentile is X=4.5, the upper real limit of the X=4 category. Interpolation The process known as interpolation must be used to estimate percentile ranks and percentile for values not given in the table. The interpolation process is explained in the textbook on pages 54-57. A note on The Normal Distribution In the normal distribution, frequencies, actually proportions, correspond to an area.