Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
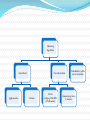
Project Presentation Arpan Maheshwari Y7082,CSE [email protected] Supervisor: Prof. Amitav Mukerjee Madan M Dabbeeru Clustering: Organising a collection of k-dimensional vectors into groups whose members share similar features in some way. To reduce large amount of data by categorizing in smaller set of similar items. Clustering is different from classification. Elements of Clustering : Cluster : ordered list of objects sharing some similarities. Distance Between Two Clusters : Implementation Dependent;e.g. Minkowski Metric Similarity : function SIMILAR(Di , Dj ) ; 0 : no agreement • 1 : perfect agreement Threshold : lowest possible input value of similarity required to join two objects in a cluster. Clustering Algorithms Hierarchical Non-Hierarchical Partiti Agglomerative Divisive oning(e.g.GNG,DBS CAN,K-means) Probabilistic(e.g.Mix ture of Gaussians) Clumping(e.g. Fuzzy C-means) Possible Applications: Marketing Biology & Medical Sciences Libraries Insurance City Planning WWW Growing Neural Gas Proposed by Bernd Fritzke Parametres are constant in time Incremental Adaptive Competitive Hebbian Learning Parametres in GNG: e_b : Learning rate of winner node e_n : Learning rate of neighbours lambda: when new node will be inserted alpha : error decrement of winner nodes upon insertion of new node beta : error decrement of all nodes Algorithm: 1) 2) 3) Initialise a set A to contain two nodes randomly chosen according to probability distribution p(ξ). Generate an input signal ξ according to p(ξ). Determine the winner node s1 and second nearest node s2 such that s1,s2 belong to A. Create an edge between s1 & s2 (if not exist).Set its age to 0. Increase error of s1 by distance between ξ & s1. Move s1 and its neighbors towards input signal by e_w and e_n of difference between the coordinates. 7) Increment age of all edges emanating from s1. 8) Delete all edges with age >= max_age .Delete nodes with no edges. 9) If no. of input signals generated so far is a multiple of λ, insert a new node ,r. a)Find node with largest error ,q and neighbor of q with largest error ,f . b)Assign r the mean position of q and f and errorr = (errorq + errorf )/2 c)errorq -= α * errorq & errorf -= α* errorf d)add r in A. 10) Decrease error of all nodes by β *errori. 4) 5) 6) Demo of GNG Reference:http://homepages.feis.herts.ac.uk/~nng roup/software.php DBSCAN : Density Based Spatial Clustering of Application with Noise Proposed by Martin Ester, Hans-Peter Kriegel, Jörg Sander and Xiaovei Xui in 1996. Finds clusters starting from estimated density . Two parametres : epsilon(eps ) and minimum points minPts. eps can be estimated. Algorithm : Reference:slides by Francesco Satini Phd Student IMT Comparing GNG & DBSCAN Time Complexity Capability of tackling high dimensional data Perfomance Number of initial parametres Perfomance with moving data Data to be used Mainly design data References: Jim Holmstrm :Master Thesis,Growing Neural Gas-Experiments with GNG-GNG with Utility and Supervised GNG M Ester, HP Kriegel, J Sander, X Xu : A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise Proc. 2nd Int. Conf. on Knowledge Discovery and Data Mining, 1996 Competitive learning:http://homepages.feis.herts.ac.uk/~nngroup/software.p hp www.utdallas.edu/~lkhan/Spring2008G/DBSCAN.ppt B. Fritzke. :A growing neural gas network learns topologies. Jose Alfredo F. Costa and Ricardo S. Oliveira :Cluster Analysis using Growing Neural Gas and Graph Partitioning