Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Data Fusion in Sensor Networks
Asheq Khan
Outline
• Introduction
• Key concepts
• Three schemes
– Cluster based data fusion
– Synchronization among nodes
– Resistance against attacks
• Conclusion
Oct 28, 2004
Asheq Khan
Introduction
• A sensor network comprises of sensor
nodes and a base station.
• Each sensor node is battery powered and
equipped with:
– Integrated sensors
– Data processing capabilities
– Short-range radio communications
• Due to their limited power and shorter
communication range, sensor nodes
perform in-network data fusion.
Oct 28, 2004
Asheq Khan
Data Fusion Process
• A data fusion node collects the
results from multiple nodes.
• It fuses the results with its own
based on a decision criterion.
• Sends the fused data to another
node/base station.
• Advantages:
– Reduces the traffic load.
– Conserves energy of the sensors.
Oct 28, 2004
Asheq Khan
Key Concepts in Data Fusion
• Three questions needs to be
addressed:
• First, at what instance does a node
report a sensed event?
• Second, how does a node fuse
multiple reports into a single one?
• Third, what data fusion architecture
to use?
Oct 28, 2004
Asheq Khan
Reporting
• Periodical reporting: Sensor nodes
periodically send reports to the base
station.
• Base station inquiry response reports: the
BS queries sensors in specific regions for
current sensed information.
• Event triggered reports: The occurrence of
a certain event can trigger reports from
sensors in that particular region.
Oct 28, 2004
Asheq Khan
Fusion Decision
• Voting: the oldest and most widely used
fusion decision method.
• Fusion node arrives at a consensus by a
voting scheme like:
– Majority voting
– Complete Agreement
– Weighted voting
• The popularity of voting arises from its
simplicity and accuracy.
• Other fusion decision algorithms include
probability-based Bayesian Model and
stack generalization.
Oct 28, 2004
Asheq Khan
Fusion Architecture
• Centralized:
– Simplest
– A central processor fuses the reports
collected by all other sensing nodes.
– Advantage: Erroneous report(s) can be
easily detected.
– Disadvantage: inflexible to sensor
changes and the workload is
concentrated at a single point.
Oct 28, 2004
Asheq Khan
Fusion Architecture (2)
• Decentralized :
– Data fusion occurs locally at each node
on the basis of local observations and
the information obtained from
neighboring nodes.
– No central processor node.
– Advantages:
• scalable and tolerant to the addition or loss
of sensing nodes or dynamic changes in the
network.
Oct 28, 2004
Asheq Khan
Fusion Architecture (3)
• Hierarchical:
– Nodes are partitioned into hierarchical
levels.
– The sensing nodes are at level 0 and the
BS at the highest level.
– Reports move from the lower levels to
higher ones.
– Advantage:
• Workload is balanced among nodes
Oct 28, 2004
Asheq Khan
Cluster Based Data Fusion
Oct 28, 2004
Asheq Khan
Problem
• Due to their energy constraints, sensors
need to perform efficient data fusion to
extend the lifetime of the network.
• Lifetime of a sensor network is the
number of rounds of data fusion it can
perform before the first sensor drains out.
• This is known as the “Maximum Lifetime
Data Aggregation” (MLDA) problem.
Oct 28, 2004
Asheq Khan
Goal
• Given: the location & energy of each
sensor and the BS.
• Find an efficient manner to collect &
aggregate reports from the sensors
to the BS.
• [Dasgupta, WCNC’03] propose a
cluster based heuristic (CMLDA) to
solve the problem.
Oct 28, 2004
Asheq Khan
System Model
•
•
•
•
•
•
n sensor nodes(1..n)
Base station(n+1)
Fixed data packet size: k bits
Initial energy of a sensor i: εi
Receive energy, RXi = εelec * k
Transmission energy, TXi,j = εelec *k +
εamp*d2i,j*k
Oct 28, 2004
Asheq Khan
Algorithm
• Two phases.
• Phase 1:
– Sensors are grouped into clusters called
“super-sensors”.
– Each super sensor consists of a minimum no.
of sensors.
– The energy of a super sensor is the sum of the
energy of all the sensors within it.
– Distance between two super sensors is the
maximum distance between two sensors
where, each reside in a different super sensor.
– Apply the MLDA algorithm.
Oct 28, 2004
Asheq Khan
MLDA Algorithm
• ILP is employed to find a nearoptimal admissible flow network.
• Objective: maximize the lifetime of
network (T) under the energy
constraints.
• Generate schedule(s) from the
admissible flow network.
Oct 28, 2004
Asheq Khan
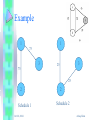
Example
1
1
75
3
75
3
25
25
2
Schedule 1
Oct 28, 2004
2
Schedule 2
Asheq Khan
Algorithm (2)
•
Phase Two:
1.
2.
3.
4.
5.
Initialize {Aggregation Schedule} = Ø
Life Time, T = 0
Choose a Scheduler from phase 1
Initialize Aggregation tree, A with the BS
Visit each super clusters and add the nodes
to the tree such that, the residual energy at
each edge is maximized.
6. Add A to the Aggregation Scheduler
7. Increment T by 1
8. Repeat steps 3-7 until a node drains out.
Oct 28, 2004
Asheq Khan
Comments
• Provides a set of data fusion
schedules that maximize the lifetime
of the network.
• Clustering of nodes reduces the time
needed to solve the ILP.
Oct 28, 2004
Asheq Khan
Synchronization Among Nodes
Oct 28, 2004
Asheq Khan
Problem
• During data fusion, internal nodes at each
level wait for a certain period of time
before they fuse the received reports.
• If nodes at each level wait for the same
period of time then an internal node may
timeout before receiving reports from all
of its children.
• With insufficient reports, the credibility of
a sensed event is questionable.
Oct 28, 2004
Asheq Khan
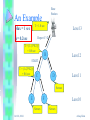
Example
Base Station
Level 3
Report D
TIMEOUT
T = .5 sec
T = .5 sec
B
C
Level 2
Level 1
D
Senses
E
F
Senses
Oct 28, 2004
Level 0
Senses
Asheq Khan
Solution
• An efficient data fusion protocol with
following characteristics:
– Synchronizes the nodes at different
levels.
– Nodes at higher levels wait longer
before fusing data.
– A fixed time period is assigned from the
sensing of an event to the time it is
received by the base station.
– Provide a balance between latency &
accuracy.
Oct 28, 2004
Asheq Khan
Multi-level Fusion Synchronization
(MFS) Protocol
• [Yuan,GLOBECOM’03] propose the
MFS protocol.
• The parameters:
– MAX: time BS waits before fusing the
received data
– Δ: difference in waiting period at
consecutive levels
– K: the distance (in hops) from the sink
Oct 28, 2004
Asheq Khan
Algorithm
• Upon detection of an event, a leaf
node reports to its parent node.
• This triggers the timer of the parent
node.
• Then the parent node sends a START
message to trigger the timer of its
neighboring nodes.
• The timer at a node expires after
(MAX – K*Δ) seconds.
Oct 28, 2004
Asheq Khan
Base
Station
An Example
T = 1.0 sec
Max = 1 sec
Δ = 0.2sec
Level 3
Report C+D
T = (1-(1*0.2))
= 0.8 sec
B
Level 2
START
T = (1-(2*0.2))
= 0.6 sec
C
Level 1
D
Senses
E
F
Senses
Oct 28, 2004
Level 0
Senses
Asheq Khan
Latency
• Best case:
– Assuming:
– START messages do not collide
– No propagation delay in triggering the timer
– MAX
• Worst case:
– Assuming:
– None of the internal nodes receive the START
message
D-1
– L =∑ (MAX – j*Δ) = D*MAX – ((D-1)*D*Δ)/2
j=0
Oct 28, 2004
{D = depth of propagation tree}
Asheq Khan
Setting the parameters
• If the BS knows the depth of the
fusion tree then it can compute the
values of MAX and Δ.
• Otherwise, in a learning phase, the
BS queries the sensors with different
values of MAX and Δ.
• And adjust the values based on the
reports credibility and application
requirements.
Oct 28, 2004
Asheq Khan
Result: No. of reports vs. Δ
MAX=1.2s
•Similar performance with both BFS (balanced tree) & ODMRP
(unbalanced tree).
Very small or large Δ performs worst.
Oct 28, 2004
Asheq Khan
Result(2): Latency vs. Δ
•Small Δ incurs large waiting period whereas large Δ incurs small waiting
period.
In BFS, latency for each Δ < 2* MAX.
Oct 28, 2004
Asheq Khan
Pros and Cons
• Pros:
– Synchronizes nodes at different levels.
– MAX and Δ can be tuned
• Cons:
– Reports arriving after timeout is
discarded.
– Collision if START messages will cause
a latency greater than MAX.
Oct 28, 2004
Asheq Khan
Resistance Against Attacks
Oct 28, 2004
Asheq Khan
Problem
• Previously, it is assumed that the nodes
conducting the data fusion are secured.
• But, a malicious data fusion node can
send bogus reports to the BS.
• The BS is incapable of detecting the
bogus information since the sensor nodes
do not directly send the reports to the BS.
Oct 28, 2004
Asheq Khan
Witness Based Data Assurance
• [Du GLOBECOM’03] present a witness
based scheme to ensure that the BS
accepts only valid data fusion results.
• To prove the validity of a report, the fusion
node is required to provide proofs from
several witnesses.
• A witness is a node that also performs
data fusion but does not send its report to
the BS.
Oct 28, 2004
Asheq Khan
Algorithm
1.
2.
3.
4.
Let there be m witnesses + 1 data fusion node.
Each witness wi share an unique key with the
BS, ki
After receiving reports from the sensor nodes,
each witness performs data fusion and obtains
the result ri.
It then sends a MAC (Message Authentication
Code) to the data fusion node:
MACi = MAC(ri, wi, ki)
5.
6.
7.
The data fusion node computes its result and
sends its MAC key with its witnesses to the BS.
The BS exercises a voting scheme to determine
the validity of the report.
If the report is corrupted, the BS discards it and
polls one of the witness nodes for the correct
report.
Oct 28, 2004
Asheq Khan
Voting Schemes
• The Base Station can employ two
voting schemes to determine the
validity of the fused report.
– m+1 out of m+1: the result is valid if
supported by all the witnesses.
– n out of m+1: (1=<n<=m+1) the result is
valid if supported by at least n witness.
Oct 28, 2004
Asheq Khan
m+1 out of m+1 voting scheme
After receiving all the MAC’s from the witness
nodes, the data fusion node computes:
1.
•
2.
3.
4.
5.
MACF = MAC(SF,F,KF, MAC1 xor …xor MACm)
F then sends (SF,F, w1,.., wm, MACF) to the BS.
The BS then computes the MACi = MAC(SF, wi,
ki) for each w
Finally computes:
MAC’F = MAC(SF,F,KF, MAC1 xor …xor MACm)
If (MACF = MAC’F) then accepts the report
Oct 28, 2004
Asheq Khan
n out of m+1 voting scheme
•
•
•
•
The disadvantage of the previous
approach is that a corrupt witness node
can always send invalid MAC and
achieve Denial of service attack.
To prevent that, F should not merge all
the MACi’s but instead forward them all:
R = (SF,F, MACF, w1, MAC1,..wm,MACm)
If at least n out of m+1MAC’s match, then
the result SF is accepted.
Otherwise the result is dropped.
Oct 28, 2004
Asheq Khan
Pros & Cons
• Pros
– Provides a scheme that ensures that
only valid reports are accepted by the
BS.
• Cons
– Redundancy: multiple copies of similar
reports are fused by the witnesses.
– No energy efficient
Oct 28, 2004
Asheq Khan
Conclusion
• This talk attempted to give an overview of
the data fusion process in sensor
networks.
• Different data fusion architectures, voting
schemes architecture are presented.
• Three important aspects of efficient data
fusion are presented: energy efficiency,
synchronization among sensors and
resistance against attacks.
• Obviously, an ideal data fusion will be one
that can incorporate all the three
characteristics.
Oct 28, 2004
Asheq Khan
References
• K. Dasgupta, K. Kalpakis and P. Namjoshi, “An Efficient
Clustering-based Heuristic for Data Gathering and
Aggregation in Sensor Networks,” IEEE WCNC, 2003.
• K. Kalpakis, K. Dasgupta and P. Namjoshi, “Maximum
Lifetime Data Gathering and Aggregation in Wireless
Sensor Networks,” IEEE ICN, 2002.
• Wei Yuan, Srikanth V. Krishnamurthy, and Satish K. Tripathi,
“Synchronization of Multiple Levels of Data Fusion in
Wireless Sensor Networks,” In Proceedings of GLOBECOM,
2003.
• W. Du, J. Deng, Y. S. Han and P. K. Varshney, “A WitnessBased Approach for Data Fusion Assurance in Wireless
Sensor Networks,” In Proceedings of GLOBECOM, 2003.
Oct 28, 2004
Asheq Khan