Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
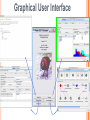
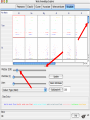
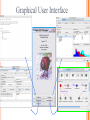
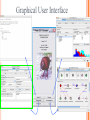
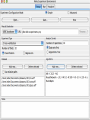
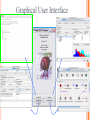
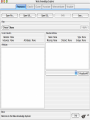
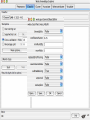
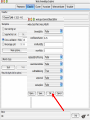
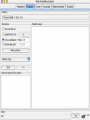
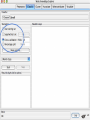
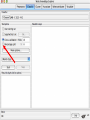
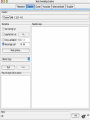
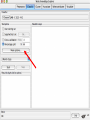
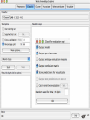
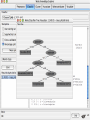
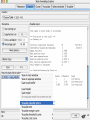
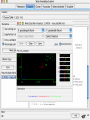
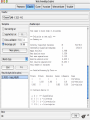
Modelli di e-business e business intelligence Cdl Ingegneria Informatica INTRODUZIONE AL WEKA Umberto Panniello DIMEG, Politecnico di Bari KNOWLEDGE DISCOVERY IN DB DAI DATI ALL’INFORMAZIONE La società produce una grossa quantità di dati fonti: business, science, medicina, economia, geografia, ambiente, sports, … Potenzialmente sono fonti di grande valore Servono tecniche per estrarre informazione interessante automaticamente dai dati Cosa vuol dire interessante? Nuova Implicita Potenzialmente utile Comprensibile WEKA: THE BIRD WEKA: IL SOFTWARE E’ un software di Machine learning/data mining scritto in Java Utilizzato nella ricerca, nella didattica, e nelle applicazioni “Data Mining” by Witten & Frank Principali caratteristiche: Set completo di strumenti per il pre-processing, algoritmi di apprendimento e metodi di valutazione Graphical user interfaces (incl. data visualization) Ambiente per confrontare i risultati degli algoritmi Graphical User Interface EXPLORER Comprende le seguenti funzioni Pre-process Classify Cluster Associate Select attributes Visualize EXPLORER: PRE-PROCESSING Possono essere importati dati in input di diversi estensioni: ARFF, CSV, C4.5, binary I dati possono essere letti da un URL o da un data base SQL Gli strumenti di pre processing sono chiamati “filtri” WEKA contiene filtri per: Discretization, normalization, resampling, attribute selection, transforming and combining attributes I FILTRI Servono a “trasformare” i dati. Si dividono in: Unsupervised (no conosco classe) Supervised (conosco classe) Inoltre, si distingue tra: Attribute filters Instance filters ESEMPIO DI INPUT Y=F(X) Columns = Attributi Raw Istanze Spectacle prescription Astigmatism Young Young Young Young Young Young Young Young Pre-presbyopic Pre-presbyopic Pre-presbyopic Pre-presbyopic Pre-presbyopic Pre-presbyopic Pre-presbyopic Pre-presbyopic Presbyopic Presbyopic Presbyopic Presbyopic Presbyopic Presbyopic Presbyopic Presbyopic Myope Myope Myope Myope Hypermetrope Hypermetrope Hypermetrope Hypermetrope Myope Myope Myope Myope Hypermetrope Hypermetrope Hypermetrope Hypermetrope Myope Myope Myope Myope Hypermetrope Hypermetrope Hypermetrope Hypermetrope No No Yes Yes No No Yes Yes No No Yes Yes No No Yes Yes No No Yes Yes No No Yes Yes Tear production rate Reduced Normal Reduced Normal Reduced Normal Reduced Normal Reduced Normal Reduced Normal Reduced Normal Reduced Normal Reduced Normal Reduced Normal Reduced Normal Reduced Normal Recommended lenses None Soft None Hard None Soft None hard None Soft None Hard None Soft None None None None None Hard None Soft None None Class Age EXPLORER: CLASSIFIERS Classifiers: sono modelli per predire quantità numeriche o nominali Algoritmi implementati sono: Decision trees and rules, instance-based classifiers, support vector machines, multi-layer perceptrons (reti neurali), logistic regression,… EXPLORER: CLUSTERING I “clusterers” creano insieme di istanze tali che: le istanze dello stesso cluster sono simili tra loro le istanze di cluster diversi sono dissimili alta somiglianza intra-classe bassa somiglianza inter-classe Alcuni algoritmi implementati sono: k-Means, EM, Cobweb, X-means, FarthestFirst EXPLORER: ASSOCIATIONS Permettono di trovare associazioni di dipendenza statistica fra attributi Es: Sia data la regola: compra(x,”pannolino”) => compra(x,”birra”) Supporto: la percentuale di acquisti che comprendono sia i pannolini che la birra. Confidenza: tra gli acquisti che includono i pannolini, la percentuale di quelli che includono anche la birra. EXPLORER: ATTRIBUTE SELECTION Algoritmi che permettono di investigare quali sottoinsiemi di attributi hanno maggiore capacità predittiva Tali algoritmi constano di 2 parti: Un metodo di valutazione: correlation-based, wrapper, information gain, chi-squared, … Un metodo di ricerca: best-first, forward selection, random, exhaustive, genetic algorithm, ranking EXPLORER: DATA VISUALIZATION WEKA permette di visualizzare singoli attributi (1-d) e coppie di attributi (2-d) “Jitter” per aumentare il grado di dettaglio delle rappresenazioni dei dati Funzioni di “Zoom-in” function Selezione dei dati da grafico Graphical User Interface THE KNOWLEDGE FLOW GUI Permette di impostare un esperimento in maniera grafica Permette di unire le diverse funzioni dell’explorer graficamente “data input” -> “filter” -> “classifier” -> “evaluator” I Layout possono essere salvati e caricati successivamente Graphical User Interface Graphical User Interface CONFUSION MATRIX Predicted class yes Actual class TP= TP TP + FN FP= FP FP + TN no yes true positive no false negative false positive true negative OverallSuc cessRate= TP + TN TP + TN + FP + FN TP + TN ErrorRate= 1 TP + TN + FP + FN PRECISION, RECALL AND F-MEASURE number of documents retrieved that are relevant Recall = total number of documents that are relevant number of documents retrieved that are relevant Precision = total number of documents that are retrieved 2 x Recall x Precision F - Measure = Recall + Precision