Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
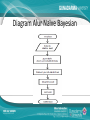
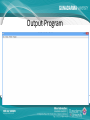
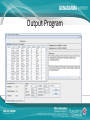
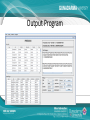
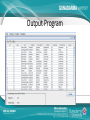
IMPLEMENTASI DATA MINING UNTUK MEMPREDIKSI DATA NASABAH BANK DALAM PENAWARAN DEPOSITO BERJANGKA DENGAN MENGGUNAKAN ALGORITMA KLASIFIKASI NAIVE BAYES Nama NPM Jurusan Pembimbing : Muhammad Rizki : 54410806 : Teknik Informatika : Dr. Ana Kurniawati, ST.,MMSI. Latar Belakang • Sebuah bank mempunyai program layanan yang banyak untuk ditawarkan kepada calon nasabah dan nasabah bank tersebut. Salah satu layanan yang cukup di kenal adalah deposito berjangka. Bagian marketing bank melakukan penawaran deposito berjangka kepada nasabah dengan menghubungi nasabah satu persatu via telepon. Namun nasabah dengan kriteria seperti apa yang ingin menggunakan layanan deposito. Bank mempunyai data yang sangat banyak untuk mengelola data tersebut data mining dianggap sebagai solusi. • Teknik yang digunakan adalah klasifikasi dengan menggunakan algoritma naive bayes. Aturan bayes digunakan karena mempunyai asumsi yang kuat bahwa atribut yang digunakan adalah independen. Rumusan Masalah • Bagaimana proses merancang dan membangun aplikasi data mining dengan menggunakan data nasabah untuk memprediksi apakah nasabah sebuah bank mau menggunakan layanan deposito berjangka atau tidak. • Bagaimana hasil pengujian data training terhadap data testing serta tingkat akurasi yang di dapat dari pengujian dengan menggunakan algoritma naive bayes. • Bagaimana hasil prediksi pola data nasabah yang setuju dengan penawaran deposito berjangka dengan menggunakan algoritma naive bayes. Batasan Masalah • • • Bagaimana pembuatan aplikasi data mining dengan menggunakan data nasabah untuk memprediksi apakah nasabah sebuah bank mau menggunakan layanan deposito berjangka atau tidak dengan menggunakan bahasa pemrograman Java dan basis data Mysql. Data set yang digunakan di dapat dari http://archive.ics.uci.edu/. Data tersebut adalah data yang didapat dari bagian marketing sebuah bank di portugal, data tersebut di donasi pada tanggal 14 februari 2012 oleh S. Moro, P. Cortez and P. Rita. Jumlah record yang di peroleh sebanyak 4521 record. Pada data tersebut bagian marketing juga menghubungi nasabah yang sama lebih dari 1 kali sebagai syarat di perlukan. Pada penulisan ini tidak dibahas tentang penggunaan aplikasi pada Java mobile atau smartphone dan java web, sebab aplikasi ini hanya untuk digunakan pada perangkat komputer dan sejenisnya. Pada penulisan dan aplikasi ini proses pengujian data testing tidak dapat dilakukan secara menyeluruh namun harus satu persatu atau secara manual. Tujuan Penulisan • Tujuan dari penelitian ini adalah membuat aplikasi data mining untuk memprediksi data nasabah dalam penawaran deposito berjangka dengan menggunakan algoritma naive bayes. Diharapkan aplikasi ini dapat membantu bagian marketing sebuah bank untuk mengetahui apakah suatu nasabah bank mau menerima penawaran deposito berjangka atau tidak serta berapa presentasi yang dihasilkan untuk yang menerima deposito dan tidak. Data Mining Data minig adalah proses yang menggunakan statistik, matematika, kecerdasan buatan, dan mesin pembelajaran untuk mengekstrasi dan mengidentifikasi informasi yang bermanfaat dan terakait dari berbagai database besar(Turban, dkk. 2005) Pengelompokan Data Mining • • • • • • (Larose, 2005) Deskripsi Klasifikasi Estimasi Prediksi Clustering Asosiasi Tahapan Data Mining • • • • • • • Pembersihan Data (Cleaning) Integrasi Data Seleksi Data Transformasi Data Proses Mining Evaluasi Pola Presentasi Pengetahuan Data • Data Training • Data Testing • Data Target Algoritma Naïve Bayesian HMAP HMAP ( Hypothesis Maximum AppropriProbability ) adalah diartikan mencari probabilitas tersebar dari semua instance pada attribute atau semua kemungkinan keputusan. HMAP dapat dirumuskan sebagai berikut : hMAP = arg max P(x |h) p(h). Distribusi Frekuensi Kelompok Distribusi frekuensi adalah susunan data menurut kelas-kelas interval tertentu atau menurut kategori tertentu dalam sebuah daftar. Daftar distribusi frekuensi dapat memudahkan penyajian data serta memberikan potret yang lebih jelas berkaitan dengan distribusi data. Distribusi Frekuensi Kelompok Arsitektur Sistem Analisis Kebutuhan Data • Data Training dan Data Testing. Data ini akan digunakan sebagai proses pengujian, berupa data nasabah bank yang sebelumnya sudah dihubungi pihak marketing dan memiliki hasil ya dan tidak. Persentase pembagian data set menjadi data training dan testing sebenarnya tidak ada aturannya namun berdasarkan salah satu perusahaan besar yaitu microsoft melakukan pengujian model dengan membagi data set menjadi 70% untuk data training dan 30% data testing. • Data Target. Data ini merupakan data nasabah yang belum memiliki label atau tujuan. Setelah proses mining data ini akan memiliki kelas berdasarkan tabel probabilitas yang diperoleh dari data set. Perancangan Data Set • • • Data yang digunakan untuk penelitian ini adalah data yang bersifat open source atas donasi S. Moro, P. Cortez dan P. Rita pada tahun 2012. Data didapat dari sebuah situs data set yaitu http://archive.ics.uci.edu/. Jumlah record yang ada pada data set sebanyak 4521 record. Data ini adalah data nasabah pada sebuah bank di portugal namun data ini akan di sesuaikan untuk dapat digunakan di indonesia maka data akan mengalami seleksi data. Atribut data yang digunakan adalah age(usia nasabah), job(pekerjaan nasabah), marital(status pernikahan nasabah), education(pendidikan terakhir nasabah), contact(jenis komunikasi untuk menghubungi nasabah), previous(pernah dihubungi sebelumnya oleh bagian marketing), postcome(hasil dari menghubungi nasabah sebelumnya) dan class(atribut tujuan). Struktur Navigasi Use Case Diagram Activity Diagram Class Diagram Diagram Alur Naïve Bayesian Output Program Output Program Output Program Output Program Output Program Output Program Output Program Hasil Pengujian • Hasil pengujian adalah hasil pengujian model data training terhadap data testing. Dari hasil pengujian dengan menggunakan 1321 record pada data testing di dapat • Hasil Akurat = 1173 record • Hasil Tidak Akurat = 148 record • Menghitung akurasi = (jumlah data benar/banyak data)*100% • (1173/1321) *100% = 88.79% • Menghitung Kesalahan = 100- hasil akurasi • 100-88.79 = 11.21% Hasil Prediksi • Hasil prediksi data target yang berisikan 100 record. di dapatkan hasil. • 97 record di prediksi tidak akan menggunakan deposito berjangka. • 3 record di prediksi akan menggunakan deposito berjangka. Pola Prediksi Nasabah Setuju Kesimpulan • Pada pengujian model data training terhadapa data testing di dapat tingkat akurasi model data sebesar 88%. Dengan tingkat akurasi yang lebih dari 50% dapat dikatakan permodelan data sudah dapat dikatakan cukup baik. • Melakukan prediksi terhadap data target yang belum memiliki output. Di dapat hasil prediksi 3 nasbah dari 100 data yang di prediksi akan menggunakan deposito berjangka sedangkan sisanya tidak akan menggunakan deposito berjangka. Di dapatnya hasil prediksi bagian marketing mengetahui nasabah seperti apa yang akan setuju menggunakan deposito berjangka dan tidak Terima Kasih