Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
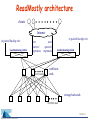
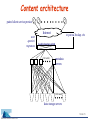
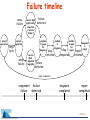
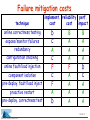
Why do Internet services fail, and what can be done about it? David Oppenheimer, Archana Ganapathi, and David Patterson Computer Science Division University of California at Berkeley IBM Conference on Proactive Problem Prediction, Avoidance and Diagnosis April 28, 2003 Motivation • Internet service availability is important – email, instant messenger, web search, e-commerce, … • User-visible failures are relatively frequent – especially if use non-binary definition of “failure” • To improve availability, must know what causes failures – know where to focus research – objectively gauge potential benefit of techniques • Approach: study failures from real Internet svcs. – evaluation includes impact of humans & networks Slide 2 Outline • Describe methodology and services studied • Identify most significant failure root causes – source: type of component – impact: number of incidents, contribution to TTR • Evaluate HA techniques to see which of them would mitigate the observed failures • Drill down on one cause: operator error • Future directions for studying failure data Slide 3 Methodology • Obtain “failure” data from three Internet services – two services: problem tracking database – one service: post-mortems of user-visible failures Slide 4 Methodology • Obtain “failure” data from three Internet services – two services: problem tracking database – one service: post-mortems of user-visible failures • We analyzed each incident – failure root cause » hardware, software, operator, environment, unknown – type of failure » “component failure” vs. “service failure” – time to diagnose + repair (TTR) Slide 5 Methodology • Obtain “failure” data from three Internet services – two services: problem tracking database – one service: post-mortems of user-visible failures • We analyzed each incident – failure root cause » hardware, software, operator, environment, unknown – type of failure » “component failure” vs. “service failure” – time to diagnose + repair (TTR) • Did not look at security problems Slide 6 Comparing the three services characteristic hits per day # of machines front-end node architecture back-end node architecture period studied # component failures # service failures Online ~100 million ~500 @ 2 sites custom s/w; Solaris on SPARC, x86 Network Appliance filers 7 months 296 ReadMostly ~100 million > 2000 @ 4 sites custom s/w; open-source OS on x86 custom s/w; open-source OS on x86 6 months N/A Content ~7 million ~500 @ ~15 sites custom s/w; open-source OS on x86; custom s/w; open-source OS on x86 3 months 205 40 21 56 Slide 7 Outline • Describe methodology and services studied • Identify most significant failure root causes – source: type of component – impact: number of incidents, contribution to TTR • Evaluate HA techniques to see which of them would mitigate the observed failures • Drill down on one cause: operator error • Future directions for studying failure data Slide 8 Failure cause by % of service failures Online unknown 12% Content hardware 10% unknown 22% hardware 2% software 25% software 25% operator 33% network 20% ReadMostly unknown 14% operator 19% operator 36% network 15% software 5% network 62% Slide 9 Failure cause by % of TTR Online Content unknown hardware 1% 6% software 17% software 6% network 19% network 1% operator 75% operator 76% ReadMostly operator 3% network 97% Slide 10 Most important failure root cause? • Operator error generally the largest cause of service failure – even more significant as fraction of total “downtime” – configuration errors > 50% of operator errors – generally happened when making changes, not repairs • Network problems significant cause of failures Slide 11 Related work: failure causes • Tandem systems (Gray) – 1985: Operator 42%, software 25%, hardware 18% – 1989: Operator 15%, software 55%, hardware 14% • VAX (Murphy) – 1993: Operator 50%, software 20%, hardware 10% • Public Telephone Network (Kuhn, Enriquez) – 1997: Operator 50%, software 14%, hardware 19% – 2002: Operator 54%, software 7%, hardware 30% Slide 12 Outline • Describe methodology and services studied • Identify most significant failure root causes – source: type of component – impact: number of incidents, contribution to TTR • Evaluate HA techniques to see which of them would mitigate the observed failures • Drill down on one cause: operator error • Future directions for studying failure data Slide 13 Potential effectiveness of techniques? technique post-deployment correctness testing* expose/monitor failures* redundancy* automatic configuration checking post-deploy. fault injection/load testing component isolation* pre-deployment fault injection/load test proactive restart* pre-deployment correctness testing* * indicates technique already used by Online Slide 14 Potential effectiveness of techniques? technique failures avoided / mitigated post-deployment correctness testing* expose/monitor failures* redundancy* automatic configuration checking post-deploy. fault injection/load testing component isolation* pre-deployment fault injection/load test proactive restart* pre-deployment correctness testing* 26 12 9 9 6 5 3 3 2 (40 service failures examined) Slide 15 Outline • Describe methodology and services studied • Identify most significant failure root causes – source: type of component – impact: number of incidents, contribution to TTR • Evaluate existing techniques to see which of them would mitigate the observed failures • Drill down on one cause: operator error • Future directions for studying failure data Slide 16 Drilling down: operator error Why does operator error cause so many svc. failures? % of component failures resulting in service failures 50% Content Online 25% 24% 21% 19% 6% operator software network hardware 19% 3% operator software network hardware Existing techniques (e.g., redundancy) are minimally effective at masking operator error Slide 17 Drilling down: operator error TTR Why does operator error contribute so much to TTR? Online Content unknown hardware 1% 6% software 17% software 6% network 19% network 1% operator 76% operator 75% Detection and diagnosis difficult because of non-failstop failures and poor error checking Slide 18 Future directions • Correlate problem reports with end-to-end and per-component metrics – – – – retrospective: pin down root cause of “uknown” problems introspective: detect and determine root cause online prospective: detect precursors to failure or SLA violation include interactions among distributed services • Create a public failure data repository – standard failure causes, impact metrics, anonymization – security (not just reliability) – automatic analysis (mine for detection, diagnosis, repairs) • Study additional types of sites – transactional, intranets, peer-to-peer • Perform controlled laboratory experiments Slide 19 Conclusion • Operator error large cause of failures, downtime • Many failures could be mitigated with – better post-deployment testing – automatic configuration checking – better error detection and diagnosis • Longer-term: concern for operators must be built into systems from the ground up – make systems robust to operator error – reduce time it takes operators to detect, diagnose, and repair problems » continuum from helping operators to full automation Slide 20 Willing to contribute failure data, or information about problem detection/diagnosis techniques? [email protected] Backup Slides Slide 22 Online architecture clients (400 total) Internet to second site user queries/ responses (8) Load-balancing switch web proxy cache (8) (48 total) ~65K users; email, newsrc, prefs, etc. (6 total) stateful services (e.g. mail, news) (50 total) news article storage Filesystem-based storage (NetApp) Database stateless services (e.g. content portals) storage of customer records, crypto keys, billing info, etc. Slide 23 ReadMostly architecture clients Internet to paired backup site Load-balancing switch user queries/ responses user queries/ responses (O(10) total)) to paired backup site Load-balancing switch web frontends storage back-ends (O(1000) total) Slide 24 Content architecture paired client service proxies Internet user queries/ responses to paired backup site Load-balancing switch (14 total) metadata servers (100 total) data storage servers Slide 25 Operator case study #1 • Symptom: postings to internal newsgroups are not appearing • Reason: news email server drops postings • Root cause: operator error – username lookup daemon removed from news email server • Lessons – operators must understand high-level dependencies and interactions among components – online testing » e.g., regression testing after configuration changes – better exposing failures, better diagnosis, … Slide 26 Operator case study #2 • Symptom: chat service stops working • Reason: service nodes cannot connect to (external) chat service • Root cause: operator error – operator at chat service reconfigured firewall; accidentally blocked service IP addresses • Lessons – same as before, but must extend across services » operators must understand high-level dependencies and interactions among components » online testing » better error reporting and diagnosis – cross-service human collaboration important Slide 27 Improving detection and diagnosis • Understanding system config. and dependencies – operator mental model should match changing reality – including across administrative boundaries • Enabling collaboration – among operators within and among service • Integration of historical record – past configs., mon. data, actions, reasons, results (+/-) – need structured expression of sys. config, state, actions » problem tracking database is unstructured version • Statistical/machine learning techniques to infer misconfiguration and other operator errors? Slide 28 Reducing operator errors • Understanding configuration (previous slide) • Impact analysis • Sanity checking – built-in sanity constraints – incorporate site-specific or higher-level rules? • Abstract service description language – specify desired system configuration/architecture – for checking: high-level config. is form of semantic redundancy – enables automation: generate low-level configurations from high-level specification – extend to dynamic behavior? Slide 29 The operator problem • Operator largely ignored in designing server systems – operator assumed to be an expert, not a first-class user – impact: causes failures & extends TTD and TTR for failures – more than 15% of problems tracked at Content pertain to administrative/operations machines or services • More effort needed in designing systems to – prevent operator error – help humans detect, diagnose, repair problems due to any cause • Hypothesis: making server systems human-centric – reduce incidence and impact of operator error – reduce time to detect, diagnose, and repair problems • The operator problem is largely a systems problem – make the uncommon case fast, safe, and easy Slide 30 Failure location by % of incidents Online 18% net 3% back-end 2% unk. Content 4% unk. 18% net 77% front-end 11% back-end ReadMostly 9% unk. 10% back-end 66% front-end 81% net Slide 31 Summary: failure location • For two services, front-end nodes largest location of service failure incidents • Failure location by fraction of total TTR was service-specific • Need to examine more services to understand what this means – e.g., what is dependence between # of failures and # of components in each part of service Slide 32 Operator case study #3 • Symptom: problem tracking database disappears • Reason: disk on primary died, then operator re-imaged backup machine • Root cause: hardware failure; operator error? • Lessons – operators must understand high-level dependencies and interactions among components » including dynamic system configuration/status • know when margin of safety is reduced • hard when redundancy masks component failures – minimize window of vulnerability whenever possible – not always easy to define what is a failure Slide 33 Difficulties with prob. tracking DB’s • Forms are unreliable – incorrectly filled out, vague categories, single cause, … – we relied on operator narrartives • Only gives part of the picture » better if correlated with per-component logs and end-user availability » filtering may skew results • operator can cover up errors before manifests as a (new) failure => operator failure % is underestimate » only includes unplanned events Slide 34 What’s the problem? • Many, many components, with complex interactions • Many failures – 4-19 user-visible failures per month in “24x7” services • System in constant flux • Modern services span administrative boundaries • Architecting for high availability, performance, and modularity often hides problems – layers of hierarchy, redundancy, and indirection => hard to know what components involved in processing req – asynchronous communications => may have no explicit failure notification (if lucky, a timeout) – built-in redundancy, retry, “best effort” => subtle performance anomalies instead of fail-stop failures – each component has its own low-level configuration file/mechanism => misunderstood config, wrong new config (e.g., inconsistent) Slide 35 Failure timeline comp. failure normal operation comp. fault service QoS significantly impacted (“service failure”) problem in queue for diagnosis normal operation comp. failure failure detected service QoS impacted negligibly diag. initiated problem in diagnosis problem in queue for repair diag. completed component in repair repair initiated failure detected repair completed component failure failure detected diagnosis completed repair completed Slide 36 Failure mitigation costs technique online correctness testing expose/monitor failures redundancy configuration checking online fault/load injection component isolation pre-deploy. fault/load inject proactive restart pre-deploy. correctness test implement. reliability perf. cost cost impact D C A C F C F A D B A A A F A A A A B A A A D C A A A Slide 37 Failure cause by % of TTR 17% node sw 1% node unk 6% node sw Online Content 19% net 6% node hw 1% net 76% operator 75% operator 3% operator ReadMostly 97% net Slide 38 Failure location by % of TTR Online (FE:BE 100:1) 14% 69% Content (FE:BE 0.1:1) 3% 61% 36% 17% ReadMostly (FE:BE 1:100) 1% front-end 99% back-end network Slide 39 Geographic distribution 1. Online service/portal 2. Global storage service 3. High-traffic Internet site Slide 40