Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Peer-to-Peer Networks
Hongli Luo
CEIT, IPFW
Topics
Application architecture
P2P file sharing
P2P networks:
•
•
•
•
Napster
Gnutella
KaAzA
Bittorrent
Application architectures
Client-server
Peer-to-peer (P2P)
Hybrid of client-server and P2P
Client-server architecture
server:
always-on host
permanent IP address
server farms for scaling
clients:
client/server
communicate with server
may be intermittently
connected
may have dynamic IP
addresses
do not communicate directly
with each other
Client-server architecture
Applications based on client-server architecture are
infrastructure intensive.
Service provider must pay connection and bandwidth
costs for transmission of data over the Internet
Applications
Search engines – Google
Web-based e-mail – Yahoo Mail
Social networking – MySpace and Facebook
Video sharing – YouTube
Amazon? - use cloud computing
Server farm
Used when a single server is incapable of keeping up with all
the requests from clients
A cluster of hosts is used to create a powerful virtual server
P2P architecture
no always-on server
arbitrary end systems directly
communicate
peers are intermittently
connected and change IP
addresses
Peers are not owned by
service provider
Highly scalable but difficult to
manage
peer-peer
P2P architecture
Applications
File distribution – BitTorrent
File search/sharing – eMule and LimeWire
Internet telephony – Skype
IPTV – PPLive
Advantages
Self-scalability
Cost effective – requires no significant server infrastructure
and server bandwidth
Disadvantage
Difficult to manage
security
Hybrid of client-server and P2P
Skype
voice-over-IP P2P application
centralized server: finding address of remote party:
client-client connection: direct (not through server)
Instant messaging
chatting between two users is P2P
• User-to-user messages are sent directly between user hosts
without passing through intermediate servers
centralized service: client presence detection/location
• user registers its IP address with central server when it
comes online
• user contacts central server to find IP addresses of
buddies
• Servers are used to track IP addresses of USERS
Processes communicating
Process: program running within a host.
within same host, two processes communicate using interprocess communication (defined by OS).
processes in different hosts communicate by exchanging
messages
P2P: applications with P2P architectures have client processes &
server processes
In P2P file sharing, peer downloading the file is client , the
peer uploading the file is server.
Client process: process that initiates communication
Server process: process that waits to be contacted
P2P file sharing
Problem: How to distribute a large file from a single
server to a large number of hosts?
Solutions
Client-server file distribution
• the server send a copy of the file to each of the hosts
• Burden on the server and server bandwidth
P2P file distribution
• each peer can redistribute any portion of the file it has received
to any other peers
• The most popular protocol BitTorrent – consists of 30% of the
Internet backbone traffic
Server Distributing a Large File
Assumptions
Internet core has abundant bandwidth
All of the bottlenecks are in network access
The server and clients are not participating in any other
network applications
Distribution time D – the time it takes to get a copy of
the file to all N peers.
Server Distributing a Large File
Server sending a large file to N receivers
Large file with F bits
Single server with upload rate us
Download rate di for receiver i
Server transmission to N receivers
Server needs to transmit NF bits
Takes at least NF/us time
Receiving the data
Slowest receiver receives at rate dmin= mini{di}
Takes at least F/dmin time
Distribution time for client-server
Dcs >= max{NF/us, F/dmin}
Speeding Up the File Distribution
Distribution time increases linearly with the number of
peers N.
Increase the upload rate from the server
Higher link bandwidth at the one server
Multiple servers, each with their own link
Requires deploying more infrastructure
Alternative: have the receivers help
Receivers get a copy of the data
And then redistribute the data to other receivers
To reduce the burden on the server
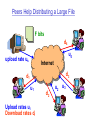
Peers Help Distributing a Large File
F bits
d4
u4
upload rate us
Internet
d3
d1
u1
Upload rates ui
Download rates di
d2
u2
u3
Peers Help Distributing a Large File
Start with a single copy of a large file
Large file with F bits and server upload rate us
Peer i with download rate di and upload rate ui
Two components of distribution latency
Server must send each bit: min time F/us
Slowest peer receives each bit: min time F/dmin
Total upload time using all upload resources
Total number of bits: NF
Total upload bandwidth us + sumi(ui)
Distribution time for peer-2-peer
Dp2p>= max{F/us, F/dmin, NF/(us+sumi(ui))}
Comparing Client-server, P2P architectures
assumes that all peers have the same upload rate u
F/u =1 hour, us = 10u, dmin>=us
The minimum distribution time is less than 1 hour for any number of peers N.
Minimum Distribution Time
3.5
P2P
Client-Server
3
2.5
2
1.5
1
0.5
0
0
5
10
20
15
N
25
30
35
Comparing the Two Models
Download time
Client-server: Dcs = max{NF/us, F/dmin}
Peer-to-peer:
Dp2p = max{F/us, F/dmin, NF/(us+sumi(ui))}
assume each peer redistribute a bit as soon as it receives
the bit
Peer-to-peer is self-scaling
Much lower demands on server bandwidth
Distribution time grows only slowly with N
But…
Peers may come and go
Peers need to find each other
Peers need to be willing to help each other
P2P file sharing
Example
Alice runs P2P client
application on her notebook
computer
intermittently connects to
Internet; gets new IP
address for each connection
asks for “Hey Jude”
application displays other
peers that have copy of Hey
Jude.
Alice chooses one of the
peers, Bob.
file is copied from Bob’s PC
to Alice’s notebook
while Alice downloads, other
users uploading from Alice.
Alice’s peer is both a client
and a transient server.
All peers are servers = highly
scalable!
Challenges of Peer-to-Peer
Peers come and go
Peers are intermittently connected
May come and go at any time
Or come back with a different IP address
How to locate the relevant peers?
Peers that are online right now
Peers that have the content you want
How to motivate peers to stay in system?
Why not leave as soon as download ends?
Why bother uploading content to anyone else?
Locating the Relevant Peers
Mapping of information to host locations
File-sharing system: file tracking, map file to IP of the peer
Instant messaging : presence tracking, map username to IP
Three main approaches for indexing and searching
files
Central directory (Napster)
Query flooding (Gnutella)
Hierarchical overlay (Kazaa, modern Gnutella)
Design goals
Scalability
Simplicity
Robustness
Plausible deniability
Peer-to-Peer Networks: Napster
Napster history: the rise
January 1999: Napster version 1.0
May 1999: company founded
December 1999: first lawsuits
2000: 80 million users
Napster history: the fall
Mid 2001: out of business due to lawsuits
Mid 2001: dozens of P2P alternatives that were harder to
touch, though these have gradually been constrained
2003: growth of pay services like iTunes
Napster history: the resurrection
2003: Napster name/logo reconstituted as a pay service
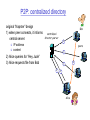
P2P: centralized directory
original “Napster” design
1) when peer connects, it informs
central server:
Bob
centralized
directory server
1
IP address
content
peers
1
2) Alice queries for “Hey Jude”
3) Alice requests file from Bob
3
1
2
1
Alice
Napster Technology: Directory Service
User installing the software
Download the client program
Register name, password, local directory, etc.
Client contacts Napster (via TCP)
Provides a list of music files it will share
Napster’s central server updates the directory
Client searches on a title or performer
Napster identifies online clients with the file
and provides IP addresses
Client requests the file from the chosen supplier
Supplier transmits the file to the client
Both client and supplier report status to Napster
Napster Technology: Properties
Server’s directory continually updated
Always know what music is currently available
Point of vulnerability for legal action
Peer-to-peer file transfer
No load on the server
Plausible deniability for legal action (but not enough)
Proprietary protocol
Login, search, upload, download, and status operations
No security: cleartext passwords and other vulnerability
Bandwidth issues
Suppliers ranked by apparent bandwidth & response time
Napster: Limitations with Centralized Directory
single point of failure
performance bottleneck
copyright infringement: “target”
of lawsuit is obvious
Later P2P systems were more
distributed
Gnutella went to the other
extreme
file transfer is decentralized,
but locating content is
highly centralized
Peer-to-Peer Networks: Gnutella
Gnutella history
2000: J. Frankel &
T. Pepper released
Gnutella
Soon after: many
other clients (e.g.,
Limewire)
2001: protocol
enhancements, e.g.,
“ultrapeers”
Query flooding
Join: contact a few nodes
to become neighbors
Search: ask neighbors,
who ask their neighbors
Fetch: get file directly from
another node
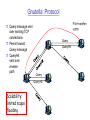
Gnutella: Query Flooding
Fully distributed
No central server
Many Gnutella clients
implementing protocol
Peers form an abstract,
logical network, called
overlay network
Overlay network: graph
Edge between peer X
and Y if there’s a TCP
connection
All active peers and
edges is overlay
network
An edge is not a
physical communication
link, but an abstract link
Given peer will typically
be connected with < 10
overlay neighbors
Gnutella: Protocol
File transfer:
HTTP
Query message sent
over existing TCP
connections
Peers forward
Query message
QueryHit
sent over
reverse
path
Query
QueryHit
Query
QueryHit
Scalability:
limited scope
flooding
Gnutella: limited-scope query flooding
When an initial query message is sent out, a
peer-count field in the message is set to a
specific limit, e.g. 7.
Each time the query message reaches a new
peer,
the peer decrements the peer-count filed before
forwarding the query to its neighbors
A peer stops forwarding a query if the peer-
count field equals to zero
It is possible that a peer may not be able to
locate the content
Gnutella: Peer Joining
Joining peer X must find some other peers
Start with a list of candidate peers
X sequentially attempts TCP connections with candidate
peers on list until connection setup with Y
Flooding: X sends Ping message to Y
Ping message includes a peer-count field
Y forwards Ping message to his overlay neighbors until the
peer-count field is zero
All peers receiving Ping message respond with Pong
message
The pong message includes peer’s IP address.
X receives many Pong messages
X can then set up additional TCP connections with the peers
Gnutella: Pros and Cons
Advantages
Fully decentralized
Search cost distributed
Disadvantages
Search scope may be quite large
Search time may be quite long
High overhead, and nodes come and go often
Employed by the popular P2P client Limewire
Peer-to-Peer Networks: KaAzA
KaZaA history
2001: created by Dutch company (Kazaa BV)
First used by FastTrack, a P2P file-sharing protocol
which is used by other clients as well, including
Kazaa and Morpheus
Hierarchical Overlay
between centralized index, query
flooding approaches
each peer is either a group leader
(super peer) or assigned to a group
leader as an ordinary peer.
TCP connection between peer and its
group leader.
TCP connections between some
pairs of group leaders.
Super peer – higher bandwidth,
higher availabilities, greater
responsibilities
A super peer may have a few
hundred ordinary peer as children.
group leader tracks content in its
children
ordinary peer
group-leader peer
neighoring relationships
in overlay network
Peer-to-Peer Networks: KaAzA
Smart query flooding
Join: on start, the client contacts a super-node (and may
later become one)
Publish: client sends list of files to its super-node
Search:
• send query to super-node,
• the super-nodes flood queries among themselves
• Limited-scope flooding in the overlay networks of super
peers
Fetch:
• get file directly from peer(s);
• can fetch from multiple peers at once
P2P Case Study: BitTorrent (1)
BitTorrent history and motivation
2002: B. Cohen debuted BitTorrent
Key motivation: popular content
Focused on efficient fetching, not searching
• Distribute same file to many peers
• Single publisher, many downloaders
accounted for roughly 27% to 55% of all Internet
traffic (depending on geographical location) as of
February 2009. (Wiki)
Preventing free-riding
The collection of all peers participating in the
distribution of a particular file is called a torrent
BitTorrent: Simultaneous Downloading
Divide large file into many pieces
Replicate different pieces on different peers
A peer with a complete piece can trade with other
peers
Peer can (hopefully) assemble the entire file
Allows simultaneous downloading
Retrieving different parts of the file from different
peers at the same time
And uploading parts of the file to peers
Important for very large files
P2P Case Study: BitTorrent (1)
P2P file distribution
tracker: tracks peers
participating in torrent
obtain list
of peers
trading
chunks
peer
torrent: group of
peers exchanging
chunks of a file
BitTorrent: Tracker
Infrastructure node
Keeps track of peers participating in the torrent
Peers register with the tracker
Peer registers when it arrives
Peer periodically informs tracker it is still there
Tracker selects peers for downloading
Returns a random set of peers
Including their IP addresses
So the new peer knows who to contact for data
Peer connects to subset of peers (“neighbors”)
BitTorrent: Chunks
Large file divided into smaller pieces
Fixed-sized chunks
Typical chunk size of 256 Kbytes
When a peer joins the torrent, it has no chunks, but
will accumulate them over time
Allows simultaneous transfers
Downloading chunks from different neighbors
Uploading chunks to other neighbors
Learning what chunks your neighbors have
Periodically asking them for a list
File done when all chunks are downloaded
Once peer has entire file, it may (selfishly) leave or
(altruistically) remain as a seed
BitTorrent: Pulling Chunks
at any given time, different peers have
different subsets of file chunks
periodically, a peer (Alice) asks each
neighbor for list of chunks that they have.
Alice issues requests for her missing
chunks
Rarest first
BitTorrent: Chunk Request Order
Which chunks to request?
Could download in order
Like an HTTP client does
Problem: many peers have the early chunks
Peers have little to share with each other
Limiting the scalability of the system
Problem: eventually nobody has rare chunks
E.g., the chunks need the end of the file
Limiting the ability to complete a download
Solutions: random selection and rarest first
BitTorrent: Rarest Chunk First
Which chunks to request first?
The chunk with the fewest available copies
I.e., the rarest chunk first
Benefits to the peer
Avoid starvation when some peers depart
Benefits to the system
Avoid starvation across all peers wanting a file
Balance load by equalizing number of copies of
chunks
Free-Riding Problem in P2P Networks
Vast majority of users are free-riders
Most share no files and answer no queries
Others limit number of connections or upload
speed
A few “peers” essentially act as servers
A few individuals contributing to the public good
Making them hubs that basically act as a server
BitTorrent prevent free riding
Allow the fastest peers to download from you
Occasionally let some free riders download
Bit-Torrent: Preventing Free-Riding
Peer has limited upload bandwidth
And must share it among multiple peers
Prioritizing the upload bandwidth:
gives priority to the neighbors that are currently supplying
her data at the highest rate.
Rewarding the top four neighbors
continuously measures the rate at which it receives the bits
Reciprocates by sending to the top four peers
Recompute and reallocate top four peers every 10 seconds
Optimistic unchoking
Randomly try a new neighbor every 30 seconds
So new neighbor has a chance to be a better partner
newly chosen peer may join top 4