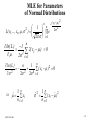Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Chapter 2: Basics from Probability Theory
and Statistics
2.1 Probability Theory
Events, Probabilities, Random Variables, Distributions, Moments
Generating Functions, Deviation Bounds, Limit Theorems
Basics from Information Theory
2.2 Statistical Inference: Sampling and Estimation
Moment Estimation, Confidence Intervals
Parameter Estimation, Maximum Likelihood, EM Iteration
2.3 Statistical Inference: Hypothesis Testing and Regression
Statistical Tests, p-Values, Chi-Square Test
Linear and Logistic Regression
mostly following L. Wasserman, with additions from other sources
IRDM WS 2005
2-1
2.2 Statistical Inference:
Sampling and Estimation
A statistical model is a set of distributions (or regression functions),
e.g., all unimodal, smooth distributions.
A parametric model is a set that is completely described by
a finite number of parameters,
(e.g., the family of Normal distributions).
Statistical inference: given a sample X1, ..., Xn how do we
infer the distribution or its parameters within a given model.
For multivariate models with one specific „outcome (response)“
variable Y, this is called prediction or regression,
for discrete outcome variable also classification.
r(x) = E[Y | X=x] is called the regression function.
IRDM WS 2005
2-2
Statistical Estimators
A point estimator for a parameter of a prob. distribution is a
random variable X derived from a random sample X1, ..., Xn.
Examples:
1 n
Sample mean:
X : X i
n i 1
1 n
2
2
Sample variance:
S :
( X i X )
n 1 i 1
An estimator T for parameter is unbiased
if E [ T ] ;
otherwise the estimator has bias E[ T ] .
An estimator on a sample of size n is consistent
if
limn P[ T ] 1 for each 0
Sample mean and sample variance
are unbiased, consistent estimators with minimal variance.
IRDM WS 2005
2-3
Estimator Error
Let ̂n = T() be an estimator for parameter over sample X1, ..., Xn.
The distribution of ̂n is called the sampling distribution.
The standard error for ̂n is: se( ˆ ) Var[ ˆ ]
The mean squared error (MSE) for ̂n is:
MSE( ˆ ) E[( ˆ )2 ]
n
bias 2 ( ˆn ) Var[ ˆn ]
If bias 0 and se 0 then the estimator is consistent.
The estimator ̂n is asymptotically Normal if
( ˆn ) / se converges in distribution to standard Normal N(0,1)
IRDM WS 2005
2-4
Nonparametric Estimation
The empirical distribution function F̂n is the cdf that
puts prob. mass 1/n at each data point Xi: F̂ ( x ) 1 n I( X x )
n
i
n i 1
A statistical functional T(F) is any function of F,
e.g., mean, variance, skewness, median, quantiles, correlation
The plug-in estimator of = T(F) is: ˆn T( Fˆn )
Instead of the full empirical distribution, often compact data synopses
may be used, such as histograms where X1, ..., Xn are grouped into
m cells (buckets) c1, ..., cm with bucket boundaries lb(ci) and ub(ci) s.t.
lb(c1) = , ub(cm) = , ub(ci) = lb(ci+1) for 1i<m, and
freq(ci) = F̂n ( x ) 1 n I( lb( ci ) X ub( ci ))
n 1
Histograms provide a (discontinuous) density estimator.
IRDM WS 2005
2-5
Parametric Inference: Method of Moments
Compute sample moments: ˆ n
1 n
j
X
n i 1 i
for j-th moment j
Estimate parameter by method-of-moments estimator ̂n s.t.
( F( ˆ )) ˆ
1
n
1
and
2( F( ˆn )) ˆ 2
and
3( F( ˆn )) ˆ 3
and
...
(for some number of moments)
Method-of-moments estimators are usually consistent and
asympotically Normal, but may be biased
IRDM WS 2005
2-6
Parametric Inference:
Maximum Likelihood Estimators (MLE)
Estimate parameter of a postulated distribution f(,x) such that
the probability that the data of the sample are generated by
this distribution is maximized.
Maximum likelihood estimation:
Maximize L(x1,...,xn, ) = P[x1, ..., xn originate from f(,x)]
(often written as
L( | x1,...,xn) = f(x1,...,xn | ) )
or maximize log L
if analytically untractable use numerical iteration methods
IRDM WS 2005
2-7
MLE Properties
Maximum Likelihood Estimators are
consistent, asymptotically Normal, and
asymptotically optimal in the following sense:
Consider two estimators U and T which are asymptotically Normal.
Let u2 and t2 denote the variances of the two Normal distributions
to which U and T converge in probability.
The asymptotic relative efficiency of U to T is ARE(U,T) = t2/u2 .
Theorem: For an MLE ̂n and any other estimator n
the following inequality holds:
ARE( ,ˆ ) 1
n
IRDM WS 2005
n
2-8
Simple Example for
Maximum Likelihood Estimator
given:
• coin with Bernoulli distribution with
unknown parameter p für head, 1-p for tail
• sample (data): k times head with n coin tosses
needed: maximum likelihood estimation of p
Let L(k, n, p) = P[sample is generated from distr. with param. p]
n k
p (1 p) n k
k
Maximize log-likelihood function log L (k, n, p):
n
log L log k log p (n k) log (1 p)
k
k
log L k n k
p
0
n
p
p 1 p
IRDM WS 2005
2-9
Advanced Example for
Maximum Likelihood Estimator
given:
• Poisson distribution with parameter (expectation)
• sample (data): numbers x1, ..., xn N0
needed: maximum likelihood estimation of
Let r be the largest among these numbers,
and let f0, ..., fr be the absolute frequencies of numbers 0, ..., r.
fi
i
r
L( x1 ,..., xn , ) e
i!
i 0
r
ln L
i
fi 1 0
i 0
r
̂
i fi
i r0
fi
1 n
xi x
n i 1
i 0
IRDM WS 2005
2-10
Sophisticated Example for
Maximum Likelihood Estimator
given:
• discrete uniform distribution over [1,] N0 and density f(x) = 1/
• sample (data): numbers x1, ..., xn N0
MLE for is max{x1, ..., xn } (see Wasserman p. 124)
IRDM WS 2005
2-11
MLE for Parameters
of Normal Distributions
1
2
L( x1 ,..., xn , , )
2
n
n
e
i 1
( xi )2
2 2
ln( L )
1 n
2( xi ) 0
2
2 i 1
ln( L )
2
n
2 2
1 n
ˆ xi
n i 1
IRDM WS 2005
1
n
( xi )2 0
2 4 i 1
1 n
ˆ ( xi ˆ )2
n i 1
2
2-12
Bayesian Viewpoint of Parameter Estimation
• assume prior distribution f() of parameter
• choose statistical model (generative model) f(x | )
that reflects our beliefs about RV X
• given RVs X1, ..., Xn for observed data,
the posterior distribution is f( | x1, ..., xn)
for X1=x1, ..., Xn=xn the likelihood is
n
n f ( | xi ) ' f ( xi | ') f ( ')
L(x1, ..., xn | ) i 1 f ( xi | ) i 1
f ( )
which implies
f ( | x1 ,...,xn ) ~ L( x1 ,...,xn | ) f ( ) (posterior is proportional to
likelihood times prior)
MAP estimator (maximum a posteriori):
compute that maximizes f( | x1, …, xn) given a prior for
IRDM WS 2005
2-13
Analytically Non-tractable MLE for parameters
of Multivariate Normal Mixture
consider samples from a mixture of multivariate Normal distributions
with the density (e.g. height and weight of males and females):
f ( x, 1 ,..., k , 1 ,..., k , 1 ,..., k )
k
k
j n( x , j , j ) j
j 1
j 1
1
(2 ) m j
1
( x j )T j1 ( x j )
e 2
with expectation values j
and invertible, positive definite, symmetric
mm covariance matrices j
maximize log-likelihood function:
n
n
k
log L( x1,..., xn , ) : log P[ xi | ] log j n( xi , j , j )
i 1
j 1
i 1
2-14
IRDM WS 2005
Expectation-Maximization Method (EM)
Key idea:
when L(, X1, ..., Xn) (where the Xi and are possibly multivariate)
is analytically intractable then
• introduce latent (hidden, invisible, missing) random variable(s) Z
such that
• the joint distribution J(X1, ..., Xn, Z, ) of the „complete“ data
is tractable (often with Z actually being Z1, ..., Zn)
• derive the incomplete-data likelihood L(, X1, ..., Xn) by
integrating (marginalization) J:
ˆ arg max z J [ ,X 1 ,...,X n ,Z | Z z ]P[ Z z ]
IRDM WS 2005
2-15
EM Procedure
Initialization: choose start estimate for (0)
Iterate (t=0, 1, …) until convergence:
E step (expectation):
estimate posterior probability of Z: P[Z | X1, …, Xn, (t)]
assuming were known and equal to previous estimate (t),
and compute EZ | X1, …, Xn, (t) [log J(X1, …, Xn, Z | )]
by integrating over values for Z
M step (maximization, MLE step):
Estimate (t+1) by maximizing
EZ | X1, …, Xn, (t) [log J(X1, …, Xn, Z | )]
convergence is guaranteed
(because the E step computes a lower bound of the true L function,
and the M step yields monotonically non-decreasing likelihood),
but may result in local maximum of log-likelihood function
IRDM WS 2005
2-16
EM Example for Multivariate Normal Mixture
Expectation step (E step):
hij : P[ Zij 1| xi ,
(t )
P[ xi | n j (
(t)
] k
)]
(t)
P[
x
|
n
(
)]
i l
l 1
Zij = 1
if ith data point
was generated
by jth component,
0 otherwise
Maximization step (M step):
n
hij xi
j : i n1
hij
n
T
h
(
x
)(
x
)
ij i j i j
j : i 1
n
hij
i 1
n
j :
hij
i 1
k n
hij
n
hij
i 1
( t 1)
i 1
n
j 1i 1
IRDM WS 2005
2-17
Confidence Intervals
Estimator T for an interval for parameter such that
P[ T a T a ] 1
[T-a, T+a] is the confidence interval and 1- is the confidence level.
For the distribution of random variable X a value
x (0< <1) with P[ X x ] P[ X x ] 1
is called a quantile; the 0.5 quantile is called the median.
For the normal distribution N(0,1) the quantile is denoted .
IRDM WS 2005
2-18
Confidence Intervals for Expectations (1)
Let x1, ..., xn be a sample from a distribution with unknown
expectation and known variance 2.
For sufficiently large n the sample mean X is N(,2/n) distributed
and ( X ) n is N(0,1) distributed:
( X ) n
P[ z
z ] ( z ) ( z ) ( z ) ( 1 ( z ))
z
z
P[ X
X
]
n
n
P[ X
1 / 2
X
1 / 2
n
n
For required confidence interval
z :
a n
then look up (z)
IRDM WS 2005
] 1
[ X a, X a ]
or
or confidence level 1- set
z : ( 1
2
) quantile of N ( 0,1 )
z
then a :
n
2-19
Confidence Intervals for Expectations (2)
Let x1, ..., xn be a sample from a distribution with unknown
expectation and unknown variance 2 and sample variance S2 .
For sufficiently large n the random variable
T :
( X ) n
S
has a t distribution (Student distribution)
with n-1 degrees of freedom:
n 1
2
fT ,n ( t )
n
2
1
n 1
t2 2
n 1
n
with the Gamma function:
( x ) e t t x 1 dt für x 0
0
( with the properties ( 1 ) 1 and ( x 1 ) x ( x ) )
P[ X
t n1,1 / 2 S
n
IRDM WS 2005
X
t n1,1 / 2 S
] 1
n
2-20
Normal Distribution Table
IRDM WS 2005
2-21
Student‘s t Distribution Table
IRDM WS 2005
2-22
2.3 Statistical Inference:
Hypothesis Testing and Regression
Hypothesis testing:
• aims to falsify some hypothesis by lack of statistical evidence
• design of test RV and its (approximate / limit) distribution
Regression:
• aims to estimate joint distribution of input and output RVs
based on some model and usually minimizing quadratic error
IRDM WS 2005
2-23
Statistical Hypothesis Testing
A hypothesis test determines a probability 1-
(test level , significance level) that a sample X1, ..., Xn
from some unknown probability distribution has a certain property.
Examples:
1) The sample originates from a normal distribution.
2) Under the assumption of a normal distribution
the sample originates from a N(, 2) distribution.
3) Two random variables are independent.
4) Two random variables are identically distributed.
5) Parameter of a Poisson distribution from which the sample stems has value 5.
6) Parameter p of a Bernoulli distribution from which the sample stems has value 0.5.
General form:
null hypothesis H0 vs. alternative hypothesis H1
needs test variable X (derived from X1, ..., Xn, H0, H1) and
test region R with
Retain H0
Reject H0
XR for rejecting H0 and
H0 true
type I error
XR for retaining H0
H1 true type II error
IRDM WS 2005
2-24
Hypotheses and p-Values
A hypothesis of the form = 0 is called a simple hypothesis.
A hypothesis of the form > 0 or < 0 is called composite hypothesis.
A test of the form H0: = 0 vs. H1: 0 is called a two-sided test.
A test of the form H0: 0 vs. H1: > 0 or H0: 0 vs. H1: < 0
is called a one-sided test.
Suppose that for every level (0,1) there is a test
with rejection region R. Then the p-value is the smallest level
at which we can reject H0: p-value inf{ |T( X 1 ,...,X n ) R
small p-value means strong evidence against H0
IRDM WS 2005
2-25
Hypothesis Testing Example
Null hypothesis for n coin tosses: coin is fair or has
head probability p = p0; alternative hypothesis: p p0
Test variable: X, the #heads, is
N(pn, p(1-p)n2) distributed (by the Central Limit Theorem),
X /n p
thus
is N(0, 1) distributed
Z :
p(1 p)
Rejection of null hypothesis at test level (e.g. 0.05) if
Z 1 / 2 Z / 2
IRDM WS 2005
2-26
Wald Test
ˆ 0
for testing H0: = 0 vs. H1: 0 use the test variable W
se( ˆ )
with sample estimate ̂ and standard error se( ˆ ) Var[ ˆ ]
W converges in probability to N(0,1)
reject H0 at level when |W| > / 2
IRDM WS 2005
2-27
Chi-Square Distribution
Let X1, ..., Xn be independent, N(0,1) distributed random variables.
Then the random variable n2 : X 12 ... X n2
is chi-square distributed with n degrees of freedom:
f
2( x)
n
n2
x 2
n
22
e
x
2
for x 0, 0 otherwise
n
2
Let n be a natural number, let X be N(0,1) distributed and
Y 2 distributed with n degrees of freedom.
X
Then the random variable Tn : n
Y
is t distributed with n degrees of freedom.
IRDM WS 2005
2-28
Chi-Square Goodness-of-Fit-Test
Given:
n sample values X1, ..., Xn of random variable X
with relative frequencies H1, ..., Hk for k value classes vi
(e.g. value intervals) of random variable X
Null hypothesis:
the values Xi are f distributed (e.g. uniformly distributed),
where f has expectation and variance 2
( H i E (vi ) 2
Approach: Yk : ( H i E (vi )) n / and Z k :
E (vi )
i 1
i 1
k
k
with E(vi) := n P[X is in class vi according to f ]
are both approximately 2 distributed with k-1 degrees of freedom
2
Z
Rejection of null hypothesis at test level (e.g. 0.05) if k
k 1,1
IRDM WS 2005
2-29
Chi-Square Independence Test
Given:
n samples of two random variables X, Y or, equivalently,
a twodimensional random variable
with (absolute) frequencies H11, ..., Hrc for r*c value classes,
where X has r and Y has c distinct classes.
(This is called a contingency table.)
Null hypothesis:
X und Y are independent; then the
expectations for the relative frequencies of the value classes would be
Eij
Ri C j
n
c
r
j 1
i 1
with Ri : H ij and C j : H ij
r
c ( H E )2
ij
ij
Approach: Z :
is approximately 2 distributed
Eij
i 1 j 1
with (r-1)(c-1) degrees of freedom
Rejection of null hypothesis at test level (e.g. 0.05) if
Z (2r 1 )( c1 ), 1
IRDM WS 2005
2-30
Chi-Square Distribution Table
IRDM WS 2005
2-31
Chi-Square Distribution Table
IRDM WS 2005
2-32
Linear Regression
(often used for parameter fitting of models)
Estimate r(x) = E[Y | X1=x1 ... Xm=xm] using a linear model
m
Y r( x ) 0 i 1 i xi
with error with E[]=0
given n sample points (x1(i) , ..., xm(i), y(i)), i=1..n, the
least-squares estimator (LSE) minimizes the quadratic error:
2
(i)
(i)
k xk y : E( 0 ,..., m )
i 1..n k 0..m
(with xo(i)=1)
E
Solve linear equation system: 0 for k=0, ..., m
k
equivalent to MLE ( X T X )1 X T Y
with Y = (y(1) ... y(n))T and
IRDM WS 2005
1 x( 1 )
1
1 x( 2 )
X 1
...
(n)
1 x
1
(1)
x2( 1 ) ... xm
(2)
x2( 2 ) ... xm
( n )
x2( n ) ... xm
2-33
Logistic Regression
Estimate r(x) = E[Y | X=x] using a logistic model
Y r( x )
e
0 im1 i xi
0 im1 i xi
1 e
with error with E[]=0
solution for MLE for i values based on numerical methods
IRDM WS 2005
2-34
Additional Literature for Chapter 2
• Manning / Schütze: Chapters 2 und 6
• Duda / Hart / Stork: Appendix A
• R. Nelson: Probability, Stochastic Processes, and Queueing Theory,
Springer, 1995
• M. Mitzenmacher, E. Upfal: Probability and Computing,
Cambridge University Press, 2005
• M. Greiner, G. Tinhofer: Stochastik für Studienanfänger der Informatik,
Carl Hanser Verlag, 1996
• G. Hübner: Stochastik, Vieweg, 1996
• Sean Borman: The Expectation Maximization Algorithm:
A Short Tutorial, http://www.seanborman.com/publications/EM_algorithm.pdf
• Jason Rennie: A Short Tutorial on Using Expectation-Maximization
with Mixture Models, http://people.csail.mit.edu/jrennie/writing/mixtureEM.pdf
IRDM WS 2005
2-35