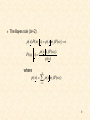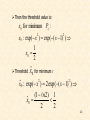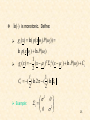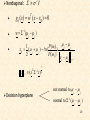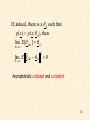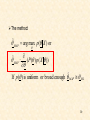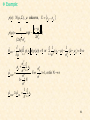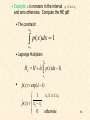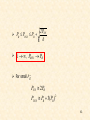Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Sergios Theodoridis
Konstantinos Koutroumbas
Version 2
1
PATTERN RECOGNITION
Typical application areas
Machine vision
Character recognition (OCR)
Computer aided diagnosis
Speech recognition
Face recognition
Biometrics
Image Data Base retrieval
Data mining
Bionformatics
The task: Assign unknown objects – patterns – into the correct
class. This is known as classification.
2
Features: These are measurable quantities obtained from
the patterns, and the classification task is based on their
respective values.
Feature vectors: A number of features
x1 ,..., xl ,
constitute the feature vector
T
l
x x1 ,..., xl R
Feature vectors are treated as random vectors.
3
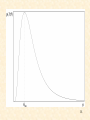
An example:
4
The classifier consists of a set of functions, whose values,
computed at x , determine the class to which the
corresponding pattern belongs
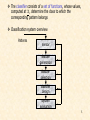
Classification system overview
Patterns
sensor
feature
generation
feature
selection
classifier
design
system
evaluation
5
Supervised – unsupervised pattern recognition:
The two major directions
Supervised: Patterns whose class is known a-priori
are used for training.
Unsupervised: The number of classes is (in general)
unknown and no training patterns are available.
6
CLASSIFIERS BASED ON BAYES DECISION
THEORY
Statistical nature of feature vectors
x x1 , x2 ,..., xl
T
Assign the pattern represented by feature vector
to the most probable of the available classes
x
1 , 2 ,...,M
That is
x i : P(i x)
maximum
7
Computation of a-posteriori probabilities
Assume known
• a-priori probabilities
P(1 ), P(2 )..., P(M )
•
p( x i ), i 1,2...M
This is also known as the likelihood of
x w.r. to i .
8
The Bayes rule (Μ=2)
p ( x) P(i x) p ( x i ) P(i )
P(i x)
where
p ( x i ) P(i )
p ( x)
2
p ( x) p ( x i ) P(i )
i 1
9
The Bayes classification rule (for two classes M=2)
Given x classify it according to the rule
If P(1 x ) P(2 x ) x 1
If P(2 x ) P(1 x ) x 2
Equivalently: classify
x
according to the rule
p( x 1 ) P(1 )() p( x 2 ) P(2 )
For equiprobable classes the test becomes
p( x 1 )() P( x 2 )
10
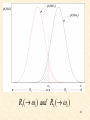
R1 ( 1 ) and R2 ( 2 )
11
Equivalently in words: Divide space in two regions
If x R1 x in 1
If x R2 x in 2
Probability of error
Total shaded area
P
e
x0
x0
p
(
x
)
dx
p
(
x
)
dx
2
1
Bayesian classifier is OPTIMAL with respect to
minimising the classification error probability!!!!
12
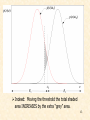
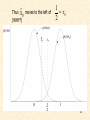
Indeed: Moving the threshold the total shaded
area INCREASES by the extra “grey” area.
13
The Bayes classification rule for many (M>2) classes:
Given
x
classify it to i if:
P(i x) P( j x) j i
Such a choice also minimizes the classification error
probability
Minimizing the average risk
For each wrong decision, a penalty term is assigned since
some decisions are more sensitive than others
14
For M=2
• Define the loss matrix
11 12
L(
)
21 22
•
12 penalty term for deciding class 2
,
although the pattern belongs to 1 , etc.
Risk with respect to
1
r1 11 p( x 1 )d x 12 p( x 1 )d x
R1
R2
15
Risk with respect to
2
r2 21 p( x 2 )d x 22 p( x 2 )d x
R1
R2
Probabilities of wrong decisions,
weighted by the penalty terms
Average risk
r r1P(1 ) r2 P(2 )
16
Choose R1 and R2 so that r is minimized
i if
1 11 p( x 1 ) P(1 ) 21 p( x 2 ) P(2 )
Then assign
x
to
2 12 p( x 1 ) P(1 ) 22 p( x 2 ) P(2 )
Equivalently:
assign x in 1 (2 )
if
p ( x 1 )
P(2 ) 21 22
12
()
p ( x 2 )
P(1 ) 12 11
12
: likelihood ratio
17
If
1
P(1 ) P(2 ) and 11 22 0
2
21
x 1 if P( x 1 ) P( x 2 )
12
12
x 2 if P( x 2 ) P( x 1 )
21
if 21 12 Minimum classifica tion
error probabilit y
18
An example:
p( x 1 )
1
p( x 2 )
1
exp( x 2 )
exp( ( x 1) 2 )
1
P(1 ) P(2 )
2
0 0.5
L
1.0 0
19
Then the threshold value is:
x0 for minimum Pe :
x0 : exp( x ) exp( ( x 1) )
2
2
1
x0
2
Threshold
x̂0 for minimum r
xˆ0 : exp ( x 2 ) 2 exp (( x 1) 2 )
(1 n2) 1
xˆ0
2
2
20
Thus x̂0 moves to the left of
(WHY?)
1
x0
2
21
DISCRIMINANT FUNCTIONS
DECISION SURFACES
If Ri , R j are contiguous:
g ( x) P(i x) P( j x) 0
Ri : P(i x) P( j x)
+
-
g ( x) 0
R j : P( j x) P(i x)
is the surface separating the regions. On one side is
positive (+), on the other is negative (-). It is known
as Decision Surface
22
If f(.) monotonic, the rule remains the same if we use:
x i if : f (P(i x)) f (P( j x)) i j
gi ( x) f ( P(i x))
is a discriminant function
In general, discriminant functions can be defined
independent of the Bayesian rule. They lead to
suboptimal solutions, yet if chosen appropriately, can be
computationally more tractable.
23
BAYESIAN CLASSIFIER FOR NORMAL
DISTRIBUTIONS
Multivariate Gaussian pdf
p ( x i )
1
2
(2 ) i
1
2
1
exp ( x i ) i1 ( x i )
2
i E x matrix in i
i E ( x i )( x i )
called covariance matrix
24
ln( ) is monotonic. Define:
g i ( x) ln( p( x i ) P(i ))
ln p( x i ) ln P(i )
1
T 1
g i ( x) ( x i ) i ( x i ) ln P (i ) Ci
2
1
Ci ( ) ln 2 ( ) ln i
2
2
Example:
2 0
i
2
0
25
g i ( x)
1
2 2
1
2
2
(x x )
2
1
2
2
1
2
( i1 x1 i 2 x2 )
( i21 i22 ) ln( Pi ) Ci
That is,
is quadratic and the surfaces
g i ( x) g j ( x) 0
g i (x)
quadrics, ellipsoids, parabolas, hyperbolas,
pairs of lines.
For example:
26
Decision Hyperplanes
x x
T
Quadratic terms:
1
i
If ALL Σ i Σ (the same) the quadratic
terms are not of interest. They are not
involved in comparisons. Then, equivalently,
we can write:
g i ( x) w x wio
T
i
wi Σ i
1
1 Τ 1
wi 0 ln P(i ) i Σ i
2
Discriminant functions are LINEAR
27
Let in addition:
•
Σ 2 I . Then
g i ( x)
•
1
2
i x wi 0
T
g ij ( x) g i ( x) g j ( x) 0
w ( x xo )
T
•
w i j,
•
P (i ) i j
1
2
x o ( i j ) ln
2
2
P( j )
i
j
28
Nondiagonal:
2
•
gij ( x) w ( x x 0 ) 0
•
w ( i j )
•
T
1
i j
P(i )
1
x 0 ( i j ) n (
)
2
P( j ) 2
i
j 1
x
( x 1 x)
T
1
Decision hyperplane
1
2
not normal to i j
normal to 1 ( i j )
29
Minimum Distance Classifiers
1
P (i )
M
equiprobable
1
g i ( x) ( x i )T 1 ( x i )
2
2 I : Assign x i :
Euclidean Distance:
smaller
dE x i
2 I : Assign x i :
Mahalanobis Distance:
smaller
d m (( x i ) ( x i ))
T
1
30
1
2
31
Example:
Given 1 , 2 : P(1 ) P(2 ) and p( x 1 ) N ( 1 , Σ ),
0
3
1.1 0.3
p( x 2 ) N ( 2 , Σ ), 1 , 2 ,
0
3
0
.
3
1
.
9
1.0
classify t he vector x using Bayesian classifica tion :
2.2
0.95 0.15
Σ
0
.
15
0
.
55
Compute Mahalanobi s d m from 1 , 2 : d 2 m,1 1.0, 2.2
-1
1.0
2
1 2.0
Σ 2.952, d m, 2 2.0, 0.8
3.672
2.2
0.8
1
Classify x 1. Observe that d E ,2 d E ,1
32
ESTIMATION OF UNKNOWN PROBABILITY
DENSITY FUNCTIONS
Maximum Likelihood
Let x , x ,...., x known and independen t
1
2
N
Let p( x) known with in an unknown ve ctor
parameter : p( x) p( x; )
X x1 , x 2 ,...x N
p( X ; ) p( x1 , x 2 ,...x N ; )
N
p ( x k ; )
k 1
which is known as the Likelihood of w.r. to X
The method :
33
Ν
ˆ ML : arg max p ( x k ; )
k 1
N
L( ) ln p ( X ; ) ln p ( x k ; )
k 1
N
p ( x k ; )
L
(
)
1
ˆ
0
ML :
( ) k 1 p ( x k ; ) ( )
34
35
If, indeed, there is a 0 such that
p( x) p( x; 0 ), then
lim E[ ML ] 0
N
lim E ˆ ML 0
N
2
0
Asymptotically unbiased and consistent
36
Example:
p ( x) : N ( , Σ ) : unknown,
x1 , x 2 ,..., x N p ( x k ) p ( x k ; )
1 N
L( ) ln p ( x k ; ) C ( x k )T Σ 1 ( x k )
k 1
2 k 1
1
1
T
1
p( x k ; )
exp(
(
x
)
Σ
( x k ))
k
l
1
2
2
2
(2 ) Σ
N
L
1
.
N
N
L( )
1
1
. Σ ( x k ) 0 ML x k
( )
k 1
N k 1
.
L
l
( A )
T
Remember : if A A
2 A
T
37
Maximum Aposteriori Probability Estimation
In ML method, θ was considered as a parameter
Here we shall look at θ as a random vector
described by a pdf p(θ), assumed to be known
Given
X x1 , x 2 ,..., x N
Compute the maximum of
p( X )
From Bayes theorem
p( ) p( X ) p( X ) p( X ) or
p( X )
p( ) p( X )
p( X )
38
The method:
ˆ MAP arg max p( X ) or
ˆ
( P( ) p ( X ))
MAP :
If p ( ) is uniform or broad enough ˆ MAP ML
39
40
Example:
p( x) : N ( , Σ ), unknown, X x1,...,x N
p( )
1
l
2
(2 ) l
exp(
0
2
2
2
)
N
N 1
1
MAP :
ln( p( x k ) p( )) 0 or 2 ( x k ) 2 ( ˆ 0 ) 0
k 1
k 1
2 N
2
0 2 xk
k 1
ˆ MAP
For
1, or for N
2
2
1 2 N
1 N
ˆ MAP ˆ ML x k
N k 1
41
Bayesian Inference
ML, MAP a single estimate for .
Here a different root is followed.
Given : X {x1 ,..., x N }, p ( x ) and p ( )
The goal : estimate p( x X )
How??
42
p( x X ) p( x ) p( X )d
p( X ) p( )
p( X ) p( )
p( X )
p( X )
p( X ) p( )d
N
p( X )
p( x k )
k 1
A bit more insight vi a an example
Let p ( x ) N ( , 2 )
p ( ) N ( 0 , 02 )
It turns out that : p ( X ) N ( N , N2 )
N 02 x 2 0
N
,
2
2
N 0
2 02
,
2
2
N 0
2
N
1
x
N
N
x
k 1
43
k
The above is a sequence of Gaussians as N
Maximum Entropy
Entropy H
p( x) ln
p( x)d x
pˆ ( x) : maximum H subject to the
available constraint s
44
Example: x is nonzero in the interval x1 x x2
and zero otherwise. Compute the ME pdf
• The constraint:
x2
p( x)dx 1
x1
• Lagrange Multipliers
x2
H L H ( p( x)dx 1)
x1
•
pˆ ( x) exp( 1)
x1 x x2
1
ˆp( x) x2 x1
0
otherwise
45
Mixture Models
J
p( x) p( x j ) Pj
j 1
M
P
j 1
j
1, p( x j )d x 1
x
Assume parametric modeling, i.e.,
The goal is to estimate
given a set
X
p( x j ; )
and P1 , P2 ,..., Pj
x1 , x 2 ,..., x N
Why not ML? As before?
N
max P( x k ; , Pi ,..., Pj )
, Pi ,..., Pj k 1
46
This is a nonlinear problem due to the missing
label information. This is a typical problem with
an incomplete data set.
The Expectation-Maximisation (EM) algorithm.
• General formulation
m
y
the
complete
data
set
y
Y
R
, with p y ( y; ) ,
–
which are not observed directly.
We observe
x g ( y) X ob R , l m with Px ( x; ),
l
a many to one transformation
47
• Let
Y ( x) Y all y ' s to a specific x
p x ( x; )
p
y
( y; ) d y
Y ( x)
• What we need is to compute
ˆML :
k
ln( p y ( y k ; ))
0
• But yk ' s
are not observed. Here comes the
EM. Maximize the expectation of the loglikelihood
conditioned on the observed samples and the
current iteration estimate of .
48
The algorithm:
• E-step:
Q( ; (t )) E[ ln( p y ( y k ; X ; (t ))]
k
• M-step:
Q( ; (t ))
(t 1) :
0
Application to the mixture modeling problem
• Complete data
( x k , jk ), k 1,2,..., N
x k , k 1,2,..., N
• Observed data
•
p( x k , jk ; ) p( x jk ; ) Pjk
k
• Assuming mutual independence
N
L( ) ln( p ( x k jk ; ) Pjk )
k 1
49
• Unknown parameters
[ , P ] , P [ P1 , P2 ,..., Pj ]T
T
T
• E-step
T T
N
N
k 1
k 1
Q(; (t )) E[ ln( p( x k jk ; ) Pjk )] E[
N
J
k 1
jk 1
• M-step
P( j x k ; (t ))
]
P ( jk x k ;(t )) ln ( p( x k jk ; ) P jk )
Q
0
p( x k j; (t )) Pj
P( x k ; (t ))
Q
0,
Pjk
jk 1,2,..., J
J
p( x k ; (t )) p( x k j; (t )) Pj
j 1
50
Nonparametric Estimation
k N in h
N total
1 kN
h
pˆ ( x) pˆ ( xˆ )
, x - xˆ
h N
2
kN
P
N
If p( x) continuous
hN 0,
h
x̂
2
x̂
h
x̂
2
, pˆ ( x) p( x) as N , if
k N ,
kN
0
N
51
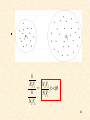
Parzen Windows
Divide the multidimensional space in hypercubes
52
Define
1
1
xij
( xi )
2
0 otherwise
• That is, it is 1 inside a unit side hypercube centered
at 0
1 1
ˆ
• p( x) l (
h N
•
xi x
(
))
h
i 1
N
1
1
* * number of points inside
volume N
an h - side hypercube centered at x
• The problem:
p ( x) continuous
(.) discontinu ous
• Parzen windows-kernels-potential functions
( x) is smooth
( x) 0, ( x)d x 1
x
53
Mean value
1 1
E[ pˆ ( x)] l (
h N
N
E[ (
i 1
xi x
1
x' x
)]) l (
) p ( x' )d x'
h
h
h
x'
1
• h 0, l
h
x' x
)0
• h 0 the width of (
h
1
x ' x
)d x 1
• l (
h
h
1
x
• h 0 l ( ) ( x)
h
h
E[ pˆ ( x)] ( x' x) p( x' )d x' p( x)
x'
Hence unbiased in the limit
54
Variance
• The smaller the h the higher the variance
h=0.1, N=1000
h=0.8, N=1000
55
h=0.1, N=10000
The higher the N the better the accuracy
56
If
• h0
• N
• hΝ
asymptotically unbiased
The method
• Remember:
p ( x 1 )
P (2 ) 21 22
l12
()
p( x 2 )
P (1 ) 12 11
•
1
N1h l
1
N 2 hl
xi x
(
)
h
i 1
()
N2
xi x
(
)
h
i 1
N1
57
CURSE OF DIMENSIONALITY
In all the methods, so far, we saw that the highest
the number of points, N, the better the resulting
estimate.
If in the one-dimensional space an interval, filled
with N points, is adequately (for good estimation), in
the two-dimensional space the corresponding square
will require N2 and in the ℓ-dimensional space the ℓdimensional cube will require Nℓ points.
The exponential increase in the number of necessary
points in known as the curse of dimensionality. This
is a major problem one is confronted with in high
dimensional spaces.
58
NAIVE – BAYES CLASSIFIER
Let x and the goal is to estimate px | i
i = 1, 2, …, M. For a “good” estimate of the pdf
one would need, say, Nℓ points.
Assume x1, x2 ,…, xℓ mutually independent. Then:
px | i px j | i
j 1
In this case, one would require, roughly, N points
for each pdf. Thus, a number of points of the
order N·ℓ would suffice.
It turns out that the Naïve – Bayes classifier
works reasonably well even in cases that violate
the independence assumption.
59
K Nearest Neighbor Density Estimation
In Parzen:
• The volume is constant
• The number of points in the volume is varying
Now:
• Keep the number of points
constant
kN k
• Leave the volume to be varying
k
ˆ ( x)
•p
NV ( x)
60
•
k
N 2V2
N1V1
()
k
N1V1
N 2V2
61
The Nearest Neighbor Rule
Choose k out of the N training vectors, identify the k
nearest ones to x
Out of these k identify ki that belong to class ωi
Assign
x i : ki k j i j
The simplest version
k=1 !!!
For large N this is not bad. It can be shown that:
if PB is the optimal Bayesian error probability, then:
PB PNN
M
PB (2
PB ) 2 PB
M 1
62
PB PkNN
2 PNN
PB
k
k , PkNN PB
For small PB:
PNN 2 PB
P3 NN PB 3( PB ) 2
63
Voronoi tesselation
Ri x : d ( x, x i ) d ( x, x j ) i j
64
BAYESIAN NETWORKS
Bayes Probability Chain Rule
p( x1 , x2 ,..., x ) p( x | x 1 ,..., x1 ) p( x 1 | x 2 ,..., x1 ) ...
... p( x2 | x1 ) p( x1 )
Assume now that the conditional dependence for
each xi is limited to a subset of the features
appearing in each of the product terms. That is:
p( x1 , x2 ,..., x ) p( x1 ) p( xi | Ai )
i 2
where
Ai xi 1 , xi 2 ,..., x1
65
For example, if ℓ=6, then we could assume:
p( x6 | x5 ,..., x1 ) p( x6 | x5 , x4 )
Then:
A6 x5 , x4 x5 ,..., x1
The above is a generalization of the Naïve – Bayes.
For the Naïve – Bayes the assumption is:
Ai = Ø, for i=1, 2, …, ℓ
66
A graphical way to portray conditional dependencies
is given below
According to this figure we
have that:
• x6 is conditionally dependent on
x4, x5.
• x5 on x4
• x4 on x1, x2
• x3 on x2
• x1, x2 are conditionally
independent on other variables.
For this case:
p( x1 , x2 ,..., x6 ) p( x6 | x5 , x4 ) p( x5 | x4 ) p( x3 | x2 ) p( x2 ) p( x1 )
67
Bayesian Networks
Definition: A Bayesian Network is a directed acyclic
graph (DAG) where the nodes correspond to random
variables. Each node is associated with a set of
conditional probabilities (densities), p(xi|Ai), where xi
is the variable associated with the node and Ai is the
set of its parents in the graph.
A Bayesian Network is specified by:
• The marginal probabilities of its root nodes.
• The conditional probabilities of the non-root nodes,
given their parents, for ALL possible combinations.
68
The figure below is an example of a Bayesian
Network corresponding to a paradigm from the
medical applications field.
This Bayesian network
models conditional
dependencies for an
example concerning
smokers (S),
tendencies to develop
cancer (C) and heart
disease (H), together
with variables
corresponding to heart
(H1, H2) and cancer
(C1, C2) medical tests.
69
Once a DAG has been constructed, the joint
probability can be obtained by multiplying the
marginal (root nodes) and the conditional (non-root
nodes) probabilities.
Training: Once a topology is given, probabilities are
estimated via the training data set. There are also
methods that learn the topology.
Probability Inference: This is the most common task
that Bayesian networks help us to solve efficiently.
Given the values of some of the variables in the
graph, known as evidence, the goal is to compute
the conditional probabilities for some of the other
variables, given the evidence.
70
Example: Consider the Bayesian network of the
figure:
a) If x is measured to be x=1 (x1), compute
P(w=0|x=1) [P(w0|x1)].
b) If w is measured to be w=1 (w1) compute
P(x=0|w=1) [ P(x0|w1)].
71
For a), a set of calculations are required that
propagate from node x to node w. It turns out that
P(w0|x1) = 0.63.
For b), the propagation is reversed in direction. It
turns out that P(x0|w1) = 0.4.
In general, the required inference information is
computed via a combined process of “message
passing” among the nodes of the DAG.
Complexity:
For singly connected graphs, message passing
algorithms amount to a complexity linear in the
number of nodes.
72