Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
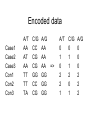
Genome-wide association studies Usman Roshan SNP • Single nucleotide polymorphism • Specific position and specific chromosome SNP genotype Suppose this is the DNA on chromosome 1 starting from position 1. There is a SNP C/G on position 5, C/T on position 14, and G/T on position 21. This person is heterozygous in the first SNP and homozygous in the other two. F: AACACAATTAGTACAATTATGAC M: AACAGAATTAGTACAATTATGAC SNP genotype representation The example F: M: AACACAATTAGTACAATTATGAC AACAGAATTAGTACAATTATGAC is represented as CG CC GG … SNP genotype • For several individuals A/T C/T G/T … H0: AA TT GG … H1: AT CC GT … H2: AA CT GT … . . . SNP genotype encoding • If SNP is A/B (alphabetically ordered) then count number of times we see B. • Previous example becomes A/T C/T G/T … A/T C/T G/T H0: AA TT GG … 0 2 0 H1: AT CC GT … =>1 0 1 H2: AA CT GT … 0 1 1 Now we have data in numerical format … … … … Genome wide association studies (GWAS) • Aim to identify which regions (or SNPs) in the genome are associated with disease or certain phenotype. • Design: – – – – – Identify population structure Select case subjects (those with disease) Select control subjects (healthy) Genotype a million SNPs for each subject Determine which SNP is associated. Example GWAS Case 1 Case 2 Case 3 Control 1 Control 2 Control 3 A/T AA AT AA TT TT TA C/G CC CG CG GG CC CG A/G … AA AA AA GG GG GG Encoded data Case1 Case2 Case3 Con1 Con2 Con3 A/T AA AT AA TT TT TA C/G CC CG CG GG CC CG A/G AA AA AA => GG GG GG A/T 0 1 0 2 2 1 C/G 0 1 1 2 0 1 A/G 0 0 0 2 2 2 Ranking SNPs Case1 Case2 Case3 Con1 Con2 Con3 SNP1 A/T AA AT AA TT TT TA SNP2 C/G CC CG CG GG CC CG SNP3 A/G AA AA AA => GG GG GG SNP1 A/T 0 1 0 2 2 1 SNP2 C/G 0 1 1 2 0 1 A good ranking strategy would produce SNP3, SNP1, SNP2 SNP3 A/G 0 0 0 2 2 2 Chi-square test • Gold standard is the univariate nonparametric chi-square test with two degrees of freedom. • Search for SNPs that deviate from the independence assumption. • Rank SNPs by p-values Statistical test of association (P-values) • P-value = probability of the observed data (or worse) under the null hypothesis • Example: – Suppose we are given a series of coin-tosses – We feel that a biased coin produced the tosses – We can ask the following question: what is the probability that a fair coin produced the tosses? – If this probability is very small then we can say there is a small chance that a fair coin produced the observed tosses. – In this example the null hypothesis is the fair coin and the alternative hypothesis is the biased coin Binomial distribution • Bernoulli random variable: – Two outcomes: success of failure – Example: coin toss • Binomial random variable: – Number of successes in a series of independent Bernoulli trials • Example: – – – – – Probability of heads=0.5 Given four coin tosses what is the probability of three heads? Possible outcomes: HHHT, HHTH HTHH, HHHT Each outcome has probability = 0.5^4 Total probability = 4 * 0.5^4 Binomial distribution • Bernoulli trial probability of success=p, probability of failure = 1-p • Given n independent Bernoulli trials what is the probability of k successes? æ nö k n-k p (1p) ç ÷ èkø • Binomial applet: http://www.stat.tamu.edu/~west/applets/binomialdemo.html Hypothesis testing under Binomial hypothesis • Null hypothesis: fair coin (probability of heads = probability of tails = 0.5) • Data: HHHHTHTHHHHHHHTHTHTH • P-value under null hypothesis = probability that #heads >= 15 • This probability is 0.021 • Since it is below 0.05 we can reject the null hypothesis Chi-square statistic • Define four random variables Xi each of which is binomially distributed Xi ~ B(n, pi) where n=c1+c2+c3+c4 is the total number of subjects and pi is the probability of success of Xi. • Each variable Xi represents the number of case and control subjects with number of risk and wildtype alleles. • The expected value E(Xi) = npi since each Xi is binomial. #Allele1 (risk) #Allele2 (wildtype) Case c1 (X1) c2 (X2) Control c3 (X3) c4 (X4) Chi-square statistic n 2 (c e ) 2 i i c = å Define the statistic: ei i=1 where ci = observed frequency for ith outcome ei = expected frequency for ith outcome n = total outcomes The probability distribution of this statistic is given by the chi-square distribution with n-1 degrees of freedom. Proof can be found at http://ocw.mit.edu/NR/rdonlyres/Mathematics/18-443Fall2003/4226DF27-A1D0-4BB8-939A-B2A4167B5480/0/lec23.pdf Great. But how do we use this to get a SNP p-value? Null hypothesis for case control contingency table • We have two random variables: – – • • Null hypothesis: the two variables are independent of each other (unrelated) Under independence – – – • • • P(D,G)= P(D)P(G) P(D=case) = (c1+c2)/n P(G=risk) = (c1+c3)/n Expected values – #Allele1 (risk) #Allele2 (wildtype) Case c1 c2 Control c3 c4 D: disease status G: allele type. E(X1) = P(D=case)P(G=risk)n We can calculate the chi-square statistic for a given SNP and the probability that it is independent of disease status (using the pvalue). SNPs with very small probabilities deviate significantly from the independence assumption and therefore considered important. Chi-square statistic exercise • Compute expected values and chi-square statistic • Compute chi-square p-value by referring to chi-square distribution #Allele1 #Allele2 Case 15 35 Control 2 48 GWAS problems and applications • Detect causal SNPs – Chi-square – Multivariate approaches • Predict case and control from genotypes – Machine learning algorithms – A simple algorithm based on Euclidean distances