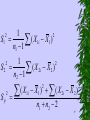Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Short Course in
Statistics
Learning Statistics through Computer
Notice that Microsoft Chinese
Windows is needed in some slides
1
Random Sampling
To obtain information through sampling
Population and Sample
Parameter and Statistic
2
Population versus
Sample
Population
– The entire group of
individuals about
which we want
information
Sample
– A part of the
population from
which we actually
collect information,
used to draw
conclusions about
the whole
population.
3
Example
Population = the
measurements of
weights of all
children under 18
Sample = the
measurements of
weights of students
in 20 secondary
and primary
schools
4
Parameter versus
Statistic
Parameter
– A number that
describes the
population.
Statistic
– A number that
describes a sample.
5
Drawing balls from a
box
A box contains 10 balls: 5 red, 5 black
Population: 10 balls
Parameter: proportion of red balls
Draw a random sample of size 3
Statistic: red balls in the sample
e.g. 2/3
6
Statistical Science
Statistics provides methodology to
estimate the parameter through the
(random) sample
7
How to draw a random
sample
Construct a sampling frame---give a
number (name) to each individual in
the population
Use “random number table” to draw a
random sample of prescribed size
8
Random Number Table
Imagine that a box containing 10
identical balls with numbers 0, 1, 2, 3,
4, 5, 6, 7, 8 and 9.
Each time you draw a ball and record
the number before returning it to the
box and draw the next ball --- this list
(record) is the “random number table”
9
Example
Objective---draw a sample of size 5
from a class of 30 students
Sampling frame---label each student
with the numbers 00, 01,…29.
Read the random number table at line
130 ---- 69051 64817 87174 09517
69 05 16 48 17 87 17 40 95 17
10
Multiple Label
00=30=60, 01=31=61, 02=32=62, etc.
Notice 01 will correspond to the
second individual
11
Measurements in the
Laboratory
Each measurement in the physics lab
or chemistry lab can be regarded as
an element in a random sample
12
http://www.cuhk.edu.hk/webct
User ID & Password
=STA2103(Surname)(Initials)
Go to the above website and learn sample
survey, design of experiment and regression
13
Henry,Chau,STA2103chauh
Ka Ho Enoch,Chan,STA2103chankhe
Jane,Tang,STA2103tangj
Vincent,Pong,STA2103pongv
Clara,Yip,STA2103yipc
14
Why Random Sampling
To be representative
Some laws governing the statistic--sampling distribution and compute the
Probability---the chance of the
occurrence of an event in n
independent samplings---can be
computed
15
Not representative
Call in
Voluntary response on the Web
Telephone survey asking the
respondents to respond with the
number keys
Readers’ letters to the newspaper
16
Sampling Distribution
Random sampling the statistic
would change as the sample varies
That is, the conclusion might be
changed for different sample
But, if the samples are randomly
drawn, we can predict the result with
high probability
17
Example
Population: Hong Kong adult residents
Sample (random): 600 persons
Parameter: proportion of the
population supporting one more public
holiday
Statistic; proportion in the sample
18
Consequence of
Random Sampling
If we draw 1000 samples (with each
sample of size 600), and we compute
the statistic for each sample, the
histogram of these 1000 (sample)
proportion is approximately a bellshaped curve---normal density
19
Normal and Probability
Normal density has 2 parameters:
Mean --- true proportion (p)
Variance ---var=p(1-p)/n
Standard deviation (std)=sqrt(var)
The one sample we draw has
probability .95 in the interval (p-1.96
std, p+1.96 std)
20
Mean of normal=true
parameter
If you draw a sample 1000 times, you
have 1000 sample proportions.
The average of these 1000 sample
proportions would be approximately
the true proportion --- sample
proportion is an unbiased estimate of
the population proportion
21
Variance=p(1-p)/n
If it is truly random, we can estimate
the variance of these 1000 sample
proportions using p (parameter) only.
If I have only one sample with accurate
estimate of p, then the variance of the
1000 sample proportion can be
computed without using the 1000
sample proportions
22
Intuition behind the
formula p(1-p)/n
Symmetric about ½
It is maximized by p=1/2 (very
uncertain)
When p is closer to 0 or 1, I.e., things
are more definite, the variance gets
smaller
23
Confidence Interval
Conversely, p will be covered by the
interval (p-1.96 std, p+1.96 std) 95
times out of 100 such experiments.
Notice std=sqrt(p(1-p)/n)
24
95% Confidence
Interval
Use the formula for 100 surveys, we
obtain 100 different interval estimates
95 out of these 100 intervals would
contain the true p
25
Opinion Polls
People may not give the true
response --- response error
People may not answer the
questions --- nonresponse error
– Unit nonresponse (the person does not
response at all)
– Item nonresponse (the person does not
respond to some questions)
26
Response rate
If the response rate is less than 80%,
we would doubt about the validity of
the inference
27
Election Polls
The respondent may not be voters
The respondent may not vote even
he/she has registered
The respondent may lie (response
error)
28
Questionnaire
The way to set questions would affect
the response (well-known)
29
Other Data Collection
Methods
Experimental Design
Observational Data (e.g. registry Data)
30
How to know the effect
of vaccine in
preventing polio
We cannot apply the vaccine to all
children and compare the results in the
past
We need two groups:
control group (no “real” treatment)
treatment group (apply the vaccine)
31
We should compare the
two groups under
“equal” conditions
People are different from each other
By random assignment of participants
into the two groups, we can make the
two groups have almost identical
conditions – e.g., around the same on
average
32
Design of an
Experiment
For comparing one treatment (A) with
the other treatment (B), we need to
randomize the patient into each group
receiving the one of the treatments
33
Some possible
mistakes
Data---from hospital record
Death rates of surgical patients are
different for operations with different
anesthetics
Halothane (1.7%), Pentothal (1.7%),
Cyclopropane (3.4%), Ether (1.9%)
Can we say that cyclopropane is more
dangerous than the other anesthetics?
34
Answer
No! the worst patients were receiving
cyclopropane.
35
The vaccine can
prevent Polio
1956---USA---over two million children
involved
Should they all receive vaccine?
Should the male receive vaccine while
the female receive placebo?
36
Placebo
In this case, placebo is another kind of
liquid, which is similar to the vaccine in
its outlook, injected into the children.
It is used so that all children were
receiving “same” treatment. So that
the difference in the results would not
be explained as psychological effect
37
Data
Polio (after
half year)
No polio (after
half year)
Control
(placebo)
A=115
B=201,114
treatment
C=33
D=200712
38
Analysis
The proportion of control group having
polio after ½ year --- a/(a+b)=0.00057
The proportion of treatment group
having polio after ½ year--c/(c+d)=0.00016
The effect of treatment---
– RD (risk difference)=c/(c+d) - a/(a+b)
=0.00041
39
Formulation of the
Hypotheses
Null Hypothesis: no difference in the
proportions
Alternative Hypothesis: the two
proportions are different
40
Analysis
We need to compare RD with its
variation
That is, if we have different
experiments, the results are different.
The variation of these results can be
measured by its variance.
But we have only one experiment
41
Estimate the variation
If there are no effect of the vaccine,
the true risk (probability) of getting
polio is pr=(a+c)/(a+b+c+d)=0.00037
Under above hypothesis, the variance
of RD is given by
pr(1-pr) / (1/(a+b)+1/(c+d))
The standard deviation is 0.000061.
42
Contd.
Thus the ratio 0.00041/0.000061=6.76
measures the effect of vaccine.
Is 6.76 indicates a large or small or no
effect?
We need a yardstick.
43
Intuition
Thus the ratio (RD/std) measures the
effect of the vaccine.
That is, if it is large in absolute value,
the effect of vaccine is significant
How large is large?
44
Random assignment of
patients to treatments
If we do the experiment 1000 times
and each time we calculate the ratio
We also assume that the effect of
vaccine is zero..
Then we plot the histogram of the
1000 ratios. We find the histogram is
close to a bell-shape curve---normal
density curve.
45
Normality
Since we know that the ratio is normal
and we now obtain 6.76.
We can compute the area to the right
of 6.76----the probability that the ratio
is larger than 6.76 under the
hypothesis of no effect. We find the
area is very small (6.9 x 10^{-12})
46
P value
The area correspond to the probability
of the event which is more extreme to
the observed value
The usual rule --- p-value <0.05 reject
the null hypothesis
0.05 can be interpreted as 5 wrong
conclusions among 100 experiments
47
Chi Square TestAnother approach
We can apply the chi square test to the
same data set.
The chi square test is used to test
whether the proportion of getting polio
is the same for the two groups
(homogeneity). Equivalently, whether
the occurrence of polio is independent
of the treatment (group)
48
Analysis
The chi square test statistic is given by
N(ad - bc)**2/((a+b)(a+c)(b+d)(c+d))
N=a+b+c+d
When the statistic is large, the
hypothesis is likely to be wrong
49
Statistical Reasoning
The above statistic can be expressed
as the summation of the quantities
(observed counts-expected counts)**2
divided by the expected counts
Here expected counts means the
average counts under the hypothesis
that the two groups are the same
50
Chi Square distribution
Chi square distribution with one
degree of freedom
P-value=0.05
Cutoff point 3.84 I.e., reject if the chi
square statistic is larger than 3.84.
Otherwise, accept the null hypothesis.
51
T-test (Two-Sample
unpaired)
Randomize female rats into two
groups (high (low) protein dies)
Response variables—gain in weight
between the 28th and 84th days of age
52
Data
High protein
134 146 104 119
124 161 107 83 113
129 97 123
– Mean=120
– Variance=457.5
Low protein
70 118 101 85 107
132 94
– Mean=101
– Variance=425.3
53
Hypotheses
Null hypothesis: no difference in the
two means
Alternative hypothesis: the means are
different
54
Analysis
The difference of the two means
=120 - 101=19
19 measures the difference in weight
gains between two groups
Is it large or small? By chance?
We need to compare with its standard
deviation
55
Variance and standard
deviation
Standard deviation=square root of
variance
S S
2
56
1
2
S1
( X 1i X 1 )
n1 1
2
S2
2
Sp
2
1
2
( X 2i X 2 )
n2 1
(X
X 1 ) ( X 2i X 2 )
2
1i
n1 n2 2
57
2
Indicator
X1 X 2
t
Sp
This is a better indicator of the
difference between the two
groups
58
Statistical reasoning
Indicator and yardstick
If we repeat the experiment 1000 times
and compute 1000 t statistics
Plot the histogram for these 1000 t
statistics
The histogram is similar to normal but
with heavier tails
59
Analysis
We call it a t distribution
There are many t distribution for
different sample sizes
The number (the sum of two group
sizes –2) is called the degree of
freedom of the t distribution
(e.g. 12+7-2=17)
60
DF>= 30
When the degrees of freedom is larger
than or equal to 30, the t distribution
would become a normal distribution
61
Statistical Reasoning
Given the degree of freedom, we can
find the area (probability)
If there are no difference between the
two groups, the t distribution would by
symmetric about zero.
If the data is really arising from two
treatments with same results, the t
statistic should be small
62
Statistical Reasoning
If the t-statistics is small, the area
(probability) of observing the actual
statistic or larger must be large.
Conversely, if the area is small, the
data tells us that the hypothesis is
likely to be wrong
63
Statistical Reasoning
In this case, t=1.89
The area for |t| beyond 1.89 (when
degree of freedom=17) is 0.076.
This area is called p-value
Usually, when p-value is lees than 0.05,
we will reject the hypothesis
64
1.
2.
Interactive Statistical Pages
Try the t-test ( go to the
procedure)and chi square test (2
x 2 table for sample comparison)
here.
65
Regression
Finding the mean of y for each x
To see whether x and y are
associated
66
Data
•
國家
•
澳洲
2.5
211
•
奧地利
3.9
167
•
比利時
2.9
131
•
加拿大
2.4
191
•
丹麥
2.9
220
•
芬蘭
0.8
297
•
法國
9.1
71
•
冰島
0.8
211
•
愛爾蘭
0.7
300
•
意大利
7.9
107
酒耗量 心臟病死亡率
國家 酒耗量
荷蘭
1.8
新西蘭
1.9
挪威
0.8
西班牙
6.5
瑞士
5.8
瑞典
1.6
英國
1.3
美國
1.2
西德
2.7
心臟病死亡率
167
266
227
86
115
207
285
199
172
67
散布圖的形狀表示: 酒耗量與心
臟病的死亡率成負相關的關係,
但只反映國家整體數據之間的
關係, 我們不能引申為每個人喝
酒愈多, 其死於心臟病的機會愈
少, 否則便犯上生態的偏差-----Ecologic bias.
1
2
3
4
5
6
7
8
9
68
嚴謹推算與應用分析
300
之間的取捨 !
250
200
150
100
50
69
嚴謹推算與應用分析
300
之間的取捨 !
250
200
150
100
50
70
Analysis
Y (death rate)= 260.56-22.97 x (Alcohol)
The negative sign indicates that Y and x
go in opposite direction.
More Alcohol, less heart disease death
rate?
The result cannot be extended to
individual level --- ecologic bias
71
Analysis
The variance of the error is given by
1434.79
If we compute the variance of Y, we
find that the variance is given by
4678.05.
72
Questions
Email address:
[email protected]
Telephone:
2609-7927
73
Exercises
1.(Sample survey)
Population=(Adults in Hong Kong)
Sample=(random sample, telephone
survey)
Parameter=proportion supporting the
government in handling the protest
Statistic=
74