Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Multiagent learning using a variable
learning rate
M. Bowling and M. Veloso.
Artificial Intelligence, Vol. 136, 2002, pp. 215 - 250.
Igor Kiselev, University of Waterloo
May 17
Agenda
Introduction
Motivation to multi-agent learning
MDP framework
Stochastic game framework
Reinforcement Learning: single-agent, multi-agent
Related work:
Multiagent learning with a variable learning rate
Theoretical analysis of the replicator dynamics
WoLF Incremental Gradient Ascent algorithm
WoLF Policy Hill Climbing algorithm
Results
Concluding remarks
University of Waterloo
Page 2
Introduction
Motivation to multi-agent learning
May 17
MAL is a Challenging and Interesting Task
Research goal is to enable an agent effectively learn to act (cooperate,
compete) in the presence of other learning agents in complex domains.
Equipping MAS with learning capabilities permits the agent to deal with
large, open, dynamic, and unpredictable environments
Multi-agent learning (MAL) is a challenging problem for developing
intelligent systems.
Multiagent environments are non-stationary, violating the traditional
assumption underlying single-agent learning
University of Waterloo
Page 4
Reinforcement Learning Papers: Statistics
2500
Reinforcement Learning Papers
Barto, Ernst,
Collins, Bowling
2000
1500
Singh
1000
Littman
500
Sutton
Wasserman
0
1963
University of Waterloo
1968
1973
1978
1983
1988
1993
Google Scholar
1998
2003
2008
Page 5
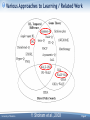
Various Approaches to Learning / Related Work
University of Waterloo
Y. Shoham et al., 2003
Page 6
Preliminaries
MDP and Stochastic Game Frameworks
May 17
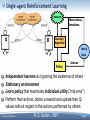
Single-agent Reinforcement Learning
Rewards
Observations,
Sensations
Learning
Algorithm
World,
State
Policy
Actions
Independent learners act ignoring the existence of others
Stationary environment
Learn policy that maximizes individual utility (“trial-error”)
Perform their actions, obtain a reward and update their Qvalues without regard to the actions performed by others
University of Waterloo
R. S. Sutton, 1997
Page 8
Markov Decision Processes / MDP Framework
...
st
at
rt +1
st +1
at +1
rt +2
st +2
at +2
rt +3 s
t +3
. . . rt +f = 0 s
t +f
at +3
at+f-1
Environment is a modeled as an MDP, defined by (S, A, R, T)
S – finite set of states of the environment
A(s) – set of actions possible in state sS
T: S×A → P – set transition function from state-action pairs to states
R(s,s',a) – expected reward on transition (s to s‘)
P(s,s',a) – probability of transition from s to s'
– discount rate for delayed reward
Each discrete time t = 0, 1, 2, . . . agent:
observes state StS
chooses action atA
receives immediate reward rt ,
state changes to St+1
University of Waterloo
T. M. Mitchell, 1997
Page 9
Agent’s learning task – find optimal action selection policy
Execute actions in environment, observe results, and
learn to construct an optimal action selection policy
that maximizes the agent's performance - the long-term
Total Discounted Reward
Find a policy s
S aA(s)
that maximizes the value (expected future reward) of each s :
V (s) = E {rt +1 + rt +2 + 2 rt +3 +
and each s,a pair:
s t =s, }
rewards
Q (s,a) = E {rt +1+ rt +2 + 2rt +3+
University of Waterloo
...
...
s t =s, a t=a, }
T. M. Mitchell, 1997
Page 10
Agent’s Learning Strategy – Q-Learning method
Q-function - iterative approximation of Q values with
learning rate β: 0≤ β<1
Q( s, a) (1 )Q( s, a) (r ( s, a) max Q( s' , aˆ ))
aˆ
Q-Learning incremental process
1. Observe the current state s
2. Select an action with probability based on the employed
selection policy
3. Observe the new state s′
4. Receive a reward r from the environment
5. Update the corresponding Q-value for action a and state s
6. Terminate the current trial if the new state s′ satisfies a
terminal condition; otherwise let s′→ s and go back to step 1
University of Waterloo
Page 11
Multi-agent Framework
Learning in multi-agent setting
all agents simultaneously learning
environment not stationary (other agents are evolving)
problem of a “moving target”
University of Waterloo
Page 12
Stochastic Game Framework for addressing MAL
From the perspective of sequential decision making:
Markov decision processes
one decision maker
multiple states
Repeated games
multiple decision makers
one state
Stochastic games (Markov games)
extension of MDPs to multiple decision makers
multiple states
University of Waterloo
Page 13
Stochastic Game / Notation
S: Set of states (n-agent stage games)
Ri(s,a): Reward to player i in state s under joint action a
T(s,a,s): Probability of transition from s to state s on a
s
a1
[
a2
R1(s,a), R2(s,a), …
T(s,a,s)
]
[]
[]
s
[]
From dynamic programming approach:
Qi(s,a): Long-run payoff to i from s on a then equilibrium
University of Waterloo
Page 14
Approach
Multiagent learning using a variable learning rate
May 17
Evaluation criteria for multi-agent learning
Use of convergence to NE is problematic:
Terminating criterion: Equilibrium identifies conditions under which
learning can or should stop
Easier to play in equilibrium as opposed to continued computation
Nash equilibrium strategy has no “prescriptive force”: say anything
prior to termination
Multiple potential equilibria
Opponent may not wish to play an equilibria
Calculating a Nash Equilibrium can be intractable for large games
New criteria: rationality and convergence in self-play
Converge to stationary policy: not necessarily Nash
Only terminates once best response to play of other agents is found
During self play, learning is only terminated in a stationary NE
University of Waterloo
Page 16
Contributions and Assumptions
Contributions:
Criterion for multi-agent learning algorithms
A simple Q-learning algorithm that can play mixed
strategies
The WoLF PHC (Win or Lose Fast Policy Hill Climber)
Assumptions - gets both properties given that:
The game is two-player, two-action
Players can observe each other’s mixed strategies
(not just the played action)
Can use infinitesimally small step sizes
University of Waterloo
Page 17
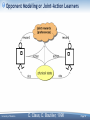
Opponent Modeling or Joint-Action Learners
University of Waterloo
C. Claus, C. Boutilier, 1998
Page 18
Joint-Action Learners Method
Maintains an explicit model of the opponents for each
state.
Q-values are maintained for all possible joint actions at
a given state
The key assumption is that the opponent is stationary
Thus, the model of the opponent is simply frequencies of
actions played in the past
Probability of playing action a-i:
where C(a−i) is the number of times the opponent has
played action a−i.
n(s) is the number of times state s has been visited.
University of Waterloo
Page 19
Opponent modeling FP-Q learning algorithm
University of Waterloo
Page 20
WoLF Principles
The idea is to use two different strategy update steps, one
for winning and another one for loosing situations
“Win or Learn Fast”: agent reduces its learning rate when
performing well, and increases when doing badly. Improves
convergence of IGA and policy hill-climbing
To distinguish between those situations, the player keeps track
of two policies.
Winning is considered if the expected utility of the actual policy
is greater than the expected utility of the equilibrium (or
average) policy.
If winning, the smaller of two strategy update steps is chosen
by the winning agent.
University of Waterloo
Page 21
Incremental Gradient Ascent Learners (IGA)
IGA:
incrementally climbs on the mixed strategy space
for 2-player 2-action general sum games
guarantees convergence to a Nash equilibrium or
guarantees convergence to an average payoff that is
sustained by some Nash equilibrium
WoLF IGA:
based on WoLF principle
converges guarantee to a Nash equilibrium for all 2
player 2 action general sum games
University of Waterloo
Page 22
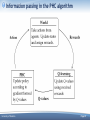
Information passing in the PHC algorithm
University of Waterloo
Page 23
Simple Q-Learner that plays mixed strategies
Updating a mixed
strategy by giving more
weight to the action that
Q-learning believes is
the best
Problems:
guarantees rationality against stationary opponents
does not converge in self-play
University of Waterloo
Page 24
WoLF Policy Hill Climbing algorithm
agent only need to see its
own payoff
converges for two player two
action SG’s in self-play
Maintaining average policy
Probability of playing action
Determination of “W” and “L”:
by comparing the expected
value of the current policy to
that of the average policy
University of Waterloo
Page 25
Theoretical analysis
Analysis of the replicator dynamics
May 17
Replicator Dynamics – Simplification Case
Best response dynamics for Paper-Rock-Scissors
Circular shift from one agent’s policy to the other’s average reward
University of Waterloo
Page 27
A winning strategy against PHC
Probability opponent plays heads
If winning
play probability 1 for
current preferred action
in order to maximize
rewards while winning
If losing
play a deceiving policy
until we are ready to take
advantage of them again
1
0.5
0
1
0.5
Probability we play heads
University of Waterloo
Page 28
Ideally we’d like to see this:
winning
losing
University of Waterloo
Page 29
Ideally we’d like to see this:
winning
University of Waterloo
losing
Page 30
Convergence dynamics of strategies
Iterated Gradient Ascent:
• Again does a myopic adaptation
to other players’ current strategy.
• Either converges to a Nash
fixed point on the boundary
(at least one pure strategy), or
get limit cycles
•Vary learning rates to be
optimal while satisfying both
properties
University of Waterloo
Page 31
Results
May 17
Experimental testbeds
Matrix Games
Matching pennies
Three-player matching pennies
Rock-paper-scissors
Gridworld
Soccer
University of Waterloo
Page 33
Matching pennies
University of Waterloo
Page 34
Rock-paper-scissors: PHC
University of Waterloo
Page 35
Rock-paper-scissors: WoLF PHC
University of Waterloo
Page 36
Summary and Conclusion
Criterion for multi-agent learning algorithms:
rationality and convergence
A simple Q-learning algorithm that can play
mixed strategies
The WoLF PHC (Win or Lose Fast Policy Hill
Climber) to satisfy rationality and convergence
University of Waterloo
Page 37
Disadvantages
Analysis for two-player, two-action games:
pseudoconvergence
Avoidance of exploitation
guaranteeing that the learner cannot be deceptively
exploited by another agent
Chang and Kaelbling (2001) demonstrated that the bestresponse learner
PHC (Bowling & Veloso, 2002) could be exploited by
a particular dynamic strategy.
University of Waterloo
Page 38
Pseudoconvergence
University of Waterloo
Page 39
Future Work by Authors
Exploring learning outside of self-play:
whether WoLF techniques can be exploited by a
malicious (not rational) “learner”.
Scaling to large problems:
combining single-agent scaling solutions (function
approximators and parameterized policies) with the
concepts of a variable learning rate and WoLF.
Online learning
List other algorithms of authors:
GIGA-WoLF, normal form games
University of Waterloo
Page 40
Discussion / Open Questions
Investigation other evaluation criteria:
No-regret criteria
Negative non-convergence regret (NNR)
Fast reaction (tracking) [Jensen]
Performance: maximum time for reaching a desired performance level
Incorporating more algorithms into testing: deeper comparison with
more simple and more complex algorithms (e.g. AWESOME [Conitzer
and Sandholm 2003])
Classification of situations (games) with various values of the delta
and alpha variables: what values are good in what situations.
Extending work to have more players.
Online learning and exploration policy in stochastic games (trade-off)
Currently the formalism is presented in two dimensional state-space:
possibility for extension of the formal model (geometrical ?)?
What does make Minimax-Q irrational?
Application of WoLF to multi-agent evolutionary algorithms (e.g. to
control the mutation rate) or to learning of neural networks (e.g. to
determine a winner neuron)?
Connection with control theory and learning of Complex Adaptive
Systems: manifold-adaptive learning?
University of Waterloo
Page 41
Questions
Thank you
May 17